システム奮闘記:その63
PostgreSQLのお勉強・その2
PostgreSQLのWALって何? ログ、PITR、障害時のデータ復旧の話
(2007年10月21日に掲載)
2001年にPostgreSQLと出会った私。
シーラカンス本を読んで、ちょこちょことPostgreSQLを使った
検索システム等を構築していったのだが、表面的な使い方しか知らなかった。
何度も「真剣に勉強せねば」と思った事があったのだが、
理解できる程の知識や技術がなかったため、勉強を行っても・・・
無念、討ち死になのらー! (-o-;;
の連続だった。
いわば頓挫してばかりで前に進む事ができなかったのだ。
それだけでない。思い込みだけで関心を持たなかったのもある。
WALも、そのうちの1つだった。
WALとは「Write Ahead Logging」(ログを先に書き出す)の略語だが・・・
なんでログって重要やねん?
だった。
つまり「データーベースの処理の記録」は、他のサーバーソフトのログと同様
動作が正しく動いているかなどの点検項目程度にしか認識していなかった (^^;;
そんな状態が長く続いていたのだった。
データベースのログ、WALとは
2007年3月に、ネット販売システムの再構築の話が出る。
今度こそはと思い、重い腰を上げてPostgreSQLの勉強する事にした。
まずは、トランザクション、ロック、VACUUMは勉強した。
詳しくは「システム奮闘記:その60」をご覧ください。
(PostgreSQL入門。トランザクション ロック VACUMM)
引き続き、以下の本を読んでいく事にした。
「RDBMS 解剖学」(鈴木幸市、藤塚勤也:翔泳社)
すると9章の「ログ機能によるパフォーマンスの向上」に出会った。
ここで思った。
なんでログが性能の向上につながるねん?
そして次のようにも思った。
普通、ログを書き出すと・・・
書き出し処理のため、性能が下がるんとちゃうか?
うーん、一休さんのトンチのような感じがする。
しかし、ここで悩んでも謎が解けるわけでないので、本を読み進める事にした。
ところで「RDBMS 解剖学」(鈴木幸市、藤塚勤也:翔泳社)は、
PostgreSQLだけに特定しない、一般的なデータベースに関する本なので、
しばらく、一般論の話が続きますので、PostgreSQLとは違う部分があっても
突っ込まないでくださいね (^^)
さて、データベースにおけるログとは何なのかを見てみる事にした。
ふと思った。「ログ」という言葉は、記録や履歴の意味で使われている。
しかし、実際に英和辞書で調べたわけではない。
まずは、ログ(Log)の意味を英和辞書で調べてみた。
| ログ(Log)の意味 |
|---|
丸太、丸木の意味がある。こんな意味があったとは知らなかった。
この時、丸太の家の事を「ログハウス」と呼ぶ理由がわかった。
(日本ログハウス協会) http://www.log-house.gr.jp/
ログには記録という意味も辞書には書いてあった。
「丸太」と「記録」とは何の関連性があるのか、わからない。
もしかしたら、データを記録する磁気テープは
丸太のように巻き付けているため「ログ」と
呼ぶようになった可能性はあると思うが、
詳しい事は、英語学者でないので、謎のままにしておく (^^)
|
(2007/11/11追加)
謎のまま終わってしまうと思ったが、10月22日、梅沢さんから
以下のメールをメールを頂きました。
| 梅沢さんから頂いたメール |
|---|
梅沢@私も事務職^^; です。
奮闘記、興味深く読ませていただきました。
> 私が書いています「システム奮闘記:その63」で
>PostgreSQLのWALログや、WALログを活用したデータの復旧、
>PITRについて取り上げてみましたので、お知らせします。
> http://www.osssme.com/
本筋には関係ありませんが、上記のページ中の
「ログには記録という意味も辞書には書いてあった。
「丸太」と「記録」とは何の関連性があるのか、わからない。」
についてなら、たまたま知っています。
昔々の話ですが。
羅針盤の発明によって、船の進行方向が正しく把握できるように
なって大航海時代時代に突入した訳ですが、船の速度を測る方法
はありませんでした。で、当時の船長は船首から丸太を海に投げ
入れ、それが船尾に達するまでの時間を測って航海日誌に記録し、
現在位置を推定していたのだそうです。
ここから、log に「丸太」→「記録」の意味が生まれたそうです。
因みに、ちょっと調べたところ
http://www5e.biglobe.ne.jp/~yotteman/logbook.htm
のII-11 を見ると今でも船の対水スピードをログと呼んでいるみ
たいですね。
でれでは。
|
一見、関連性のない言葉でも、由来を知ると「なるほど」と思う。
非常に勉強になりました。梅沢さん、ありがとうございます m(--)m
(閑話休題)
本にデータベースのログに、どんな情報が載っているのか書いてあった。
| データベースのログの内容 |
|---|
| (1) |
トランザクションの開始 |
| (2) |
トランザクションの終了 |
| (3) |
トランザクション内でのデータの変更などの情報 |
この説明を見て、データベースのログは、データベース上で行った
操作内容を記録している事だとわかった。
さて、なぜログが重要なのか。
もちろん・・・・
そんなのわかりませーん (^^)
なので、本を読み進める。
本にはデータベースの高速化を実現させるためだと書いてあった。
Linuxに限らず、Windowsなど一般的なパソコンOSの仕組みで
ファイルの更新があった場合、更新の度に、ハードディスクに
書き込んでいるわけではない。
| ファイルを更新すると、一旦、メモリ上に保管される |
|---|
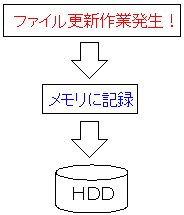 |
ファイルを更新すると、内容はメモリ上に保管される。
そして、時間をおいて、まとめてハードディスクに書き込む。
ハードディスクへの書き込み速度が遅いため、ファイルの更新の度に
ハードディスクに書き込んでいては、OSの性能が落ちるからだ。
そのため、ファイルの作成、更新があっても、すぐにはハードディスクには
反映させずに、後からまとめて反映させる。
つまり、まとめて反映させる事で、ハードディスクへの接続回数を減らし
それによって、ファイルの操作の高速化を実現させているのだ。
|
さて、データベースの場合も同様の事が言える。
| もし、更新の度にハードディスクに反映させていると |
|---|
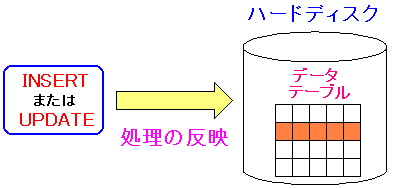 |
データベース上で、INSERTやUPDATEでレコードの追加や更新が
行われる度に、ハードディスクに更新を反映させていると、
書き込みに時間がかかるため、データベースの性能が落ちる。
|
なので、高速化を実現させるため、以下の工夫をしている。
| 操作したいテーブルはメモリ上に読み込む |
|---|
 |
操作したいテーブルがあると、それをハードディスクから
メモリに読み込み、メモリ上でテーブルを操作できるようにする。
|
高速でデータのやりとりができるメモリ上にテーブルを置く事で
データベースの操作中は、高速メモリ上にあるテーブルに更新内容を
反映させる事で、データベースの高速化をはかっている。
| メモリ上に読み込んだテーブルに更新内容を反映させる |
|---|
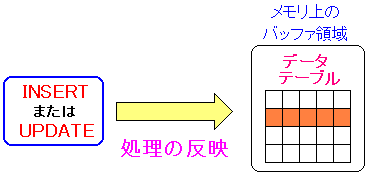 |
レコードの追加・更新がある度にメモリ上に読み込んだのテーブルに
内容を反映させる事で、データベースの処理の高速化を実現させている。
そしてある程度、更新された時、まとめてハードディスクに反映させている。
|
PostgreSQLを触って6年経つのだが、データベースにそんな機能があったとは
全く知らへんかった (^^;;
だった。
本を読み進める。
トランザクション処理中の「INSERT」(追加)や「UPDATE」(更新)で
メモリ上に読み込んだテーブルに反映させている事が書いてあった。
| トランザクション処理中の「INSERT」や「UPDATE」の扱い |
|---|
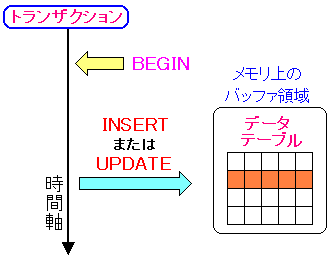 |
トランザクション処理中に、レコードの追加・更新が発生すると、
メモリ上に読み込んだテーブルに反映される。
ただ、PostgreSQLの場合、追記型データベースなので、更新の場合、
メモリ上のレコードの書き換えではなく、メモリ上のレコードに
更新レコードを追加していると思われる。
追記型については「システム奮闘記:その60」をご覧ください。
(PostgreSLQ入門。トランザクション ロック VACUUM)
|
ところで、トランザクション処理中の時点では、INSERT(追加)や
UPDATE(更新)が行われても、追加や更新が確定ではない。
なので、トランザクションの処理中に停電などがシステムが落ち、
データベースに処理内容が反映されなくても、処理確定ではないため、
反映されない事自体は問題ではない。
もちろん、データベースが止まると業務的には大問題だけど・・・ (^^;;
トランザクション中の処理は「COMMIT」をして、初めてレコードの追加や
更新が確定される。
そして、本にはこんな事が書いてあった。
「COMMIT」をした後は、データベースの追加や更新が確定なので
何が何でも確定した物を守らなければならない!
つまり下の図の場合の時が問題だという。
| 「COMMIT」をした後は、どーするの? |
|---|
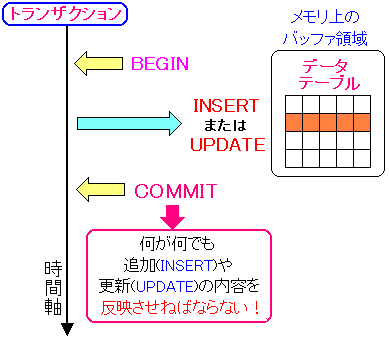 |
トランザクションの正常終了(COMMIT)を行うと、
トランザクション中に行われた処理は確定となる。
だが、メモリ上に読み込んだデータベースだけ反映させるだけで
ハードディスクにあるテーブル(データの実体)を反映させないと
もし、COMMITした後で、停電等が起こり、システムがダウンすると
メモリ上のデータが全部吹き飛んで、確定したはずの内容が
全く反映されない問題が起こる。
|
単純に考えれば、「COMMIT」を行ったすぐ後に、ハードディスクに
処理内容を反映させれば、処理内容の確定ができる。
だが、そんなに世の中、甘くはないのだ。
| COMMITのすぐ後にハードディスクに反映させると・・・ |
|---|
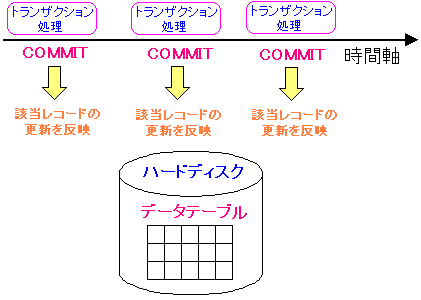 |
COMMITを行う度に、すぐ後にハードディスクへ反映させると、
ハードディスクへのデータ書き込みで時間がかかるため、
データベースの性能が落ちる問題が発生する。
データベースは、高速で安全にデータの出し入れする箱なので
性能が落ちる仕掛けにするわけにはいかないようだ。
|
そこで性能を落とさないために、データベースのログが活躍するというのだ。
データベースのログは、前述しました通り、以下の内容の記録だ。
| データベースのログの内容 |
|---|
| (1) |
トランザクションの開始 |
| (2) |
トランザクションの終了 |
| (3) |
トランザクション内でのデータの変更などの情報 |
データベースの処理を行うための「手続き情報」なのだ。
その手続き情報は、データベースのログなのだ。
| データベースのログだけ先にハードディスクに書き込む |
|---|
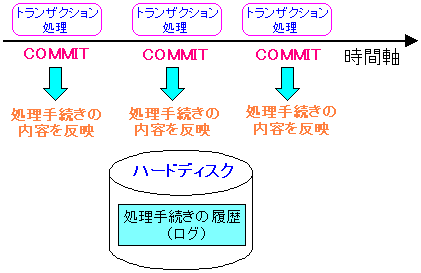 |
データベースのログ(更新・更新等の手続き情報)を、
COMMITがある度に書き込み事で、例え、COMMITの後に
停電が起こった場合、テーブルデータの内容が反映されていなくても
更新処理の手続き情報(ログ)を記録できているため、COMMIT後の
データベースへの更新等の反映情報を守る事ができる。
ログをハードディスクへ書き込むのだが、ログのデータが大きいと
高速化の意味が損なわれるため、できるだけ小さい形にして
ハードディスクへの書き込み時間を減らし、高速化を保つようにしている。
|
このように、処理の手続き情報(ログ)を先にハードディスクに書き出す事を
WAL
というのだ。
WALとは「Write Ahead Logging」(ログを先に書き出す)の略語だ。
ここで「WAL」の意味を初めて理解できた。
つまりデータベースのテーブルの追加・更新処理を確定させた物を守るために
先にログを書き出す事の意味だ。
PostgreSQLの本や資料などで「WAL」という文字を何度も見てきたが
ようやく意味が理解できた (^^)
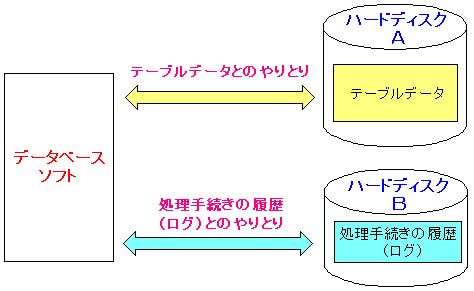
この時、データベース内に格納されているデータは
テーブルデータ以外に、テーブルデータの追加・更新等の
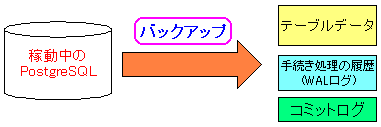
処理手続きの内容を記録した履歴(ログ)がある事を知った。
| ハードディスクには2種類のデータが入っている |
|---|
 |
だが、この時、2種類のデータがある事に対して
へぇ〜。そうなん。
という程度の認識しかなかった。
即ち、データベースの障害復旧にログが大きな威力を発揮する事を
全く気づいていなかった。
まだ、WALに対しての理解が浅かったのだ。
WALの真骨頂とも言うべき、データベースの障害復旧については、
後述しています♪
データテーブルとログを分ける理由
さて、データベースには、データが格納されているデータテーブルと
データの更新等の際の、処理手続きの記録(ログ:履歴)の2種類がある事を知った。
| ハードディスクには2種類のデータが入っている |
|---|
|
さて、本を読み進めると、2種類のデータが同じハードディスクにある場合
ハードディスクへの書き出し処理に時間がかかるというのだ。
| 2種類のデータが同じハードディスクにある場合 |
|---|
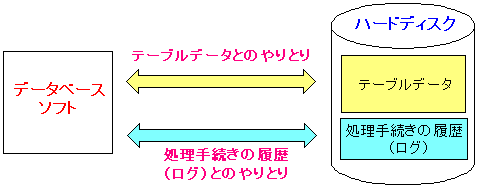 |
一体、どういう事なのだろうか。
本には以下の理由が書いてあった。
2種類のデータは、ハードディスクの同じトラックや、近隣のトラックに
データが保管されているとは限らない。
以下のように、全く違うセクタに保管されている事もある。
| 全く別のセクタに保管されている事もある |
|---|
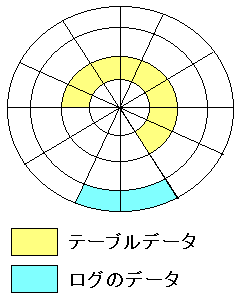 |
データベースは、ハードディスクへの接続を向上させるため
テーブルデータは同じトラックや近隣のトラックに固めている。
だが、テーブルデータと、ログは特にそういう事はしていないようで
全く違うトラック上に保管している事もある。
|
全く違うトラック上に保管していると、テーブルデータの書き出し後に
ログの書き出しを行うと、アームの移動時間が発生する。
| アームの移動時間が発生する |
|---|
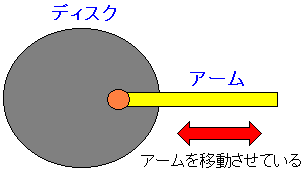 |
ハードディスクに記録されたデータを読み込むには、
データが保管されているトラックの位置までアームを移動させる必要がある。
この移動時間(シーク時間)が高速化の妨げになっているというのだ。
|
そこで、アームを移動させる時間(シーク時間)を無駄にしないため、
2つのデータを別々のハードディスクに保管するという方法がある。
| 2つのデータを別々のハードディスクに保管する |
|---|
 |
これによって、2つのデータの書き出し処理が起こっても、
別々のハードディスクに書き込まれるため、シーク時間の発生がなくなる。
これによってデータベースの性能向上がはかれるという。
|
この話を知って
こんな事、全く思いもつかへんかった (^^;;
だった。
ハードディスクのセクタ、トラック、シーク時間などについては
「システム奮闘記:その31」をご覧ください。
だが、他にも、2つのデータ(テーブルデータとログ)を別々のハードディスクに
保管させる利点がある。
| 2つのデータを同じハードディスクに保管した場合 |
|---|
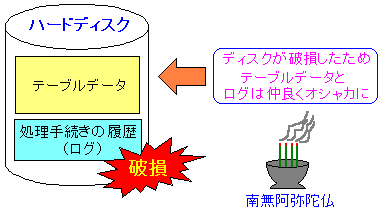 |
もし、ハードディスクが破損したら、2種類のデータとも
オシャカになってしまう。
そうなれば、データの保全うんぬんの問題ではなくなる。
|
でも、2つのデータを別々のハードディスクに保管すれば
以下のような利点がある。
| 2つのデータを別々のハードディスクに保管する |
|---|
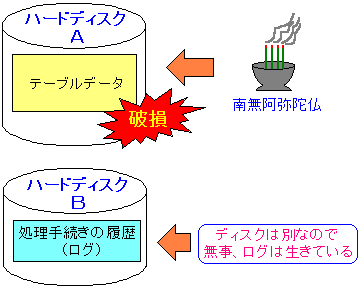 |
例え、テーブルデータが保管されたハードディスクが破損して
テーブルデータがオシャカになっても、ログのデータは無事なので
更新処理の手続きの情報は残る。
そして、データベースの障害復旧の話で後述している事だが、
もし、ログが生きていれば、データベースのデータの中身を
バックアップ時点から破損寸前まで復旧が可能になる。
|
そう、データの保全性の面からも、2種類のデータを別々の
ハードディスクに保管させた方が良いというのだ。
| 余談 |
|---|
上の図で線香の絵を載せてみた。
一応、私の家は浄土真宗なので、仏教式の葬式になる。
なので、お経も浄土真宗の「南無阿弥陀仏」を添えた。
浄土真宗は、坊さんが結婚しようが、肉を食べようが良い上
檀家や信者も「南無阿弥陀仏」と唱えれば、
救われるという非常に楽な宗教だ。
仏教は、元々、輪廻転生という思想を根幹としているため
殺生は認められていない。
だが、浄土真宗では、肉食が良いので、
必要な殺生は認められているのだ。
なので、システムのプロセスを止めるのに、
何のためらいもなく、killコマンドを使ったりして
プロセスを殺す事ができるのだ (^^)
|
| 実はお釈迦さんは肉を食べていた(2008/6/11追加) |
仏教は肉食を禁じているが、創始者であるお釈迦さんは
肉を食べていた話がある。
お釈迦さんが亡くなった原因は食中毒と言われているが、
それは托鉢で頂いた肉で食あたりしたと言われている。
お釈迦さんが亡くなった後、輪廻転生などの思想から
肉食が禁止になった話がある。真相は歴史の闇の中だ (^^)
|
本を読み進める。この章は「ログによる障害からの復旧」だ。
データベースの障害には4種類あるという。
| データベースの障害の種類 |
|---|
| (1) |
インスタント障害 |
| (2) |
メディア障害 |
| (3) |
アプリケーション障害 |
| (4) |
データ入力誤り |
これを見て・・・
インスタンスって何やねん!
だった。本には、どんな障害なのかが書いてあった。
| インスタンス障害とは何か |
|---|
何らかの原因で、データベースシステムが動作不能になり
処理途中で異常終了してしまう状況を指す。
原因として、データベースそのものやOSのバグ、障害、
コンピューター自身の電源障害による停止
|
つまり、何からの原因によって、いきなり異常停止する事態の事だ。
せやけど、それだけでは・・・
インスタンスの意味がわからへん (TT)
なのだ。
年々、カタカナ用語を素直に受け入れられなくなっている。
大抵の場合、用語には意味があるのだが、カタカナになった瞬間、
意味の部分が削ぎ落とされた形になるため、無味乾燥で丸暗記になる。
丸暗記が大の苦手な私は、少しでも覚えやすくするため、
本来の意味を調べてみたくなる。
インスタンスは「instance」のようだ。
| instanceの意味 |
|---|
英和辞典を見ると「事実」とか「例」、「実例」という意味だ。
でも、それだけでは用語と、その意味とが結び付かない。
そこで英々辞典を調べてみるが同じだった。
そこでgoogleを使って「instance database trouble」の用語で
調べてみる事にした。
いくつかOracleやSQLServerなどの文章を眺めて、
「instance」の意味の推測をしたのだが・・・
全くわからへん・・・(TT)
だった (--;;
|
八方塞がりになった。
こんな時は、次にように叫びたくなる。
イザナギ、イザナミがお産みになった神国・日本に
カタカナを持ち込むな!!
これで、気持ちをすっきりさせた (^^)
という事で「インスタンス」の意味は謎のまま、次に進みます。
さて、データベースを動かしている際、テーブルの内容を追加・更新しても
すぐにハードディスクには反映されない事を前述しました。
| テーブルのレコードに追加・更新があると |
|---|
|
レコードの追加・更新があっても、すぐにはハードディスクには
反映されない。
メモリ上に読み込んだデータテーブルに反映される。
|
もし、ハードディスクに書き込みを行う前に、電源障害などで
データベースが落ちてしまったら、メモリ上のデータは消えるため、
折角の追加・更新の処理が反映されない事態が起こる。
以下の図のような事態が起こってしまうのだ。
| 障害発生によりデータベースが落ちてしまうと |
|---|
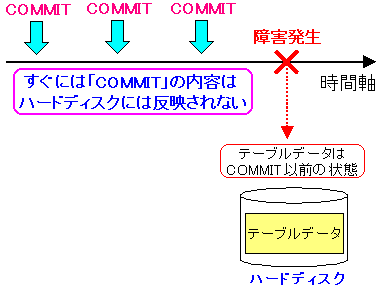 |
COMMITされても、すぐにはハードディスクに反映されない。
そのため、ハードディスクに反映される前に、障害が発生した場合
ハードディスクのデータは、COMMIT以前の内容のままだ。
|
上のような問題が起こるのだ。
だが、そんな事態が起こってもログが救ってくれるのだ!
この時、初めて
ログにデータ復旧の役目がある事を知ったのらー!!
だった (^^)
どのようにしてログがデータ復旧の役目を果たすのか。
図にしてみると以下の通りになる。
| ログの役目を考える |
|---|
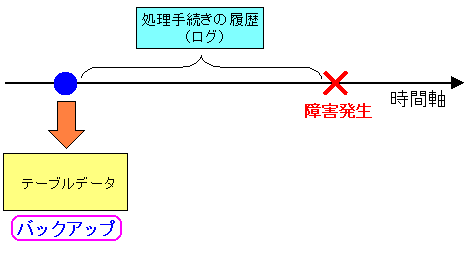 |
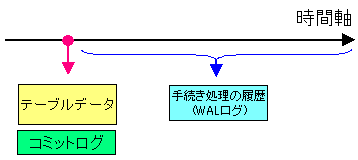
ログは、データベースの変更・追加等の手続き処理を記録している。
ある時点でテーブルデータのバックアップをとっているとする。
そして障害発生時までに、テーブルデータの変更等があり、
例え、障害発生時までハードディスクのテーブルデータの内容が
反映されていなくても、その間のログは記録されている。
つまり上図の場合だと、バックアップ時から障害発生までの間の
処理手続きの記録がある。
|
ログがあるという事は、上の図のバックアップ時点のデータから
ログの記録を忠実に処理していけば、ハードディスクにある
テーブルデータは、障害直前までの状態に復旧できるというのだ。
図にすると以下のようになる。
| ログを使って障害直前までの処理を反映させる |
|---|
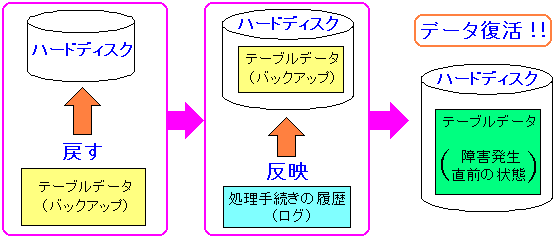 |
バックアップ時のテーブルデータを戻す。
そして、ログに記録されている処理を実行させる。
ログは障害直前までの処理の記録があるため、それに従って処理を行えば
データテーブルは障害直前まで状態にする事ができる。
|
データベースの機能で「COMMIT」後は、何が何でも反映させるために
ログがあるというのが、ようやく理解できた。
ところで、データファイルそのものをハードディスクへの書き込むと
性能低下を招くので、書き込み処理が発生する度に、書き込み処理の内容を
履歴(ログ)として記録する話として、ふと次の事を思い出した。
せや、ファイルシステムがあるやん!
ファイルシステムのジャーナル機能だ。
| ファイルシステムのジャーナル機能 |
|---|
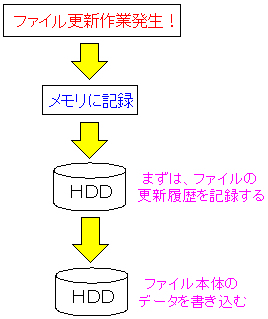 |
ファイルシステムで、ext3、ReiserFS、JFS、XFSには
ジャーナル機能と呼ばれる物がついている。
ジャーナル機能だが、活用されるのは以下の場合の時だ。
例えば、停電などで、いきなり電源が切れた後、
Linuxを起動させる際、ファイルシステムの点検が行われる。
その際、ジャーナル機能があれば、ファイル更新履歴によって
不要なファイル点検が行われずに済み、点検速度があがるのだ。
詳しくは「システム奮闘記:その31」をご覧ください。
|
データベースの話を知るためには、ファイルシステムの話を
知っておいた方が理解しやすそうだ。
すっかりファイルシステムの事なんぞ忘れてしまったので
自分で書いた「システム奮闘記:その31」を見ながら、
色々、思い出していくのだった (^^)
チェックポイント(CHECKPOINT)
ところで、COMMITをする度に、処理の内容をログには書き込まれるが、
どれくらいの間隔で、実際のデータテーブルに反映させるのか。
普通なら、そういう発想が出てきても、おかしくないのだが、
この時は、全く疑問にも思わず、本を読み進める事にした。
すると「チェックポイント(CHECKPOINT)」の説明の部分に到着した。
チェックポイント(CHECKPOINT)とは何か。
本に書いてあった内容を図にすると以下のようになる。
| 「チェックポイント(CHECKPOINT)」とは何か? |
|---|
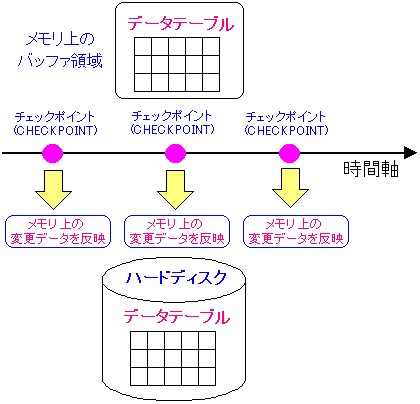 |
チェックポイント(CHECKPOINT)は、メモリ上にあるテーブルデータで
COMMIT済みの処理を検出し、COMMIT済みの内容を
ハードディスクに反映させる処理だ。
これにより、トランザクション処理でログに記録された処理が
全てハードディスク内のテーブルデータに反映されるのだ。
|
要するに、高速化のためにメモリ上に読み込んで、やりとりしている
テーブルデータの内容を、ハードディスクのデータ本体に反映させるための物だ。
ところで、トランザクションの途中でチェックポイントが行われた場合
どれくらいハードディスクに反映されるのだろうか?
答えは本に書いていた。というより、上の疑問なんぞ考えないで
本を読むと、その話が出ていたのだった (^^;;
トランザクションの途中で「チェックポイント(CHECKPOINT)」が
行われた場合は、どうなるのか? |
|---|
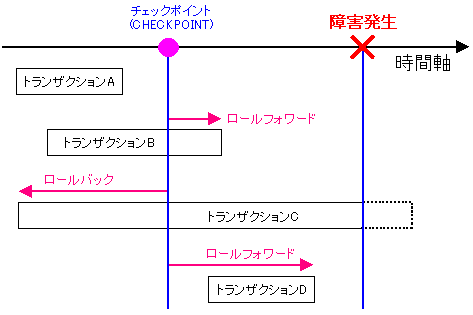 |
チェックポイント(CHECKPOINT)が行われている時点で、
処理中のトランザクションは記録される。
上の図のように、トランザクションBは障害発生以前に
処理が終了しているため、ロールフォワード(ROLL FORWARD)
すなわち、障害復旧の際は、処理が行われた状態になる。
だが、トランザクションCのように、障害発生した時も
処理中の場合は、ロールバック(ROLL BACK)が起こる。
障害からの復旧の状態は、処理が行われなかった状態になる。
それは障害発生前にトランザクションの処理が終わっていないため、
障害発生直前の状態は、処理が終了していないと見なされるからだ。
チェックポイント(CHECKPOINT)が行われた後に
処理が開始され、障害発生前に終了したトランザクションDの場合は
障害発生直前で処理が終わっている事から、障害復旧の際は
処理終了の状態になる。
|
この時は「ふ〜ん」という程度で軽く流す程度だった。
実際に復旧作業の練習等を行わないと座学だけでは、
頭の中で具体的な状況が描く事ができないため、「あっそう」で終わってしまう。
ところでチェックポイント(CHECKPOINT)は、どれくらいの間隔で
行われるのか。
普通は、この疑問が出てくるはずなのだが、この時の私の場合、
疑問にも思わなかった。
それに関しては後述しています。
「RDBMS 解剖学」(鈴木幸市、藤塚勤也:翔泳社)を読みながらも、
他のPostgreSQLの本を読む。
「改訂第3版 PostgreSQL完全攻略ガイド」(石井達夫:技術評論社)と
「PostgreSQL完全機能リファレンス」(鈴木啓修:秀和システム)だ。
PostgreSQLのデータ構造について触れている部分に出くわす。
この時は気がつかなかったのだが、データ復旧の話につながる部分なのだ。
さて、PostgreSQLに関係するディレクトリーだが、ソースコンパイルの場合
初期設定の状態では以下のディレクトリーに保管されている。
/usr/local/pgsql
そしてデータや設定ファイルに関しては以下のディレクトリーに保管されている。
/usr/local/pgsql/data
このディレクトリーで「ls」コマンドで見てみると次のようになる。
/usr/local/pgsql/dataディレクトリーで「ls」コマンドを実行
(PostgreSQL-7.3.6の場合) |
|---|
[postgres@server postgres]$ cd /usr/local/pgsql/data/
[postgres@server data]$ ls
PG_VERSION global pg_hba.conf pg_xlog postmaster.opts
base pg_clog pg_ident.conf postgresql.conf postmaster.pid
|
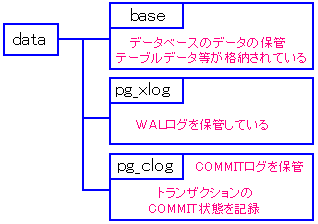
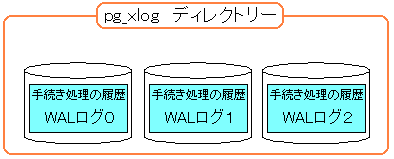
肝心のデータベースのデータは「base」ディレクトリーに保管されている。
WALログは「pg_xlog」ディレクトリーに保管されている。
実は、もう1つ大事なデータが入ったディレクトリーがある。
「pg_clog」ディレクトリーだ。
この時は、そんな事を知らなかったが、後になって知った。
前後は逆になるが「pg_clog」ディレクトリーに格納される
データに関する事を書きます。
チェックポイント(CHECKPOINT)を実行した時、COMMIT済みの処理を検出し
データテーブルに反映させる話を書きました。
実は、チェックポイント(CHECKPOINT)の役目は、それだけでなく、
その時、処理中のトランザクションなどの状態を記録する役目もある。
図にすると以下のような役目なのだ。
| チェックポイント(CHECKPOINT)の、もう1つの役目 |
|---|
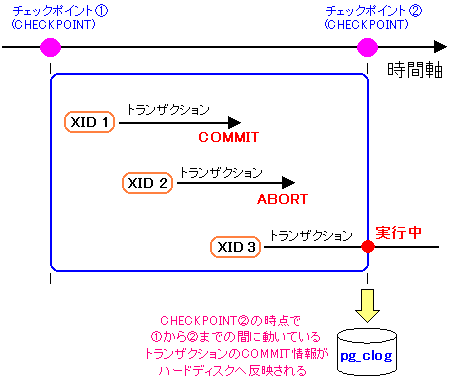 |
前回のチェックポイントからの間で処理されたトランザクションの
COMMITの状態を記録する役目がある。
トランザクションID(XID)が「1」は、COMMIT済みなので、
「XID1:COMMIT」という風に記録される。
トランザクションID(XID)が「2」は、ABORTされたので
「XID2:ABORT」という風に記録される。
トランザクションID(XID)が「3」は、処理途中なので
「XID3:IN_PROGRESS」という風に記録される。
PROGRESSは「進行」の意味なので、「IN_PROGRESS」は進行中の意味になる。
|
データテーブルといったデータ本体、WALログ、COMMIT状態の記録の
重要な御三家の中身が格納されているのだ。
図にすると以下のようになる。
| PostgreSQLに関する各種データが格納されたディレクトリー |
|---|
 |
座学で退屈な部分なのだが、WALの真骨頂のデータ復旧には必要な知識だ。
実践! WALを使った障害時のデータ復旧
さて、座学ばかりだと退屈で仕方がない。
なので、WALを使うと、障害直前までデータが復元(リカバリ)ができるのか
実際に、試してみる事にした。
だが、問題があった。
具体的な復旧作業方法がわからへん (TT)
だった。
そのため、ここで止まってしまった。
他にやる事もあり、しばらく足踏みを強いられる事になった。
さて、再度、WALを使ったデータ復旧の方法に取り組む事にした。
そこで以下の本を取り出した。
「PostgreSQL完全機能リファレンス」(鈴木啓修:秀和システム)
まずは、PostgreSQL7.1系時代から可能になったWALによるデータの復元を
やってみる事にした。
実験として、PostgreSQLのバージョンは、7.3.6を使った。
さて、実験の大まかな流れを表すと
| 障害発生までの流れ |
|---|
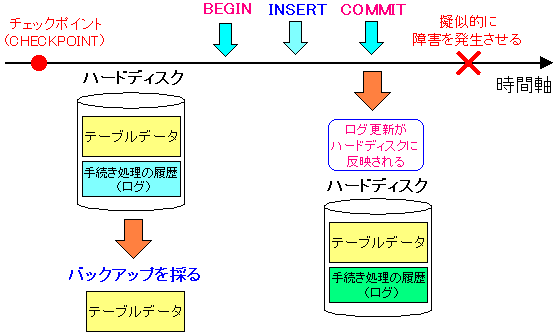 |
データのバックアップを取る前に、チェックポイント(CHECKPOINT)を行い
現在のテーブルデータの状態を、完全にハードディスクへ
反映させた状態にしておく。
そしてテーブルデータのバックアップを取る。
その後、トランザクションを開始して、レコードを追加する。
そして、COMMITでトランザクションを終了させる。
この時点で、手続き処理の履歴(ログ)は反映される。
擬似的に障害を発生させる事で、意図的にインスタンス障害発生の
状況をつくり出す。
|
ここから復旧への流れ。
| 障害発生から復旧までの流れ |
|---|
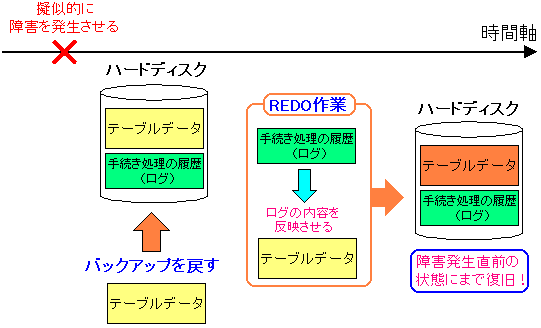 |
バックアップで取っていたテーブルデータを戻す。
そしてREDO作業。
REDO作業とは「Re DO」(再実行)の意味で、ログに記録されている処理を
チェックポイント(CHECKPOINT)の時点から、障害発生直前までを行う事だ。
REDO作業が終われば、障害発生前に行ったレコード追加の処理が
ハードディスクに反映され、データ復旧となる。
|
流れとしては以上になるのだが、実際に、具体的な作業はどう行うのか。
本を読んで、実際の作業内容を調べてみたのだが・・・
具体的な方法が書いてへん (TT)
だった。
本を読むと以下の記述があった。
| 「PostgreSQL完全機能リファレンス」のP52を引用 |
|---|
ハードディスクには、最後のCHECKPOINT時点でのデータが保存されており
それ以降の変更はWALログにだけ保存されています。
そこで、WALログに記録されたSQL文を順に再実行(Redo)することで、
クラッシュ直前の状態にまで復旧できます。
|
この時、思った。
REDOコマンドを使えば、復旧できるかも!
SQL文で、REDOコマンドがあると思った私は、名にも考えずに
REDOコマンドを実行する事にした。
だが、エラーが出た。
| とりあえず「REDO」を入力した結果 |
|---|
postgres=# REDO ;
ERROR: syntax error at or near "REDO"
LINE 1: REDO ;
^
postgres=#
|
なんでエラーが出んねん (TT)
だった (--;;
「REDO」コマンドが存在するのかどうか確認のため「\h」で
SQL文のコマンドを確認してみた。
| 「ヘルプ」の「\h」でSQL文のコマンドを確認 |
|---|
postgres=# \h
Available help:
ABORT CREATE OPERATOR CLASS END
ALTER AGGREGATE CREATE OPERATOR EXECUTE
ALTER CONVERSION CREATE ROLE EXPLAIN
(途中省略)
CREATE INDEX DROP USER
CREATE LANGUAGE DROP VIEW
postgres=#
|
ヘルプを使ったら「REDO」が表示されない事から、
「REDO」コマンドは存在しない事がわかる。
|
そもそもREDOコマンドはあらへんやん (--;;
さて、困った。
「一体、どないしたら、復元できるんや」と思いながら
あれこれ考えてみる。
ふと思った。
REDOってPostgreSQLが自動的に行ってくれるのかも
そこで気を取り直してデータの復旧実験を行う。
■■■ 気を取り直して復旧実験開始 ■■■
さて、データ復旧の実験の概略は既に説明しましたが、
具体的に、どういう事を行うのか図にしていました。
| 擬似的に障害を発生させるまでの流れ |
|---|
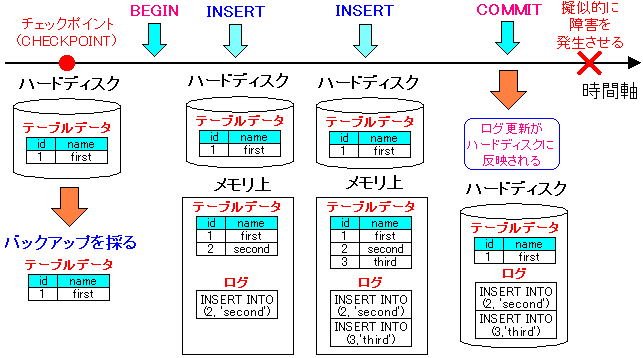 |
テーブルのレコードが1レコードの状態にして、
テーブルデータのバックアップを取る。
そして、2レコード追加を行い、「COMMIT」を実行させ
トランザクションの内容(レコード追加の内容)を確定させる。
その後、PostgreSQLを停止させ、擬似的に障害発生を起こす形を取る。
|
次に障害発生から復旧までの流れを図にしました。
| 障害発生から復旧までの流れ |
|---|
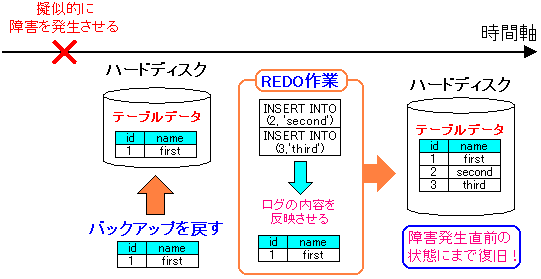 |
バックアップデータを戻し、その後、PostgreSQLを起動させ、
実際にデータが復旧して、テーブルのデータが
3レコードあるかを確認する。
|
こんな流れで復旧実験を進めます。
まずはテーブルデータの中身を確認する
| テーブルデータの中身を確認 |
|---|
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
1レコードだけが登録されている。
この内容をハードディスクに完全に反映させるため、
PostgreSQLの管理者で接続して、チェックポイント(CHECKPOINT)を行う。
| 管理者権限でチェックポイント(CHECKPOINT)を行う |
|---|
[postgres@server data]$ psql -U postgres testdb
Welcome to psql 7.3.6, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
testdb=# CHECKPOINT ;
CHECKPOINT
testdb=#
|
これでデータベースのレコードの内容が、完全にハードディスクに
反映されたので、テーブルデータのバックアップをとる。
| バックアップを取る作業 |
|---|
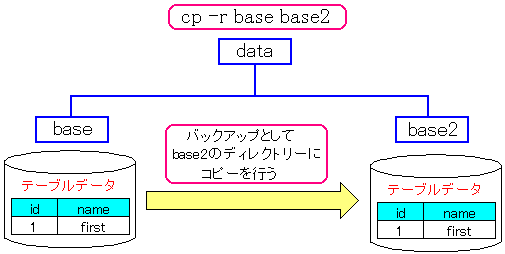 |
| 作業内容 |
[postgres@server data]$ cp -r base base2
[postgres@server data]$
|
そして、トランザクションを開始して、レコードを追加し、
COMMITでレコードの追加を確定させる。
トランザクションを開始してレコード追加し
COMMITで追加を確定させる |
|---|
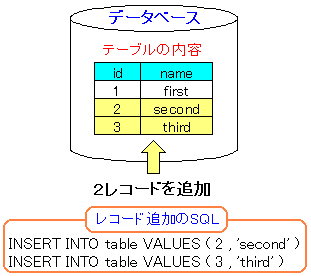 |
| 作業内容 |
testdb=> BEGIN ;
BEGIN
testdb=> INSERT INTO test VALUES ( 2 , 'second' ) ;
INSERT 41561 1
testdb=> INSERT INTO test VALUES ( 3 , 'third' ) ;
INSERT 41562 1
testdb=> COMMIT ;
COMMIT
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
3 | third
(3 rows)
testdb=>
|
COMMIT後、SELECT文でレコードが追加されているか確認。
問題なく追加されている事がわかる。
|
次は、擬似的に障害を起こすのだが、この時は、正常終了をしてみた。
擬似的障害発生
(正常終了をさせた) |
|---|
[postgres@server data]$ pg_ctl stop
LOG: smart shutdown request
LOG: shutting down
waiting for postmaster to shut down......LOG: database system is shut down
done
postmaster successfully shut down
[postgres@server data]$
|
そして、バックアップに取っておいたテーブルデータを戻す。
| バックアップのデータを元のディレクトリー戻す |
|---|
PostgreSQLが終了した時のテーブルデータは不要なので、
「base」の中身を消去する。
そして、「base2」のディレクトリーに入っているバックアップデータを
元のディレクトリー「base」に戻す。
|
そして、PostgreSQLを起動させてみた。
| PostgreSQLを起動させた |
|---|
[postgres@server data]$ pg_ctl start
LOG: database system was shut down at 2007-09-19 18:24:56 JST
LOG: checkpoint record is at 0/85415C
LOG: redo record is at 0/85415C; undo record is at 0/0; shutdown TRUE
LOG: next transaction id: 593; next oid: 57945
postmaster successfully started
[postgres@server data]$ LOG: database system is ready
[postgres@server data]$
|
さて、これでデータが復旧しているかどうか確かめる。
この時がワクワクするのらー (^^)
さて、テーブルの中身を見てみる。すると・・・
| テーブルの中身を見てみる |
|---|
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
全く復旧してへん (TT)
だった。
これでは、WALを使った障害復旧ができない。
「何がおかしいのやろか」と考える。
そこで思いついたのは
擬似的な障害発生は正常終了ではアカンのや!
そうなのだ。正常終了させては、とても異常発生の状態とは言えないのだ。
そこで異常終了をさせる方法を考える。すぐに思いつく。
PostgreSQLのプロセスを・・・
killコマンドで殺してしまえ!
だった。
「殺す」という物騒な言葉を使う私。
私の家は浄土真宗だが、肉食が公認された、とんでもない仏教なので
必要な殺生は認められている。
なので、ためらいもなくプロセスを殺す事ができるのだ。
■■■ 気を取り直して再度実験を行う ■■■
まずはテーブルデータの中身を確認する
| テーブルデータの中身を確認 |
|---|
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
1レコードだけが登録されている。
この内容をハードディスクに完全に反映させるため、
PostgreSQLの管理者で接続して、チェックポイント(CHECKPOINT)を行う。
| 管理者権限でチェックポイント(CHECKPOINT)を行う |
|---|
[postgres@server data]$ psql -U postgres testdb
Welcome to psql 7.3.6, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
testdb=# CHECKPOINT ;
CHECKPOINT
testdb=#
|
これでデータベースのレコードの内容が、完全にハードディスクに
反映されたので、テーブルデータのバックアップをとる。
| バックアップを取る作業 |
|---|
|
| 作業内容 |
[postgres@server data]$ cp -r base base2
[postgres@server data]$
|
そして、トランザクションを開始して、レコードを追加し、
COMMITでレコードの追加を確定させる。
トランザクションを開始してレコード追加し
COMMITで追加を確定させる |
|---|
|
| 作業内容 |
testdb=> BEGIN ;
BEGIN
testdb=> INSERT INTO test VALUES ( 2 , 'second' ) ;
INSERT 41561 1
testdb=> INSERT INTO test VALUES ( 3 , 'third' ) ;
INSERT 41562 1
testdb=> COMMIT ;
COMMIT
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
3 | third
(3 rows)
testdb=>
|
COMMIT後、SELECT文でレコードが追加されているか確認。
問題なく追加されている事がわかる。
|
次は、擬似的に障害を起こす。
今回は、異常終了させるため、PostgreSQLのプロセスを
killコマンドで殺す事にする。
一応、私の家は、浄土真宗で仏教なのだが、他の仏教の宗派と違い
公然と肉食が認められている。即ち、ある程度の殺生が認められているので
安心してプロセスも殺す事ができる。
| killコマンドでPostgreSQLのプロセスを殺す |
|---|
[postgres@server data]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 1368 80 ? S Sep10 0:04 init [5]
root 2 0.0 0.0 0 0 ? SW Sep10 0:01 [keventd]
(途中省略)
postgres 20311 0.0 0.5 8456 1432 pts/2 S 18:01 0:00 postmaster
postgres 20312 0.0 0.4 8016 1248 pts/2 S 18:01 0:00 postgres: stats buffer process
postgres 20313 0.0 0.5 7056 1280 pts/2 S 18:01 0:00 postgres: stats collector process
postgres 20321 0.0 0.2 2676 728 pts/2 R 18:03 0:00 ps aux
postgres 20322 0.0 0.1 4328 476 pts/2 S 18:03 0:00 more
[postgres@server data]$ kill -9 20311
|
そして、PostgreSQLのプロセスIDを記録したファイルを消去する。
これをしておかないと、PostgreSQLの起動時にエラーが発生して
起動できないからだ。
| ostgreSQLのプロセスIDを記録したファイルを消去する |
|---|
[postgres@server data]$ ls
PG_VERSION base2 pg_clog pg_ident.conf postgresql.conf postmaster.pid
base global pg_hba.conf pg_xlog postmaster.opts
[postgres@server data]$ rm postmaster.pid
|
そして、バックアップに取っておいたテーブルデータを戻す。
| バックアップのデータを元のディレクトリー戻す |
|---|
[postgres@server data]$ rm -rf base
[postgres@server data]$ cp -r base2 base
|
PostgreSQLが終了した時のテーブルデータは不要なので、
「base」の中身を消去する。
そして、「base2」のディレクトリーに入っているバックアップデータを
元のディレクトリー「base」に戻す。
|
さて、いよいよ実験がうまくいくのかどうかの確認だ。
データが復旧できるかどうか、ワクワクしながら、起動させてみる。
| PostgreSQLを起動させる |
|---|
[postgres@server data]$ postmaster &
[1] 20327
[postgres@server data]$ LOG: database system was interrupted at 2007-09-19 18:01:59 JST
LOG: checkpoint record is at 0/849CA4
LOG: redo record is at 0/849CA4; undo record is at 0/0; shutdown TRUE
LOG: next transaction id: 572; next oid: 41561
LOG: database system was not properly shut down; automatic recovery in progress
LOG: redo starts at 0/849CE4
LOG: ReadRecord: record with zero length at 0/84DE60
LOG: redo done at 0/84DE3C
LOG: database system is ready
[postgres@server data]$
|
ピンクの部分は異常終了をした時点の表示のようだ。
青い部分がチェックポイント(CHECKPOINT)の場所の確認のようだ。
赤い部分がREDO(再実行)をしているようだ。
この分だと、データの復旧ができている感じがする。
|
テーブルの中身をみてみる。
| テーブルの中身をみてみる |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 7.3.6, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
3 | third
(3 rows)
testdb=>
|
見事、成功!! (^^)
バックアップで取ったテーブルデータは、1レコードしか
記録されていないのだが、バックアップ後に記録された処理の内容を
ログを使った実行させたお陰で、障害直前の状態まで
テーブルデータの状態を復旧させる事ができる。
PostgreSQLを6年間使っていたのだが
初めて知った話だったのらー!!
だった。
6年とは長い道程だ。
赤ちゃんが、ランドセルを背負って友達100人作りに学校へ行くまでの時間だ。
ふと思った。
よく考えると、障害発生直前までデータを復旧をさせるに、
別にバックアップを取る必要がないのではないか。
コケた後、PostgreSQLを起動させれば、自動的に復旧してくれるのではないか。
| よく考えたら、PostgreSQLを起動させるだけで良いのは |
|---|
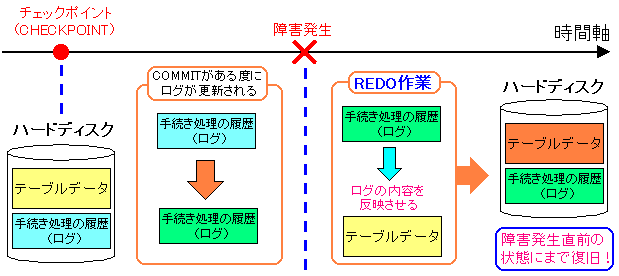 |
障害発生後、PostgreSQLを起動させるだけで、
REDOが自動的に行われるため、特にバックアップデータを
戻したりする必要がないのではないかと思った。
ただ、障害発生後に、PostgreSQLを起動させれば良いのは、
あくまでハードディスクが正常な場合だけであって、
ハードディスクの障害などでデータがオシャカになった場合は、
バックアップデータが必要になる上、ログデータが無事である事が
大事になってくる。
|
ちなみに、このWALを使った復旧作業は、PostgreSQL8.0系でも使えます。
PostgreSQL8.2.4で確認していますが、ここでは実験内容は割愛します。
PITR (ポイント・イン・タイム・リカバリ
さて、WALを使ったデータの復旧の方法を覚えた。
だが、PostgreSQL8.0系以降は、WALを使った復旧で、もっと凄い物がある。
前述していますが「PITR」(ポイント・イン・タイム・リカバリ)と
呼ばれる物だ。
これを使うと、障害発生直前だけでなく、バックアップの時点から
障害発生までの間の任意の時間を指定して、その時間のデータの状態に
復旧させる事ができる優れ物なのだ。
概略を図にすると以下の通りだ。
| 「PITR」(ポイント・イン・タイム・リカバリ)の概略 |
|---|
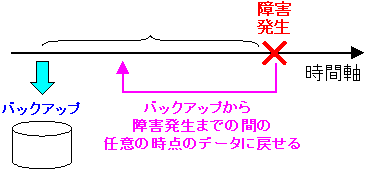 |
PostgreSQL8.0までは、障害直前の状態まで復旧できても
任意の時点での復旧はできなかった。
データベースの運用上、これは大きな意味を持つ。
|
任意の時点での復旧が可能。
これが大きな意味も持つ理由だが、すぐに理解できた。
つまり次のような場合に役に立つのだ。
さて、本当に任意の時点にデータを復旧させる事が可能なのか。
実際に自分の目で確かめる事にした。
実験には、PostgreSQLの最新版の8.2.4(2007/9/20現在)を使う事にした。
「PITR」(ポイント・イン・タイム・リカバリ)を確かめる実験なので、
ある任意の時点にデータを復旧できるかを示す必要がある。
そこで以下の流れで実験を行う。
| 実験の概要・その1 |
|---|
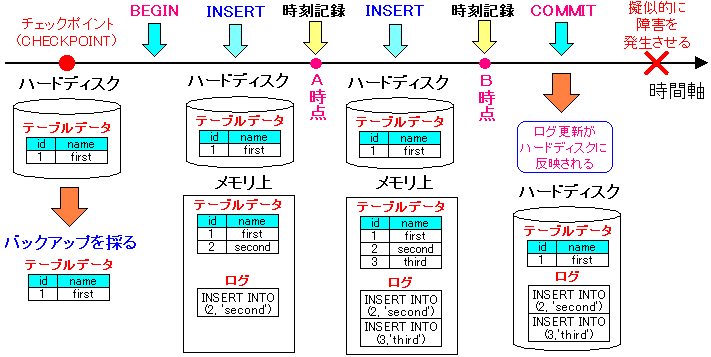 |
1つのレコードを持ったテーブルに、2つのレコードを追加する。
1つ1つレコードを追加するごとに時刻を記録する。
1つ目のレコードを追加した直後を「A時点」とし
2つ目のレコードを追加した直後を「B時点」とする。
この時刻はdateコマンドの結果を紙に書き留めておく。
この時、実験としてはAの時点の時刻が重要になる。
そして擬似的に障害を発生させる。
この時は、PostgreSQLのプロセスを殺すのだ。「南無阿弥陀仏 チーン」
|
さて、障害を発生させた後は以下の流れで復旧させる。
| 実験の概要・その2 |
|---|
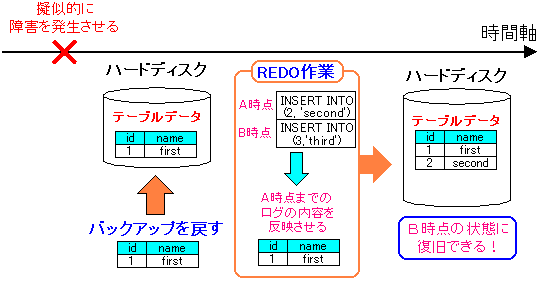 |
データの復旧を行うのだが、全部データを復旧させたのでは
任意の時点まで復旧できる事を示す事ができない。
そこで「概要・その1」の図にある、A時点までの復旧を行う。
そうすれば、テーブルのデータは、レコードが1つ追加された状態に
復旧ができるわけだ。
|
さて、早速、実験を行う。
まずはテーブルの状態を確認する。
| テーブルの状態を確認 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
テーブルの状態は確認できたので、バックアップを取る。
以下のように、baseディレクトリーのコピーを行う。
| バックアップを取る作業 |
|---|
|
[postgres@server data]$ cp -r base base2
[postgres@server data]$
|
そしてレコードを1つ追加する。
| レコードを1つ追加と、追加後の時刻を記録 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> INSERT INTO test VALUES ( 2 , 'second' ) ;
INSERT 0 1
testdb=> \q
[postgres@server data]$ date
2007年 9月 21日 金曜日 13:34:43 JST
[postgres@server data]$
|
日本時間の2007年9月21日13時34分43秒を復旧させたい時刻にする。
この時刻は、復旧時に使うので大事に保管しておく。
さて、もう1レコード追加を行い、追加後の時刻を見る。
| もう1レコード追加と、追加後の時刻を記録 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> INSERT INTO test VALUES ( 3 , 'third' ) ;
INSERT 0 1
testdb=> \q
[postgres@server data]$ date
2007年 9月 21日 金曜日 13:35:10 JST
[postgres@server data]$
|
この時点の時刻は参考に見る程度で別に記録する必要はない。
さて、ここでテーブルのレコードを見てみる。
| テーブルのレコードを見てみる |
|---|
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
3 | third
(3 rows)
testdb=>
|
元々あった1レコードと追加した2レコードの合計3レコードだ。
さて、ここで擬似的に障害を発生させる。
擬似的に障害発生
(PostgreSQLのプロセスを殺す) |
|---|
[postgres@server data]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 2092 528 ? S Sep20 0:00 init [5]
root 2 0.0 0.0 0 0 ? SN Sep20 0:00 [ksoftirqd/0]
(途中省略)
postgres 22402 0.2 1.3 38580 3452 pts/1 S 13:33 0:00 /usr/local/pgsql/bin/postgres
postgres 22404 0.0 0.4 38580 1236 ? Ss 13:33 0:00 postgres: writer process
postgres 22405 0.0 0.3 10028 904 ? Ss 13:33 0:00 postgres: stats collector process
postgres 22413 0.0 0.3 3920 792 pts/1 R+ 13:35 0:00 ps aux
[postgres@server data]$ kill -9 22402
|
プロセスが死んだ所で「postmaster.pid」ファイルを消す。
そして、バックアップでとっていたテーブルデータを元に戻す。
| バックアップのデータを元のディレクトリー戻す |
|---|
[postgres@server data]$ rm -rf base
[postgres@server data]$ cp -r base2 base
|
PostgreSQLが終了した時のテーブルデータは不要なので、
「base」の中身を消去する。
そして、「base2」のディレクトリーに入っているバックアップデータを
元のディレクトリー「base」に戻す。
|
だが、まだやる事がある。
戻したい時刻を設定する必要がある。
そのため、復旧させたい時刻を記入するファイル(recovery.conf)に
該当の時間を書き込む必要がある。
このファイルは/usr/local/pgsql/share/recovery.conf.sampleにあるので
/usr/local/pgsql/dataのディレクトリにコピーする必要がある。
もちろんファイル名は「recovery.conf」だ。
| recovery.conf ファイルに書き込み |
|---|
recovery_target_time = '2007-09-21 13:34:43 JST'
restore_command = 'cp /usr/local/pgsql/data/pg_xlog/%f %p'
|
これで日本時間の2007年9月21日13時34分43秒の時点に復旧する設定だ。
1つ目のレコードを追加した後の時刻だ。
時刻以外にも、XID(トランザクションID)の何番に戻すという指定もできる。
2行目は、WALログのバックアップのディレクトリーの指定なのだが、
この時は・・・
アーカイブログって何やねん!
だったので、忍法「適当に設定してしまえの術」を使って、
WALログが保管される pg_xlog ディレクトリーを指定した。
WALログを使って復旧させるのだから、pg_xlogを指定すれば良いだろうと
単純に考えただけだった。
この設定については、後述しています。
|
これで復旧の準備が整った。
そして、postgreSQLを動かしてみる。
| PostgreSQLを起動させる |
|---|
[postgres@server data]$ pg_ctl start
server starting
[postgres@server data]$ LOG: database system was interrupted at 2007-09-21 13:33:52 JST
LOG: starting archive recovery
LOG: restore_command = "cp /usr/local/pgsql/data/pg_xlog/%f %p"
LOG: recovery_target_time = 2007-09-20 13:34:43+09
cp: cannot stat `/usr/local/pgsql/data/pg_xlog/00000001.history': そのようなファイルやディレクトリはありません
LOG: restored log file "000000010000000000000000" from archive
LOG: checkpoint record is at 0/447EB0
LOG: redo record is at 0/447EB0; undo record is at 0/0; shutdown TRUE
LOG: next transaction ID: 0/627; next OID: 16400
LOG: next MultiXactId: 1; next MultiXactOffset: 0
LOG: automatic recovery in progress
LOG: redo starts at 0/447EF8
LOG: recovery stopping before commit of transaction 628, time 2007-09-21 13:34:39 JST
LOG: redo done at 0/44814C
cp: cannot stat `/usr/local/pgsql/data/pg_xlog/00000002.history': そのようなファイルやディレクトリはありません
LOG: selected new timeline ID: 2
cp: cannot stat `/usr/local/pgsql/data/pg_xlog/00000001.history': そのようなファイルやディレクトリはありません
LOG: archive recovery complete
LOG: database system is ready
[postgres@server data]$
|
赤い部分が復旧させたい時点の時刻だ。
実は私の入力間違いで本来なら9月21日の所を20日と打ってしまった。
だが、この間違いは、この原稿の編集中に気づいたのだった。
実験最中、そんな事に気づいていない私は、そのまま実験を続けた。
|
そして復旧した結果を見るため、レコードを見てみる事にした。
ワクワクしながら結果を見ると・・・
| レコードを見た結果 |
|---|
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
全然、うまくいってへんやん (TT)
最初に追加した1レコードが閲覧できないとダメなのに、
実験の結果では、追加したレコードが全て消えている。
もちろん、復旧させたい時刻は、私の入力間違いのため、
実際の時刻よりも1日前の時刻を指定しているためだった。
しかし、そんな事は実験中には気づかなかったため
この方法ではうまくいかへん
と思い込んだ。
■■■ ここで気を取り直して再度設定・実験 ■■■
そこで、本を見てみる事にした。
アーカイブログの部分を読むと、バックアップする際に、
何か仕掛けがいるような事を書いていた。
ふと思った。単にコピーだけのテーブルデータ領域のバックアップには
問題があるのではないか。
| これでは駄目だと思ったバックアップの方法 |
|---|
|
上の単純なコピーだと、任意の時刻に復旧できないと思った。
何かコピーの前後にコマンドか設定ファイルの記述が必要かと思った。
|
なぜ、駄目なのかは横に置いておいて、とりあえずは
忍法「丸写しの術!」
で、よくわからないまま、そこで本の通り、以下の方法をとる事にした。
| 本に書いてあったバックアップの方法 |
|---|
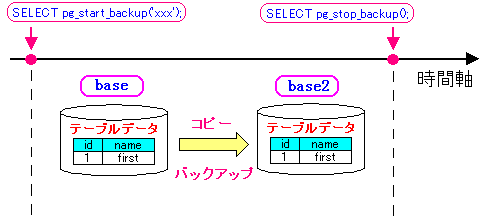 |
データテーブルが入った「base」ディレクトリーのコピーを
行う前後でSQLコマンドを使う。
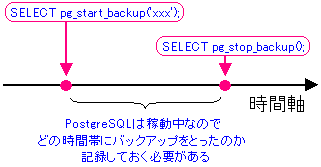
コピーの前は「SELECT pg_start_backup('xxx')」を行う。
この時「xxx」は任意の文字列が使える。
コピーの後は「SELECT pg_stop_backup()」
これらのSQL文は管理者権限で行う必要がある。
|
忍法「本の丸写しの術」を使っているので、どんな処理なのかはわからない。
どんな処理を行っているかについては、後述しています。
早速、バックアップを取りたくなるが、その前にレコードの状態を確認。
| テーブルデータの中身を確認 |
|---|
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
キチンと、1レコードだけが登録されている。
早速、先ほど学んだ方法で、バックアップを取るために、
バックアップ前の処理を行ってみる事にした。
だが・・・
| 早速、実行してみた |
|---|
testdb=# SELECT pg_start_backup('test');
ERROR: WAL archiving is not active
HINT: archive_command must be defined before online backups can be made safely.
STATEMENT: SELECT pg_start_backup('test');
ERROR: WAL archiving is not active
HINT: archive_command must be defined before online backups can be made safely.
testdb=#
|
エラーが出てもうた (TT)
「なんでエラーが出るねん」と思った。
もっと本をよく読んでみる事にした。
postgresql.confにWALログのバックアップを取るディレクトリーの指定が
必要だというのだ。
でも、この時は、本の内容が理解できていなかったため
アーカイブログって何やねん!
だった (^^;;
そこで忍法「本の丸写しの術」と「適当に設定してしまえの術」を使って、
設定ファイルの「postgres.conf」を触って書き換える事にした。
| postgres.confの書き換え |
|---|
(書き換え前)
#archive_command = '' # command to use to archive a logfile segment
↓
(書き換え後)
archive_command = 'cp "%p" "/usr/local/pgsql/data/backup/%f"'
|
忍法「適当に設定してしまえの術」を使って、上の設定を行った。
この設定について、詳しい内容については後述しています。
|
そして気を取り直して、再度、挑戦する。
| バックアップ前の作業 |
|---|
testdb=# SELECT pg_start_backup('test');
pg_start_backup
-----------------
0/442E94
(1 row)
testdb=#
|
そして、cpコマンドで「base」ディレクトリを「base2」にコピーする。
| バックアップを取る作業 |
|---|
|
[postgres@server data]$ cp -r base base2
[postgres@server data]$
|
そして、バックアップ後の作業を行う。
| バックアップ後の作業 |
|---|
testdb=# SELECT pg_stop_backup();
pg_stop_backup
----------------
0/2000084
(1 row)
testdb=# LOG: archived transaction log file "000000010000000000000000.00442E94.backup"
LOG: archived transaction log file "000000010000000000000000"
LOG: archived transaction log file "000000010000000000000001.00000020.backup"
LOG: archived transaction log file "000000010000000000000001"
LOG: archived transaction log file "000000010000000000000002.00000020.backup"
LOG: archived transaction log file "000000010000000000000002"
testdb=#
|
これでバックアップが終わった。
では、ここでレコードの追加を行う。
| レコードを1つ追加と、追加後の時刻を記録 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=> INSERT INTO test VALUES ( 2 , 'second' ) ;
INSERT 0 1
testdb=> \q
[postgres@server data]$ date
2007年 9月 21日 金曜日 16:24:42 JST
[postgres@server data]$
|
青い部分は、レコード追加のSQL文。
赤い部分は、レコードを追加した後の時刻を見てみる。
実験では、この時刻の状態に復旧させたいため、この時刻を紙に記録しておく。
2007年9月21日16時24分42秒を指している。
|
さて、もう1レコード追加を行う。
| もう1レコード追加と、追加後の時刻を記録 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> INSERT INTO test VALUES ( 3 , 'third' ) ;
INSERT 0 1
testdb=> \q
[postgres@server data]$ date
2007年 9月 21日 金曜日 16:25:08 JST
[postgres@server data]$
|
この時点の時刻は参考に見る程度で別に記録する必要はない。
さて、ここでテーブルのレコードを見てみる。
| テーブルのレコードを見てみる |
|---|
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
3 | third
(3 rows)
testdb=>
|
元々あった1レコードと追加した2レコードの合計3レコードだ。
さて、ここで擬似的に障害を発生させる。
擬似的に障害発生
(PostgreSQLのプロセスを殺す) |
|---|
[postgres@server data]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 2092 528 ? S Sep20 0:00 init [5]
root 2 0.0 0.0 0 0 ? SN Sep20 0:00 [ksoftirqd/0]
(途中省略)
postgres 22622 0.2 1.3 38680 3448 pts/1 S 16:23 0:00 /usr/local/pgsql/bin/postgres
postgres 22624 0.0 0.4 38680 1180 ? Ss 16:23 0:00 postgres: writer process
postgres 22625 0.0 0.2 10128 752 ? Ss 16:23 0:00 postgres: archiver process
postgres 22626 0.0 0.3 10128 900 ? Ss 16:23 0:00 postgres: stats collector process
postgres 22636 0.0 0.3 3248 792 pts/1 R+ 16:25 0:00 ps aux
[postgres@server data]$ kill -9 22622
[postgres@server data]$
|
プロセスを殺した。南無阿弥陀仏。
「postmaster.pid」ファイルを消す。
さて、バックアップの作業を始める。
| バックアップのデータを元のディレクトリー戻す |
|---|
[postgres@server data]$ rm -rf base
[postgres@server data]$ cp -r base2 base
|
PostgreSQLが終了した時のテーブルデータは不要なので、
「base」の中身を消去する。
そして、「base2」のディレクトリーに入っているバックアップデータを
元のディレクトリー「base」に戻す。
|
そして、recovery.confに復旧させたい時点の時刻を書く。
それだけではない。WALログを読み込む部分だが、
最初の実験ではWALログが格納されている「pg_xlog ディレクトリー」を
指定したのだが、バックアップのディレクトリーという事で、
postgresql.confファイルで指定したディレクトリーを記述した。
もちろん、この時点では、この設定の意味がわかっていなかったので、
忍法「適当に設定してしまえの術」である事には変わりない (^^)
| recovery.conf ファイルに書き込み |
|---|
restore_command = 'cp /usr/local/pgsql/data/backup/%f %p'
recovery_target_time = '2007-09-21 16:24:42 JST'
|
この時、WALログを読み込むのだから、WALログが格納されている
ディレクトリーを指定すれば良いと思って、上の設定を行った。
この後の実験結果は問題なかったのだが、設定方法としては
間違いだったのを後で知る事になる。
それについては、後述しています。
|
さて、これで準備が整った。
PostgreSQLを動かしてみる。
データが予定通り、戻したい時点の時刻の状態に戻るかどうか
ワクワクする。
| PostgreSQLを起動させる |
|---|
[postgres@server data]$ pg_ctl start
server starting
[postgres@server data]$ LOG: database system was interrupted at 2007-09-21 16:23:56 JST
LOG: starting archive recovery
LOG: restore_command = "cp /usr/local/pgsql/data/backup/%f %p"
LOG: recovery_target_time = 2007-09-21 16:24:42+09
cp: cannot stat `/usr/local/pgsql/data/backup/00000001.history': そのようなファイルやディレクトリはありません
cp: cannot stat `/usr/local/pgsql/data/backup/000000010000000000000003': そのようなファイルやディレクトリはありません
LOG: checkpoint record is at 0/3000068
LOG: redo record is at 0/3000068; undo record is at 0/0; shutdown TRUE
LOG: next transaction ID: 0/617; next OID: 16393
LOG: next MultiXactId: 1; next MultiXactOffset: 0
LOG: automatic recovery in progress
LOG: redo starts at 0/30000B0
LOG: recovery stopping before commit of transaction 621, time 2007-09-21 16:25:05 JST
LOG: redo done at 0/3000298
cp: cannot stat `/usr/local/pgsql/data/backup/00000002.history': そのようなファイルやディレクトリはありません
LOG: selected new timeline ID: 2
cp: cannot stat `/usr/local/pgsql/data/backup/00000001.history': そのようなファイルやディレクトリはありません
LOG: archive recovery complete
LOG: database system is ready
LOG: archived transaction log file "00000002.history"
[postgres@server data]$
|
赤い部分は、戻したい時点の時刻だ。問題なしだ。
なんだかエラーが出ているが、本によれば気にしなくても良いという。
|
さて、レコードの状態を見る。ワクワクしながら見てみる。
| レコードを見た結果 |
|---|
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
2 | second
(2 row)
testdb=>
|
見事、成功 (^^)V
予定通り、2レコード表示している。
この時、次のように結論づける事にした。
データを任意の時刻の時点に戻す方法(PITR)の場合、
バックアップを取る前後では、処理が必要!
つまりバックアップの前後には以下の作業が必要だと確信を持ったのだ。
ポイント・イン・タイム・リカバリ(PITR)を使った復旧作業では
バックアップを取るのには、この方法が必要だと確信した |
|---|
|
この奮闘記を書いている時も、これでないと駄目だと思い込んでいた。
だが、編集中に、この結論が誤っている事に気づいた。
最初の実験で失敗したのは、バックアップの方法ではなく、
復旧させたい時刻をファイルに記述する際に、転記間違いをしていたのが
発覚したからだった (^^;;
正しい時刻を記述していれば、任意の時点の時刻に復旧できるのかどうか
再検証を行う必要が出てきた。
■■■ ここで再検証 ■■■
さて、ここでの再検証の内容を書きますと、任意の時点の時刻に復旧させる
即ち、ポイント・イン・タイム・リカバリ(PITR)を活用した復旧の場合
バックアップの取り方は、単純に「base」ディレクトリーのコピーだけで
良いのかどうかだ。
| 以下の図のような単純なコピーで良いのか? |
|---|
|
| 作業内容 |
[postgres@server data]$ cp -r base base2
[postgres@server data]$
|
早速、実験に取り掛かる。
まずレコードが1レコードである事を確認。
| テーブルデータの中身を確認 |
|---|
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
キチンと1レコードだけの状態になっている。
ここでチェックポイント(CHECKPOINT)を行い、レコードの内容を
ハードディスクに反映させる。
| 管理者権限でチェックポイント(CHECKPOINT)を行う |
|---|
[postgres@server data]$ psql -U postgres testdb
Welcome to psql 7.3.6, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
testdb=# CHECKPOINT ;
CHECKPOINT
testdb=#
|
これでハードディスクに完全に反映できたので、バックアップをとる。
ここでは単純に「base」ディレクトリーのコピーを行うだけにする。
| バックアップを取る作業 |
|---|
[postgres@server data]$ cp -r base base2
[postgres@server data]$
|
バックアップをとったので、レコード追加の作業を行う。
そして、追加後の時刻を表示・記録を行う。
| 1レコードの追加と、追加後の時刻の表示と記録 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> INSERT INTO test VALUES ( 2 , 'second' ) ;
INSERT 0 1
testdb=> \q
[postgres@server data]$ date
2007年 9月 30日 日曜日 17:28:01 JST
[postgres@server data]$
|
青い部分がレコード追加の部分。
赤い部分がレコード追加後の時刻だ。
この時刻の時点に復旧させるために、時刻を紙に記録しておく。
|
そして、もう1レコード追加を行う。
| もう1レコード追加を行う |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> INSERT INTO test VALUES ( 3 , 'third' ) ;
INSERT 0 1
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
3 | third
(3 rows)
testdb=> \q
[postgres@server data]$
|
テーブルのレコードが3レコードになった。
ここで擬似的に障害を起こし、そして、2レコード目を追加した直後の時点の
状態に復旧させる。復旧後、2レコード表示されれば成功だ。
| 擬似的に障害発生させる |
|---|
[postgres@server data]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 1372 80 ? S Sep22 0:04 init [5]
root 2 0.0 0.0 0 0 ? SW Sep22 0:00 [keventd]
(途中、省略)
postgres 2810 0.0 0.4 5444 1224 pts/9 S 17:21 0:00 bash
postgres 2863 0.1 1.1 36196 2976 pts/9 S 17:26 0:00 /usr/local/pgsql/bin/postgres
postgres 2865 0.0 1.2 36220 3088 ? S 17:27 0:00 postgres: writer process
postgres 2866 0.0 0.5 7644 1512 ? S 17:27 0:00 postgres: stats collector process
postgres 2880 0.0 0.2 2672 724 pts/9 R 17:28 0:00 ps aux
[postgres@server data]$ kill -9 2863
[postgres@server data]$
|
プロセスを殺す事で、擬似的にデータベースの障害停止を行った。
ここでバックアップにとっていたデータを戻す作業を行う。
| バックアップで取っていたデータを戻す作業 |
|---|
[postgres@server data]$ mv -f base base-org
[postgres@server data]$ mv -f base2 base
|
1行目は、データベース障害直後の状態のデータ。
これは別の所に退避させておく。
今回は「base-org」のディレクトリ名に置く事にした。
2行目は、バックアップに取っていたデータの入った「base2」を
データベースのデータのディレクトリー「base」に戻す作業。
|
そして、任意の時点に復旧させるために、recovery.confファイルの
書き換え作業を行う。
先ほど、記録した「2レコード目を追加した後の時刻」を記入する。
| recovery.confファイルの書き換え作業 |
|---|
recovery_target_time = '2007-09-30 17:28:01 JST'
|
そして、PostgreSQLを起動させる。
| PostgreSQLを起動させる |
|---|
[postgres@server data]$ pg_ctl start
pg_ctl: another server may be running; trying to start server anyway
LOG: database system was interrupted at 2007-09-30 17:27:41 JST
LOG: starting archive recovery
LOG: restore_command = "cp /usr/local/pgsql/data/pg_xlog/%f %p"
LOG: recovery_target_time = 2007-09-30 17:28:01+09
cp: cannot stat `/usr/local/pgsql/data/pg_xlog/00000001.history': そのようなファイルやディレクトリはありません
LOG: restored log file "000000010000000000000000" from archive
LOG: checkpoint record is at 0/6AA75C
LOG: redo record is at 0/6AA75C; undo record is at 0/0; shutdown FALSE
LOG: next transaction ID: 0/3381; next OID: 16985
LOG: next MultiXactId: 1; next MultiXactOffset: 0
LOG: automatic recovery in progress
server starting
[postgres@server data]$ LOG: redo starts at 0/6AA7A4
LOG: recovery stopping before commit of transaction 3384, time 2007-09-30 17:28:24 JST
LOG: redo done at 0/6AA9CC
cp: cannot stat `/usr/local/pgsql/data/pg_xlog/00000002.history': そのようなファイルやディレクトリはありません
LOG: selected new timeline ID: 2
cp: cannot stat `/usr/local/pgsql/data/pg_xlog/00000001.history': そのようなファイルやディレクトリはありません
LOG: archive recovery complete
LOG: database system is ready
[postgres@server data]$
|
PostgreSQLは立ち上がったし、復旧作業が行われている表示も出ている。
さて、実際に、2レコード目を追加した直後の状態に戻っているかどうか
確認してみる事にする。
この瞬間は、ワクワクする。
| テーブルのレコードを確認 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
(2 rows)
testdb=>
|
見事、2レコードだけが表示された (^^)
この再検証の結果、バックアップの前後の処理は不要な事がわかった。
単に実験で、復元させる時点の時刻をrecovery.confファイルに
記入する際に、転記間違いをしただけでった。
幸い、編集時に、それに気づいたのだが、気づかなかったら・・・
あやうく大ウソを書く所だった (^^;;
技術的な知識不足で、誤った事を書いてしまった場合ならまだしも、
単なる転記間違いの場合は「事務員だもーん」の逃げ道が使えないのらー!!
これで任意の時刻の状態に戻せる事がわかった。
でも、これで全てが理解できたわけでもないし、実験の方法もいい加減だ。
しかも、全く整理されていない上、誤った知識を散りばめている。
実は、バックアップを取る前後に「pg_start_backup('xxx');」と
「pg_stop_backup();」の処理を行うには重要な意味を持つのだ。
そこで、知識の整理と設定の意味合いについて書いてみる事にした。
PITRを使った正しいバックアップとデータの復元
PostgreSQL8.0以降から実装されたPITR(ポイント・イン・タイム・リカバリ)を
活用すると、任意の時刻の状態に、復旧させる事ができるのがわかった。
だが、今までの実験ではPITRの活用が不十分で、見落としている部分が
ある事がわかった。
要するに、PITRを正確に説明できていないのだ。
そこで今までの話を整理しながら、バックアップとデータ復元の話を
していきたいと思います。
【1】 バックアップの話
バックアップを取る際、特に「pg_start_backup('xxx');」と
「pg_stop_backup();」の必要ないと書いたのだが、
それも誤っている事が発覚した (^^;
なので、取りこぼしがないように、その辺りの話をしたいと思います。
さて、結論から書くと、PITR(ポイント・イン・タイム・リカバリ)は
任意の時刻に復旧させるだけでなく、PostgreSQLを稼働させながら、
データとWALログのバックアップを取る事ができるのだ。
|
PostgreSQLを稼働させながら、データとWALログのバックアップが可能 |
|---|
 |
データベースのデータのバックアップは手動で行う必要があるが、
WALログを自動的にバックアップのディレクトリーに移動してくれるのだ。
|
もっと、わかりやすく図にすると以下の通りになる。
| こんな感じでバックアップをとる |
|---|
 |
ある時点でテーブルデータと、コミットログのバックアップを取る。
その後、定期的にWALログのバックアップを自動的に取る仕組みだ。
そうする事で、障害が発生しても、ある時点のテーブルデータと
コミットログを戻し、その後、WALログを使って、障害直前や
その手前の任意の時刻の状態にデータを復旧させる事ができる。
|
まずは、データベースの本体のテーブルデータと、コミットログの
バックアップの話から。
PostgreSQLが稼働中にデータのバックアップを取っていると
バックアップ中にデータの更新があった場合、データの整合性に問題が出てくる。
そこで、整合性を保つための処理が、バックアップの前後に行う
「pg_start_backup('xxx');」と「pg_stop_backup();」だ。
| 実はデータの整合性を保つための処理だった |
|---|
 |
PostgreSQLが稼働中にデータのバックアップを取るため、
どの時点でバックアップを開始して、どの時点で終了したのかを
記録しておく必要がある。その記録を行うための合図なのだ。
|
図で説明する事ができた。
だが、それで終わる事はできない。
自分の目で確かめたい。なので、論より証拠で実験を行ってみる。
まずは、「pg_start_backup('xxx');」と「pg_stop_backup();」の合図で
どの時点でバックアップが開始され、どの時点で終了しているかを
記録している様子を見てみる。
|
「pg_start_backup('xxx');」の合図 |
|---|
[postgres@server postgres]$ psql
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
postgres=# SELECT pg_start_backup('test') ;
pg_start_backup
-----------------
0/667614
(1 row)
postgres=#
|
バックアップの開始の合図で、印(赤字)を「test」にした。
あとになってからも、どのバックアップかがわかるようにするためだ。
|
そして、データベースのデータが格納されたdataディレクトリーごと
コピー(バックアップ)が終わった後、バックアップの終了の合図を行う。
|
「pg_stop_backup();」の合図 |
|---|
postgres=# SELECT pg_stop_backup() ;
pg_stop_backup
----------------
0/667678
(1 row)
LOG: archived transaction log file "000000010000000000000000.00667614.backup"
postgres=# LOG: archived transaction log file "000000010000000000000000"
postgres=#
|
さて、新しくできた「000000010000000000000000.00667614.backup」ファイルを
見てみる事にした。
|
「000000010000000000000000.00667614.backup」ファイルの中身 |
|---|
[postgres@server pg_xlog]$ cat 000000010000000000000000.00667614.backup
START WAL LOCATION: 0/667614 (file 000000010000000000000000)
STOP WAL LOCATION: 0/667678 (file 000000010000000000000000)
CHECKPOINT LOCATION: 0/667614
START TIME: 2007-10-10 09:39:00 JST
LABEL: test
STOP TIME: 2007-10-10 09:43:41 JST
[postgres@server pg_xlog]$
|
赤い部分が開始の合図の時刻で、青い部分が終了の合図の時刻だ。
この間にバックアップが取られた事がわかるようになっている。
あと、これはWALログのファイル「000000010000000000000000」の
「667614」という場所から「667678」の場所までの間に
バックアップを取られたという意味も持っている
|
バックアップを取る前後で合図を行う事で、どの時点で開始し、
どの時点で終了したのかがわかるため、データの整合性を保つ事ができる。
これでテーブルデータと、コミットログのバックアップの話は完了 (^^)
次に、WALのバックアップの話について。
WALログは「data/pg_xlog」ディレクトリーに保管される。
|
WALログは「data/pg_xlog」ディレクトリーに保管される |
|---|
 |
初期設定ではWALログの固まりは、16Mのファイルに保存される。
16Mのファイルの固まりは3つだ。
|
WALログファイルが何個、pg_xlogに保管されるのかの設定は
postgresql.confファイルで設定する。
| postgresql.confファイルで設定(PostgreSQL-8.2.4) |
|---|
# - Checkpoints -
#checkpoint_segments = 3 # in logfile segments, min 1, 16MB each
|
初期設定では「3」になっている。
ここの数字を変える事で、pg_xlogに保管されるWALログファイルの固まりの
数が決まる。
|
もし、WALログが溜っていき、3つのファイルの中に入らなくなったら
新たにWALログファイルが生成される。
しかし、その際、一番古いWALログファイルは破棄される。
|
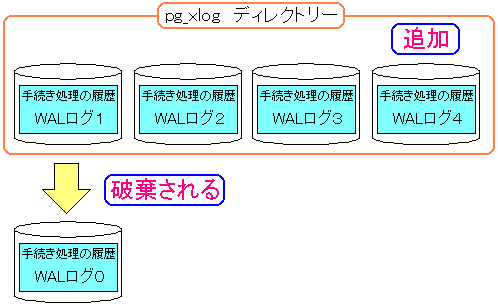
新しいWALログファイルができると一番古いファイルは破棄される |
|---|
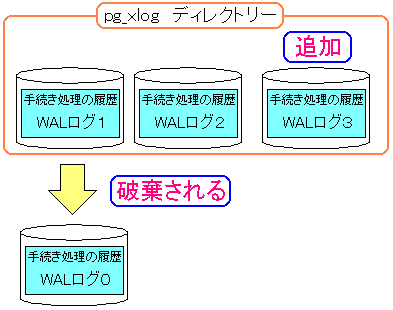 |
|
一番古いWALログは不要という事で破棄されていく。
|
時間の経過と共に古いWALログのファイルが破棄されるため、
データのバックアップを取ってから、時間が経過した場合、
以下の問題が起こる。
| データの復旧ができなくなる問題が発生する! |
|---|
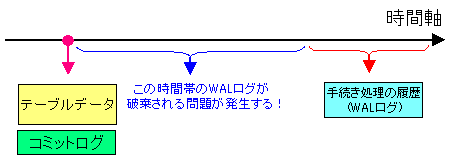 |
時間の経過と共に古いWALログが破棄されていくため
もし、障害が発生し、テーブルデータから障害発生直前まで
データを復旧させたくても、古いWALログが破棄されているため
復旧が行えなくなる!!
|
そこで古いWALログを破棄せずに、別のディレクトリーに置くのが
WALログのバックアップというわけだ。
| 古いWALログを破棄せずに保管する事ができる |
|---|
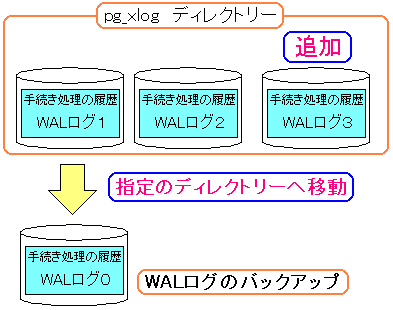 |
古いWALログを破棄せずに、指定されたディレクトリーに
バックアップとして保管する方法がある。
それは、postgresql.confファイルで設定する事だ。
この設定は、PITR(ポイント・イン・タイム・リカバリ)を活用する場合、
WALログのバックアップを置くため、必ず必要な設定になる。
|
postgresql.conf の設定(WALログのバックアップ先の指定) |
|---|
# - Archiving -
#archive_command = '' # command to use to archive a logfile segment
archive_command = '/bin/cp "%p" "/home/postgres/backup/%f"'
|
WALログのバックアップを保管するディレクトリーを
「/home/postgres/backup」に指定。
この設定の意味は、WALログのバックアップを採取する際、
cpコマンドを使って「/home/postgres/backup」にコピーする意味だ。
|
こうする事によって、古いWALログが破棄されずに保管される。
もちろん、手動ではなく、自動的に行ってくれる。
ここでようやく・・・
設定の意味が理解できたのらー!! (^^)
だった。
忍法「適当に設定してしまえの術」だけでは駄目で、やはり知識の整理は
必要だと感じる。
でも、実際に自動的にWALログのバックアップを行ってくれるのか
自分の目で確かめてみたくなる。
そこで、手でSQL文を入力したりするが、20ぐらいのSQL文を打った所で
めんどくさい上・・・
新たなWALログファイルが生成されへん (TT)
だった。
手入力では限度がある。手間がかかるだけで何もない。
そこで自動的にSQL文を発行させる事を考えた。
以下のWebプログラムを作成した。
| Webプログラム( autosql.php ) |
|---|
<html><head><title>何十万レコードを追加するプログラム</title></head>
<body>
<?php
$conn = pg_connect("dbname=testdb user=suga");
for ( $i = 1 ; $i < 400000 ; $i++)
{
$name = "No".$i ;
$sql = "INSERT INTO test VALUES ( $i , '$name' )" ;
pg_exec($sql);
}
print $sql."<br>" ;
pg_close($conn);
?>
</body></html>
|
赤い部分で40万回の繰り返しを行う。
青い部分はレコード追加のSQL文だ。
SQL文を40万個、データベース上で使う事で、WALログが溜っていく様子を
見るという方法だ。
|
そして、最初はWALログのバックアップをとらない事にした
さて、実験開始。
ハードディスクのランプが激しく点滅する。
プログラムが終了した後、WALログが保管される data/pg_xlog の
ディレクトリーを見てみた。
| pg_xlog ディレクトリー |
|---|
[postgres@server pg_xlog]$ ls -l
合計 49216
-rw------- 1 postgres postgres 16777216 10月 19 09:38 000000010000000000000000
-rw------- 1 postgres postgres 16777216 10月 19 09:40 000000010000000000000001
-rw------- 1 postgres postgres 16777216 10月 19 09:43 000000010000000000000002
drwx------ 2 postgres postgres 4096 10月 16 09:10 archive_status
[postgres@server pg_xlog]$
|
まだWALログが足らないようだ。
そのため、最初からあった「000000010000000000000000」ファイルが
残っている。
このディレクトリーには3つのWALファイルしか保管されないので、
もし、新たなWALログのファイルが生成されると
「000000010000000000000000」ファイルは破棄されるはずだ。
|
プログラムを少し触って、もう10万レコード追加作業を行ってみた。
すると、pg_xlogディレクトリーは以下のようになった。
| pg_xlog ディレクトリー |
|---|
[postgres@server pg_xlog]$ ls -l
合計 65620
-rw------- 1 postgres postgres 16777216 10月 19 09:50 000000010000000000000002
-rw------- 1 postgres postgres 16777216 10月 19 09:53 000000010000000000000003
-rw------- 1 postgres postgres 16777216 10月 19 09:38 000000010000000000000004
-rw------- 1 postgres postgres 16777216 10月 19 09:40 000000010000000000000005
drwx------ 2 postgres postgres 4096 10月 16 09:10 archive_status
[postgres@server pg_xlog]$
|
WALログファイルが大量に生成されたため、古いファイルの
「000000010000000000000000」と「000000010000000000000001」が
破棄されている事がわかる。
|
よく見ると・・・
なんで、4つもファイルがあるねん??
謎だ・・・。
でも、ファイルが更新された時刻を見てみると次の事に気づいた。
本来、一番新しいはずの「000000010000000000000005」が
更新時刻が「9:40」だ。
一番古いファイル「000000010000000000000002」は
「9:50」なので、更新時間が逆転している。
他のWALログファイルで、ログが格納されている順番と、更新時刻順番が
違っているのがわかる。
2番目に番号が大きいファイルの更新時刻が
多分、次の事が行われていると思う。
| 多分、こういう事だろうと思ったりする |
|---|
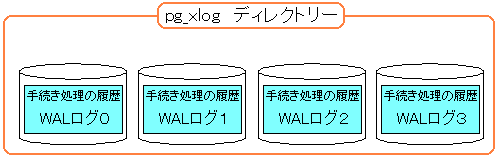 |
WALログのファイルが4つになっている。
つまりpostgresql.confで設定した数に1つ追加した形になる。
1個余分にファイル(4番目のファイル)があるのは、
余分にWALログが書き込まれていない空のファイル
(容量は16Mバイトあるが)を用意しておいて
3番目のファイルにWALログが書き込まなくなった場合に
即座に、1番目のファイルを指定させたディレクトリーに移動させ、
4番目のファイルにWALログが書き込めるように準備していると
思ったりする。
|
| 即座に対応できるため、あらかじめ用意しているのかも |
 |
だが、推測の域は超えない。
徹底的に調べたいのだが、そんな知識も技術もない。
だって、事務員だもーん (^^)
そう、この技が使える間は、使う私なのだ。
しかもタチの悪い私は、労務や経理の事を聞かれても・・・
タダではないが二束三文の事務員だもーん (^^)
とお得意に忍法「言い訳の術」で逃げるのだ。
閑話休題。
次に、WALログのバックアップを取る事にした。
WALログの番号がわかりやすくするために、先程の実験の続きではなく
データベースを初期化した。
なので、postgresql.confの設定を以下のように行う。
| postgresql.confの設定 |
|---|
# - Archiving -
#archive_command = '' # command to use to archive a logfile segment
archive_command = '/bin/cp "%p" "/home/postgres/backup/%f"'
|
そして、30万レコードを追加するSQL文を発行するプログラムを走らせる。
| pg_xlogディレクトリーの中 |
|---|
[postgres@server pg_xlog]$ ls -l
合計 65624
-rw------- 1 postgres postgres 16777216 10月 10 15:35 000000010000000000000001
-rw------- 1 postgres postgres 16777216 10月 10 15:37 000000010000000000000002
-rw------- 1 postgres postgres 16777216 10月 10 15:39 000000010000000000000003
-rw------- 1 postgres postgres 16777216 10月 10 15:31 000000010000000000000004
drwx------ 2 postgres postgres 4096 10月 10 15:39 archive_status
[postgres@server pg_xlog]$
|
「000000010000000000000000」ファイルがない。
無事、バックアップ先に指定したディレクトリーに保管されているか
確かめる事にした。
|
そこでバックアップ先のディレクトリー「/home/postgres/backup」を
見てみる事にした。
| /home/postgres/backup ディレクトリーの中 |
|---|
[postgres@server backup]$ pwd
/home/postgres/backup
[postgres@server backup]$ ls
000000010000000000000000
[postgres@server backup]$
|
pg_xlogのディレクトリーに入らなくなったWALログのファイルが
無事、バックアップのディレクトリーに移動しているのがわかる。
|
これでWALログのバックアップの設定方法や設定の意味が理解できた (^^)
やはり本の内容を頭だけで理解するのではなく、手で触っていかないと
実感として湧かないのだ。
さて、バックアップの話は完了した。
【2】 データの復元の話
ここからデータの復元の話をします。
データの復元に必要なのは、ある時点のテーブルデータとコミットログ。
そして、その時点から復元したい時点までのWALログの3点だ。
| データ復元に必要なバックアップデータ |
|---|
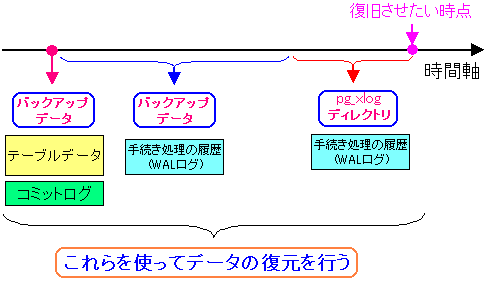 |
ある時点でとったテーブルデータとコミットログ。
その後に記録したWALログのデータだ。
WALログには2つある。pg_xlog ディレクトリーに記録された物と
pg_xlogディレクトリーが満杯になって、指定されたディレクトリーに
保管されたWALログがある。
これらを使って、障害直前までの任意の時点の状態に
データを復旧させる事ができる。
|
さて、実際にデータの復元ができるのかを自分の目で確かめてみる。
まずは、テーブルを用意して、バックアップ前のデータを作る。
| バックアップ前のテーブルの様子 |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> SELECT * FROM test ;
id | name
----+-------
1 | first
(1 row)
testdb=>
|
「test」という名前のテーブルに1レコード入れている状態だ。
これがバックアップを取る前の状態としておく。
|
そしてバックアップを取るのだが、この合図を送る前に
pg_xlogのディレクトリーが満杯にあった時、古いWALログを保管する
ディレクトリーの指定をしないとエラーが発生する。
古いWALログは、WALログのバックアップというわけだ。
| ostgresql.confの設定(古いWALログの移動先を指定) |
|---|
# - Archiving -
#archive_command = '' # command to use to archive a logfile segment
archive_command = '/bin/cp "%p" "/home/postgres/backup/%f"'
|
これで準備は良し。
PostgreSQLが稼働中でもデータに不整合が起こらぬように
バックアップの前後に合図を送る。
| バックアップ前の合図を行う |
|---|
[postgres@server data]$ psql testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=# SELECT pg_start_backup('test');
pg_start_backup
-----------------
0/443B58
(1 row)
testdb=#
|
ここでバックアップを取る。
テーブルデータとコミットログだ。
「base」と「pg_clog」のディレクトリーだが、面倒な場合は、
dataディレクトリーごとコピーすれば良い。
ただし、dataディレクトリーごとコピーをとった場合、
その中に含まれるpg_xlog (WALログのデータが格納されたディレクトリ)は、
バックアップには使わないので注意が必要だ。
| データのバックアップを取る |
|---|
[postgres@server data]$ cp -r base base2
[postgres@server data]$ cp -r pg_clog pg_clog2
[postgres@server data]$
|
とりあえず、この時点でのテーブルデータのディレクトリー「base」と
コミットログのディレクトリー「pg_clog」のバックアップを取る。
それぞれ「base2」、「pg_clog2」にしておいた。
|
テーブルデータと、コミットログのバックアップが取れたので、
バックアップの終了の合図を送る。
| バックアップ終了の合図を送る |
|---|
postgres=# SELECT pg_stop_backup() ;
pg_stop_backup
----------------
0/443BBC
(1 row)
LOG: archived transaction log file "000000010000000000000000.00443B58.backup"
postgres=# LOG: archived transaction log file "000000010000000000000000"
postgres=#
|
これでテーブルとコミットログのバックアップの作業は完了した。
次に、SQL文を発行させる。
ここではレコード追加を行う。そして、すぐ後の時刻を見てみる。
| レコード追加を行い、その直後の時刻を見てみる |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> INSERT INTO test VALUES ( 2 , 'second' ) ;
INSERT 0 1
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
(2 rows)
testdb=> \q
[postgres@server data]$ date
2007年 10月 10日 水曜日 15:25:21 JST
[postgres@server data]$
|
2レコード目を追加した直後を、復元したい時点にするため
時刻を紙に記録しておく。10月10日15時25分21秒だ。
10月10日とは、昔の体育の日だなぁ。
|
ここでレコードを追加していくのだが、1レコードや2レコード増やしても
実際に、pg_xlogだけだけでなく、バックアップ先に移動した
WALログが使われているのかどうかの確認ができない。
そこで、大量のSQL文を発行させて、WALログを大量に吐き出させて
pg_xlogを満杯にさせ、バックアップ先にWALログのファイルを移動させてみる。
そのため、以下のプログラムを作ってみた。
わかりやすいように、INSERT文で大量にレコードを追加するプログラムだ。
| 大量にレコードを追加するプログラム ( insert.php ) |
|---|
<html><head><title>大量にレコードを追加させる</title></head>
<body>
<?php
$conn = pg_connect("dbname=testdb user=suga");
for ( $i = 3 ; $i < 300000 ; $i++)
{
$name = "No".$i ;
$sql = "INSERT INTO test VALUES ( $i , '$name' )" ;
pg_exec($sql);
}
pg_close($conn);
print $name."<br>\n" ;
?>
</body></html>
|
20万レコード(厳密には19万9997レコード)を追加するプログラムだ。
これだけレコードを追加すれば、大量のWALログが発生して、
pg_xlogは満杯になり、古いWALログのファイルはバックアップに
移動する事が期待できる。
|
そして、19万9997レコードの追加プログラムを実行してみた。
ハードディスクのランプが激しく点滅する。
プログラムが終了した後、pg_xlogディレクトリーの中を見たみた。
| pg_xlogディレクトリーの中を見たみた |
|---|
[postgres@server pg_xlog]$ ls -l
合計 65624
-rw------- 1 postgres postgres 234 10月 10 15:31 000000010000000000000000.00443B58.backup
-rw------- 1 postgres postgres 16777216 10月 10 15:35 000000010000000000000001
-rw------- 1 postgres postgres 16777216 10月 10 15:37 000000010000000000000002
-rw------- 1 postgres postgres 16777216 10月 10 15:39 000000010000000000000003
-rw------- 1 postgres postgres 16777216 10月 10 15:31 000000010000000000000004
drwx------ 2 postgres postgres 4096 10月 10 15:39 archive_status
[postgres@server pg_xlog]$
|
これを見ると、一番古いWALログのファイル「000000010000000000000000」が
バックアップのディレクトリーに移動しているのがわかる。
|
次に、PostgreSQLに対して擬似的に障害を発生させて停止させる。
| 擬似的に障害を発生させてPostgreSQLを停止させる |
|---|
[postgres@server pg_xlog]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 1372 80 ? S Oct01 0:04 init [5]
root 2 0.0 0.0 0 0 ? SW Oct01 0:00 [keventd]
(途中省略)
postgres 29533 0.0 0.5 36196 2660 pts/2 S 15:29 0:00 /usr/local/pgsql/bin/postgres
postgres 29535 0.0 3.0 36220 15836 ? S 15:29 0:00 postgres: writer process
postgres 29536 0.0 0.2 7644 1208 ? S 15:29 0:00 postgres: archiver process
postgres 29537 0.0 0.2 7644 1196 ? R 15:29 0:00 postgres: stats collector process
postgres 29571 0.0 0.1 2680 732 pts/2 R 15:46 0:00 ps aux
[postgres@server pg_xlog]$
[postgres@server pg_xlog]$ kill -9 29533
[postgres@server pg_xlog]$
|
これでPostgreSQLのプロセスが死んだ。
天に召しませアーメン。おっとと、私の家は浄土真宗なので「南無阿弥陀仏」だ。
ここから復元したい時点までデータを復旧させる。
まずは不要なファイルを消去させる。
| postmaster.pidファイルを消去 |
|---|
[postgres@server data]$ rm postmaster.pid
[postgres@server data]$
|
そして、テーブルデータとコミットログのバックアップデータを戻す。
|
テーブルデータとコミットログのバックアップデータを戻す |
|---|
[postgres@server data]$ rm -rf base
[postgres@server data]$ mv -f base2 base
[postgres@server data]$ rm -rf pg_xlog
[postgres@server data]$ mv -f pg_clog2 pg_clog
|
まずは、障害直前のテーブルデータが格納された「base」を消去して
バックアップの「base2」を「base」に移動させる。
そして、障害直前のコミットログのデータが格納された「pg_clog」を消去して
バックアップの「pg_clog2」を「pg_clog」に移動させる。
|
これでテーブルデータとコミットログのバックアップ時点に戻した。
次に、WALログを使ってデータの復旧作業だ。
今回は、2レコード目が追加された直後まで戻すので、
2レコード目を追加した後に記録した時刻を、recovery.conf ファイルに書き込む。
| recovery.conf ファイルに書き込む |
|---|
restore_command = 'cp /home/postgres/backup/%f %p'
recovery_target_time = '2007-10-10 15:25:21 JST'
|
pg_xlogが満杯になって、指定されたディレクトリに移動した
WALログのファイルを復旧に使うため、その移動先のディレクトリから
WALログのファイルを取り込む設定を行う。
そして、復旧させたい時刻も記述しておく。
|
さて、復旧開始。
PostgreSQLを開始させる。
| PostgreSQLを開始させる |
|---|
[postgres@server pg_xlog]$ pg_ctl start
server starting
[postgres@server pg_xlog]$ LOG: database system was interrupted at 2007-10-10 15:29:41 JST
LOG: starting archive recovery
LOG: restore_command = "cp /home/postgres/backup/%f %p"
LOG: recovery_target_time = 2007-10-10 15:32:08+09
cp: cannot stat `/home/postgres/backup/00000001.history': そのようなファイルやディレクトリはありません
LOG: restored log file "000000010000000000000000.00443B58.backup" from archive
LOG: restored log file "000000010000000000000000" from archive
LOG: checkpoint record is at 0/443B58
LOG: redo record is at 0/443B58; undo record is at 0/0; shutdown FALSE
LOG: next transaction ID: 0/630; next OID: 16393
LOG: next MultiXactId: 1; next MultiXactOffset: 0
LOG: automatic recovery in progress
LOG: redo starts at 0/443BA0
LOG: restored log file "000000010000000000000001" from archive
LOG: recovery stopping before commit of transaction 635, time 2007-10-10 15:33:32 JST
LOG: redo done at 0/1000284
cp: cannot stat `/home/postgres/backup/00000002.history': そのようなファイルやディレクトリはありません
LOG: selected new timeline ID: 2
cp: cannot stat `/home/postgres/backup/00000001.history': そのようなファイルやディレクトリはありません
LOG: archive recovery complete
LOG: database system is ready
LOG: archived transaction log file "00000002.history"
[postgres@server pg_xlog]$
|
そしてレコードの状態を見てみる。
| レコードの状態を見てみる |
|---|
[postgres@server data]$ psql -U suga testdb
Welcome to psql 8.2.4, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
testdb=> SELECT * FROM test ;
id | name
----+--------
1 | first
2 | second
(2 rows)
testdb=>
|
見事、2レコード目を追加した直後に復旧できた (^^)
これで、PITRを活用した正しいバックアップの取り方と
任意の時刻への復旧方法が説明できた。
「PITRの正しく使う方法」の部分で、七転八倒している様子もなく、
簡単そうに書いているのだが、実際は・・・
理解するのに七転八倒しました (^^;;
なのだ。
用語や本の解説を読んでも「あーでもない、こーでもない」と考え
手を動かしたりして、頭の中を整理し、なんとか理解していったのだ。
でも、その様子を刻銘に覚えているわけでもない上、
仮に書けても、とんでもない量になるため、解説にとどめました。
人為的操作誤りでも威力を発揮するPITR
PITR(ポイント・イン・タイム・リカバリ)の機能を使えば、障害時において
バックアップのデータを元に、バックアップ取得時から障害発生までの間の
任意の時刻にデータを復旧させる事ができる事を説明しました。
でも、PITRの利点はそれだけではない。
人為的操作誤りがあっても、威力が発揮するのだ。
つまり以下のような事が発生した場合だ。
| こんな人為的操作誤りがあった場合 |
|---|
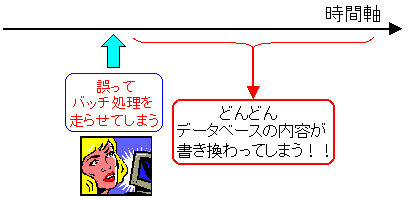 |
誤ってバッチ処理を走らせてしまった場合がある。
バッチ処理を走らせたら、どんどんデータベースのデータが書き変わる。
例えば、業務関連で売上の締めを行った場合が上げられる。
企業によっては請求書発行や経理処理だけでなく、
月別の売上実績データ、個人データといった販売分析の処理も走るだろう。
もし、誤って、これらの処理が走った場合、
1つ1つの操作を見て、データを復元させるのは非常に困難だ。
|
こんな時、PITRが非常に役に立つ。
| こんな人為的操作誤りがあった場合 |
|---|
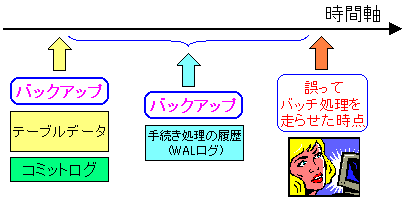 |
テーブルデータとコミットログのバックアップデータを戻し、
操作誤りが発生する時刻の直前まで、WALログを使って
データを復元させるのだ。
こうすれば正確にデータの復元が可能になる。
|
基幹業務システムのデータベースに、このような機能があれば、
非常に助かる。人間なので誤った操作を行う事がある。
誤った操作を行ったとしても、その後に与える影響を最小限に押さえる事が
可能になるからだ。
個人的には、AS400のデータベースにも、こんな機能があれば良いのにと
思ったりする。
■■■ WALについての補遺 ■■■
WALについて書き切れなかったので、ここで補遺という形で
取り上げたいと思います。
ゴキブリホイホイ、WAL補遺補遺 ← ちゃうやろ!!
座蒲団3枚取り上げのギャグでした (^^;;
長い文章を書いていると、アホな事を書いてしまいそうになるのだが
閑話休題。真面目に補遺を書きます。
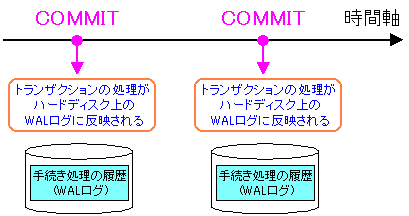
WALログがハードディスクに書き込まれるタイミングは
データベースが「COMMIT」を行った時。つまりデータの更新・追加等が
確定した時だ。
「COMMIT」で更新・追加が確定すれば、何が何でも確定した物を
記録しておく必要があるが、直接、テーブルデータを変更したのでは
ハードディスクへの書き込みのため、データベースの性能が落ちてしまう。
そのため、データ量の小さいトランザクションの処理の内容(処理手続き)を
ハードディスク上のWALログに記録する事にしている。
|
「COMMIT」があれば、処理内容はWALログに書き込まれる |
|---|
 |
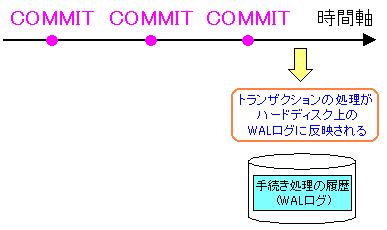
でも、WALログに書き込む場合も、大量のデータの場合、バカにはならない。
「COMMIT」があっても、すぐにはハードディスク上のWALログのファイルに
反映されないようにする事が可能なのだ。
|
「COMMIT」があっても、すぐにWALログに反映されない設定が可能 |
|---|
 |
postgresql.confを触れば可能だ。
| postgresql.confの設定 (PostgreSQL-8.2.4) |
|---|
# - Settings -
#fsync = on # turns forced synchronization on or off
|
上は初期設定の状態で、この時は「on」になっている。
つまり「COMMIT」があれば、すぐにハードディスクのWALログファイルに
反映されるのだ。
だが、「off」にすれば、「COMMIT」があっても、すぐには反映されない。
その分、ハードディスクへの書き込み回数が減り、データベースの性能が
向上するというわけだ。
|
実際に、自分の手で測定して、自分の目で結果を確かめたい。
そこで、以下の性能測定プログラムを作成した。
作成といっても、10万レコードを書き込むのに、どれくらいの時間が
かかったのかを単純に計算するだけだが、目安にはなる。
一応、環境としては、RedHat9.0 (Linux-2.4.20)で、Celeron2G、RAM512Mだ。
| 単純な性能測定プログラム ( time.php ) |
|---|
<html><head><title>単純な性能測定プログラム</title></head>
<body>
<?php
$conn = pg_connect("dbname=testdb user=suga");
// 処理開始時のUNIX時間を出力
$sunix = date("U");
print "start-time : $sunix<BR>" ;
for ( $i = 0 ; $i < 100000 ; $i++)
{
$name = "No".$i ;
$sql = "INSERT INTO test VALUES ( $i , '$name' )" ;
pg_exec($sql);
}
// 処理終了時のUNIX時間を出力
$lunix = date("U");
print "stop-time : $lunix<BR>" ;
$sa = $lunix - $sunix ;
// 開始から終了までのかかった秒を算出
print "sa = $sa <BR>";
pg_close($conn);
?>
</body></html>
|
10万レコードを追加するのに、どれくらい時間がかかるのかを
測定するプログラムなのだ。
色々な要因があるのだが、あくまでも目安という事で、
単純なプログラムを書きました。
|
まずは、「COMMIT」があれば、即座にハードディスクのWALログに
反映される場合から実験を行ってみる。
プログラムを走らせている間、一生懸命、動いているのがわかる。
なぜなら・・・
ハードディスクのランプが激しく点滅しているのらー!
だった。
10万レコード分のWALログを書き込むのだから、結構な量になると思う。
結果は以下の通りになった。
「COMMIT」があれば
即座にハードディスクのWALログに反映される場合 |
|---|
start-time : 1192760982
stop-time : 1192761126
sa = 144
|
| 実験結果では、144秒の時間がかかった事になる。 |
次に、「COMMIT」があっても、すぐにはハードディスクのWALログには
反映されない設定にしてみた。
| postgresql.confの設定 (PostgreSQL-8.2.4) |
|---|
# - Settings -
fsync = off # turns forced synchronization on or off
|
設定を「off」にしたので、「COMMIT」があっても、
すぐには、ハードディスクのWALログには反映されない。
|
設定を「off」にしたので、「COMMIT」があっても、
すぐには、ハードディスクのWALログには反映されない。
|
そして実験を行ってみた。
プログラムを走らせてみると、設定を「on」にした時との違いがあった。
ハードディスクのランプが、あまり点滅せぇへんなぁ。
激しく動いている様子が見られない。
さて、プログラムを走らせた結果は・・・
「COMMIT」があっても
すぐにはハードディスクのWALログに反映されない場合 |
|---|
start-time : 1192761297
stop-time : 1192761357
sa = 60
|
| 実験結果では、60秒の時間に短縮された。 |
144秒から60秒。半分以下の時間に短縮された。
えらい極端に表れたなぁと感心した。
実際には、色々な要因があるため、一概に設定変更をすれば、
性能が倍に向上するとは言えない。
でも、目安としては充分違いがわかる結果になった。
WALログの役目はデータベースの更新・追加の内容を確定させるためで
「COMMIT」が行われたら、即座に、ハードディスクのWALログに書き込み
追加内容を確定させる必要がある。
では、なぜ、「COMMIT」が行われても、すぐにハードディスク上の
WALログのファイルに反映しない設定があるのか。
検索・参照だけのデータベースの場合に便利だからだ。
検索・参照だけだと、データベースの更新・追加とは関係がないため、
WALログに書き込まれても、書き込まれなくても関係はない。
特に、大量の接続がある場合は、参照の度に、ハードディスク上の
WALログのファイルに反映させていたのでは、性能が低下するため、
検索・参照のみの利用の場合、この設定が威力を発揮する。
不要な安全弁を外して、性能を向上させる技というわけだ。
最後に
WALがPostgreSQLに実装されたのは2001年の事だった。
丁度、私がPostgreSQLに手を出した年なのだ。
ふと編集中に思い出す。
その頃、WALが実装された事を大々的に宣伝していた事だ。
当時、それがどれくらい大きな意味を持つのか全く理解していなかったし、
そもそもWALが何なのかすら理解していなかった。
今になって思うと、大きな意味を持つ事に気づく。
データベースを高速に、かつ、安全に動かすための工夫を
感じる事ができます。
WALの話は奥が深いため、今回のシステム奮闘記では、全てを紹介してない上
紹介したくても、私の理解が、そこまで及んでいないため、紹介しきれません。
でも、入門、初級の話は書けたかなぁと思っています。
性能向上のための設定などについては、今後、取り上げる機会があれば
取り上げてみたいと思います。
次章:「Linux ApacheでSSL暗号化通信のインストール設定」を読む
前章:「クッキー(cookie)、セッション管理の設定」を読む
目次:システム奮闘記に戻る