システム奮闘記:その57
smartmontoolsでハードディスク診断
(2007年1月20日に掲載)
はじめに
SMARTといえば、あの「スマート」なのだ。
信楽焼きのタヌキそっくりの三段腹が自慢の私にとっては
一度で良いからスマートな体が欲しい!
のだ。
階段を登っても息が切れない。ちょっと走っても息が切れない。
軽快な動きができる体を夢みるが、食べる事が好きで運動嫌いな私には
無理なのらー (TT)
というわけで、今回は、ハードディスクの健康診断の話をしたいと思います。
| 2011/10/8 追加 |
|---|
2005年の頃は医者から軽度高脂血症と注意されるほど、デブデブだった。
これを書いた2007年1月も、痩せたとはいえ、それなりに
お肉がついていた。
でも、今ではすっかり痩せてしまい、スマートになったが
同時に貧相にもなってしまったのだ (^^)
|
ハードディスク(HDD)のSMARTとは
「SMART」とは以下の言葉の略になる。
「Self-Monitoring, Analysis and Reporting Technology」だ。
つまり、SMARTとは、ハードディスクが自分自身の状態を診断し、
劣化の状態を報告してくれる技術の事なのだ。
そして、ハードディスク診断ソフトでは、SMARTによって得られた
劣化の度合の数値から、ハードディスクの故障の時期を予想するのだ。
SMARTは、hdparmの事で、ハードディスクの事を調べている時に知ったのだ。
hdparmのコマンドについては「システム奮闘記:その54」をご覧ください。
(hdparmコマンドでハードディスクの入出力(I/O)の設定)
LinuxでSMARTを活用したハードディスク診断ソフトがあるというのだ。
「smartmontools」と言うソフトだ。
http://smartmontools.sourceforge.net/からダウンロードする。
最初の壁にぶち当たった。
英語の壁だった (--;;
システム関係で、2006年になって英語と接する機会が増えた。
英語嫌いの私には悪夢だ・・・。
| 留学生の大変さが少しわかった |
|---|
海外へ留学する人は凄い上、大変だなぁと思っていたが
大変さが実感として湧かないため、漠然とした感じで
「大変だなぁ」と思っていた。
だが、2006年になってから、システム関係で英語の資料を読む機会が増え
英語で新しい知識を吸収する大変さを実感する事になった。
まだ、私の場合、探せば、日本語の情報も出てきたりするので、
マシかと思うが、日本語の情報が遮断された状態で、
英語で新しい知識を学ぶ留学生は、私の想像を絶する大変さだと思う。
そういう意味では、1200年前の阿倍仲麻呂のように唐へ留学し、
超難関の官僚登用試験の科挙に合格したのは、驚愕に値する事だと思う。
|
英語ができなくても、関西弁が話せれば良いのだ。と開きなおる (^^)
smartmonitoolsのインストール
さて、smartmontools のインストールを行う。
バージョンは「smartmontools-5.36」だ。
実は、2006年12月20日に、5.37のバージョンが出たのだが、
この実験を行っていたのが、それ以前な上、5.36と5.37とでは大きな違いがある。
何が違うかについては、後述しています。
インストールは、私の好みでソースコンパイルを行う。
といっても構える必要は全くない。
実は、ご丁寧に、Linuxのディストリビューションごとに
configure で使うオプションが、INSTALLファイルに書かれているのだ。
| INSTALLファイルの中身を抜粋 (smartmontools-5.36) |
|---|
Debian:
If you don't want to overwrite any distribution package, use:
./configure
Filesystem Hierarchy Standard (FHS, http://www.pathname.com/fhs/):
./configure --sbindir=/usr/local/sbin \
--sysconfdir=/usr/local/etc \
--mandir=/usr/local/man \
--with-initscriptdir=/usr/local/etc/rc.d/init.d \
--with-docdir=/usr/local/share/doc/smartmontools-VERSION
Red Hat:
./configure --sbindir=/usr/sbin \
--sysconfdir=/etc \
--mandir=/usr/share/man \
--with-initscriptdir=/etc/rc.d/init.d \
--with-docdir=/usr/share/doc/smartmontools-VERSION
Slackware:
If you don't want to overwrite any "distribution" package, use:
./configure
Otherwise use:
./configure --sbindir=/usr/sbin \
--sysconfdir=/etc \
--mandir=/usr/share/man \
--with-initscriptdir=/etc/rc.d \
--with-docdir=/usr/share/doc/smartmontools-VERSION
|
「-sbin/dir=」は、root(管理者)が動かす実行ファイルの置場
「--sysconfdir」は、設定ファイルの置場
「--with-initscriptdir」は、起動する際に動かすスクリプトの置場
「--with-docdir」は、ドキュメントの置場
./configure -helpを使えば、オプションと、その意味が出てきます。
|
もし、オプションの意味がわからなくても、丸写しでもOKだ。
というわけで、ソースコンパイルを行った。
smartmontoolsを実行
さて、smartmontools を実行させてみる。
smartmontools という実行ファイルがあるのではなく、
2つのソフトが入っているのだ。
smartctlというsmartdの2つだ。
この違いは、READMEファイルに書かれている。
| READMEファイルの中身 |
|---|
== CONTENTS ==
The suite contains two utilities:
smartctl is a command line utility designed to perform S.M.A.R.T. tasks
such as disk self-checks, and to report the S.M.A.R.T. status of
the disk.
smartd is a daemon that periodically monitors S.M.A.R.T. status and
reports errors and changes in S.M.A.R.T. attributes to syslog.
|
smartctlは、ハードディスクの診断を行うのと、SMARTの値を表示させる物だ。
smartdは、デーモンで、定期的にSMARTの値の状態を監視して、
エラーなどが出たら、syslogに記録する物だ。
|
さて、smartctlコマンドを使ってハードディスクの状態を
見てみる事にするが、その前に、ハードディスクの年代に注意が必要だ。
自己診断機能(SMART)は、UltraATA3から搭載される機能になったため、
smartmontoolsが使えるのは、以下のハードディスクの制限がある。
| man smartctl の結果を抜粋 |
|---|
smartctl controls the Self-Monitoring, Analysis and Reporting
Technol-ogy (SMART) system built into many ATA-3 and later ATA,
IDE and SCSI-3 hard drives. The purpose of SMART is to monitor
the reliability of the hard drive and predict drive failures,
and to carry out different types of drive self-tests.
This version of smartctl is compatible with ATA/ATAPI-7 and
earlier standards (see REFERENCES below)
|
これを読めば、IDEのハードディスクは、ATA3以降の規格と
SCSIの場合だと、SCSI3以降となる。
2006年、現在、販売されているハードディスクなら問題ないだろう。
だが、他にも利用する際の注意点が必要だ。
|
| INSTALLファイルの中身の抜粋 |
A) Linux
Any Linux distribution will support smartmontools if it has a
kernel version greater than or equal to 2.2.14. So any recent
Linux distribution should support smartmontools.
|
Linuxでsmartmontools使う場合、カーネルのバージョンが
2.2.14以上である事だ。
2006年では、2.6系が主流なので問題はないが、古いLinuxサーバーだと
古いカーネルを使い続けている場合もありうるため注意が必要かも
|
IDEのハードディスクでもUltraATA3以降でないと使えないのだ。
もし、UltraATA3以前のディスクの場合、以下のように「使えません」と出る。
UltraATA3以前のディスクで smartmontoolsを使った場合
実験では「Multiword DMA2」を使いました |
|---|
[root@old-machine]# smartctl -i /dev/hda
smartctl version 5.36 [i586-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF INFORMATION SECTION ===
Device Model: WDC AC32500H
Serial Number: WD-WT3601440441
Firmware Version: 12.07H12
User Capacity: 2,559,836,160 bytes
Device is: Not in smartctl database [for details use: -P showall]
ATA Version is: 1
ATA Standard is: Exact ATA specification draft version not indicated
Local Time is: Wed Dec 27 13:18:24 2006 JST
SMART is only available in ATA Version 3 Revision 3 or greater.
We will try to proceed in spite of this.
SMART support is: Ambiguous - ATA IDENTIFY DEVICE words 82-83 don't show if SMART supported.
A mandatory SMART command failed: exiting. To continue, add one or more '-T permissive' options.
|
こんな感じでエラーが出る。
古いハードディスクは使えない事がわかる。
そして、UltraATA3以降であっても、自己診断する項目の数は、
新しいパソコン(ハードディスク)ほど多くなっている。
さて、smartctlを使って、2004年に購入したパソコンの
ハードディスクの状態を見てみようとしたら・・・
エラーが出た!!
さが、慌てない。エラーの内容を見てみる。
| エラーの内容 |
|---|
[root@server]# smartctl -i /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF INFORMATION SECTION ===
Model Family: Seagate Barracuda 7200.7 and 7200.7 Plus family
Device Model: ST380011A
Serial Number: 3JVBBQ05
Firmware Version: 8.01
User Capacity: 80,026,361,856 bytes
Device is: In smartctl database [for details use: -P show]
ATA Version is: 6
ATA Standard is: ATA/ATAPI-6 T13 1410D revision 2
Local Time is: Wed Dec 27 13:49:33 2006 JST
SMART support is: Available - device has SMART capability.
SMART support is: Disabled
SMART Disabled. Use option -s with argument 'on' to enable it.
[root@server]#
|
青い部分の表示で、SMART機能を無効にしている事がわかる。
BIOSの設定で、有効・無効もしているみたいだが、
赤い部分に書いているように、smartctlコマンドに
「-s」オプションを使えば、有効にする事ができる。
|
そして、SMART機能を有効にしてみる。
| SMART機能を有効にする |
|---|
[root@server]# smartctl -s on /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF ENABLE/DISABLE COMMANDS SECTION ===
SMART Enabled.
|
「-s」オプションの後ろに「on」とハードディスクのデバイス名を書けば
SMART機能が有効になる。
|
さて、これでSMART機能が有効になった。
早速、ハードディスクの状態を見てみる事にした。
smartctlコマンドに「-A」オプションをつけて、その後ろに
見たいハードディスクのデバイス名を書くと、そのハードディスクの
状態を見る事ができる。
| 2004年に購入したパソコンの場合の結果 |
|---|
[root@server]# smartctl -A /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
3 Spin_Up_Time 0x0027 252 252 063 Pre-fail Always - 113
4 Start_Stop_Count 0x0032 253 253 000 Old_age Always - 1
5 Reallocated_Sector_Ct 0x0033 253 253 063 Pre-fail Always - 0
6 Read_Channel_Margin 0x0001 253 253 100 Pre-fail Offline - 0
7 Seek_Error_Rate 0x000a 253 252 000 Old_age Always - 0
8 Seek_Time_Performance 0x0027 243 235 187 Pre-fail Always - 64942
9 Power_On_Minutes 0x0032 248 248 000 Old_age Always - 969h+31m
10 Spin_Retry_Count 0x002b 252 252 157 Pre-fail Always - 0
11 Calibration_Retry_Count 0x002b 252 252 223 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 253 253 000 Old_age Always - 32
192 Power-Off_Retract_Count 0x0032 253 253 000 Old_age Always - 0
193 Load_Cycle_Count 0x0032 253 253 000 Old_age Always - 0
194 Temperature_Celsius 0x0032 253 253 000 Old_age Always - 13
195 Hardware_ECC_Recovered 0x000a 253 252 000 Old_age Always - 847
196 Reallocated_Event_Count 0x0008 253 253 000 Old_age Offline - 0
197 Current_Pending_Sector 0x0008 253 253 000 Old_age Offline - 0
198 Offline_Uncorrectable 0x0008 253 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0008 199 199 000 Old_age Offline - 0
200 Multi_Zone_Error_Rate 0x000a 253 252 000 Old_age Always - 0
201 Soft_Read_Error_Rate 0x000a 253 252 000 Old_age Always - 6
202 TA_Increase_Count 0x000a 253 252 000 Old_age Always - 0
203 Run_Out_Cancel 0x000b 253 252 180 Pre-fail Always - 0
204 Shock_Count_Write_Opern 0x000a 253 252 000 Old_age Always - 0
205 Shock_Rate_Write_Opern 0x000a 253 252 000 Old_age Always - 0
207 Spin_High_Current 0x002a 252 252 000 Old_age Always - 0
208 Spin_Buzz 0x002a 252 252 000 Old_age Always - 0
209 Offline_Seek_Performnce 0x0024 253 253 000 Old_age Offline - 0
99 Unknown_Attribute 0x0004 253 253 000 Old_age Offline - 0
100 Unknown_Attribute 0x0004 253 253 000 Old_age Offline - 0
101 Unknown_Attribute 0x0004 253 253 000 Old_age Offline - 0
[root@server]#
|
これを見た時、青い部分の温度の部分以外は
わからへん (TT)
だった。
何せ「Spin_Up_Time」と書かれていても、何を意味しているのかが、
ハードディスクの知識がないため、見当すらつかない。
それだけでなく、数値の見方も、よくわからない。
| 2004年に購入したパソコンの場合の結果 |
|---|
[root@server]# smartctl -A /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
3 Spin_Up_Time 0x0027 252 252 063 Pre-fail Always - 113
4 Start_Stop_Count 0x0032 253 253 000 Old_age Always - 1
(以下、省略)
|
赤色のVALUEは「測定値」なのはわかる。
そして、ピンクのTHRESHは「閾値」(しきい値)で、
安全領域と危険領域との境界の値だというのもわかる。
しかし、両方とも、何を基準に、その値にしているのかは、わからない。
その上、青のWORSTだが、よく意味がわからない。
最悪値と訳している人もおられるが、何が「悪い値」なのかがピンとこない。
|
知っている人が見れば、よくわかる情報であっても、
私にとっては、どんな情報が載っているのかが見えてこないだけに、
あえなく挫折してしまったのだ。
ハードディスク(HDD)の仕組みを勉強
どうやら、ハードディスクの事を勉強せんとアカンようだ。
そこで次の本を読む事にした。
「ハードディスク究極活用」(飯島弘文:翔泳社)
だが、ハードディスクのチェック項目などの話は載っていなかったが、
Windows用のハードディスク診断ソフト「SmartHDD Pro」について書いてあった。
インターコム社の「SmartHDD Pro」だ。もちろん商用だ。
http://www.intercom.co.jp/
早速、お試し版をインストールする事にした。
使ったパソコンは、2003年に購入した物だ。
| SmartHDD Proの画面 |
|---|
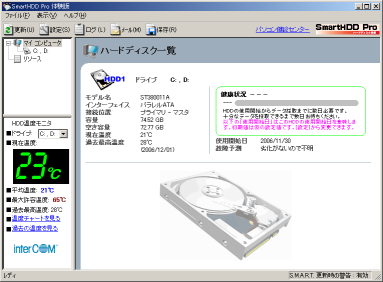 |
これを見て「温度表示がされている!」と思った。
| SmartHDD Proの温度表示 |
|---|
 |
(注意)
SMART機能がついたATA3以降のハードディスクでも、古いタイプでは
温度の監視機能がついていないのもある。
|
この温度だが、1日単位のグラフにする事もできる。
数日間のハードディスクの平均温度のグラフだ。
| SmartHDD Proの温度表示 |
|---|
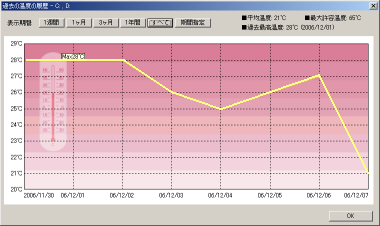 |
28度の地点から開始されてる。全く問題のない温度だ。
12月に入ったばっかりは、暖冬を通り超えた温かさだったが、
その後、少し寒くなったせいか、わずかに温度が下がっている。
室温の微妙な違いを、ここではとらえているようだ。
|
次にハードディスクの情報を見てみる事にした。
| SmartHDD Proの画面 |
|---|
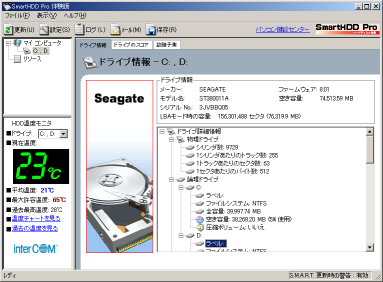 |
|
ハードディスクの情報やドライブの情報などが載っている。
|
ハードディスクの情報を拡大した。
| SmartHDD Proの画面 |
|---|
 |
|
メーカー名、モデル名、容量などが表示される。
|
GUI操作なので、手軽に表示できる。
次に、ハードディスクの劣化度合を見てみる事にした。
| SmartHDD Proの画面 |
|---|
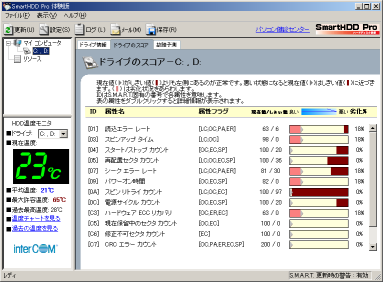 |
各項目ごとの劣化度合を見る事ができる。
項目数は、ハードディスクによって異なる。
もちろん、古いディスクほど項目は少ないのだ。
|
さて、拡大してみる。
| SmartHDD Proの画面 |
|---|
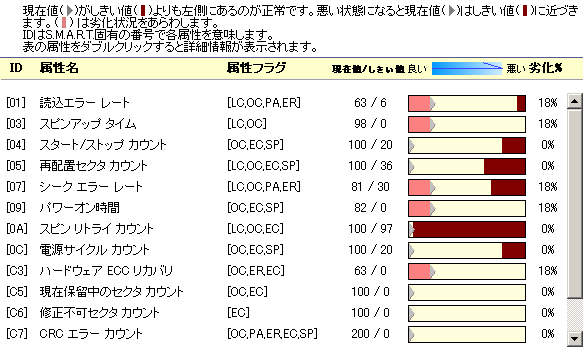 |
各項目ごとの劣化度合が視覚的に見る事ができる。
劣化度合がパーセントで表示されるのも、わかりやすい感じがする。
(何を根拠にパーセントを出しているのかは、わからんのだが・・・)
項目IDと、それに対応した項目の説明がある。
日本語なので読めるのだが、ハードディスクの知識がないと
内容が理解できない物もある。
この項目については、後述しています。
|
このソフトは、ハードディスクがオシャカになる時期を予想してくれる。
予想している画面は以下の通りだ。
| SmartHDD Proの画面 |
|---|
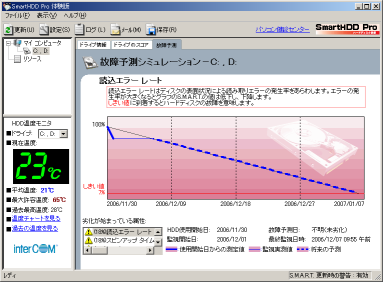 |
ただ、予想といっても、ソフトをインストールした時が
ハードディスクの購入時期という風に考える。
そのため、18%の劣化があった項目の場合、上の図のように
測定開始時から、1日、2日で18%の劣化が生じた形になり、
急激な劣化が起こるようなグラフになってしまう。
|
さて、このソフトの便利なのは、劣化が進行して「ヤバイ」と判断すると
メールで知らせる仕掛けになっている。
その設定が以下の画面だ。
| SmartHDD Proの画面 |
|---|
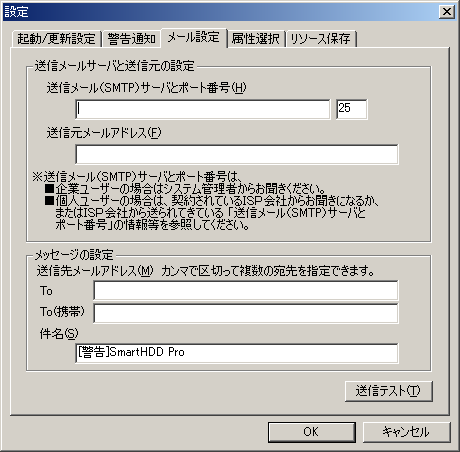 |
メールサーバーを設定し、ハードディスクがオシャカになる時期を
メールで送る仕掛けになっている。
システム管理者宛にメールを届くようにすれば、システム管理者が
事前に把握できるため、計画的にハードディスクの交換も可能になる。
|
ハードディスクの自己診断のSMARTの項目を見る
「SmartHDD pro」というソフトは、視覚的で見やすいソフトだとわかった。
だが、smartmontoolsと同様、ハードディスクの自己診断機能(SMART)の
測定値や測定項目について、少しでも理解しておかなければ、
ハードディスクの、どこが、どう悪いのかがわからない。
SMARTには、いくつかの自己診断の項目があるのだが、
ネットで調べてみる事にした。するとウィキペディアにあった。
http://ja.wikipedia.org/wiki/Self-Monitoring,_Analysis_and_Reporting_Technology
項目の説明が日本語で書かれている。
だが、「stab」としか書かれていない項目のある。
そこで他のサイトも調べてみる。
http://www.linuxjournal.com/article/6983
http://www.jinaka.com/pc/smartmontools/information_list.html
http://www.ariolic.com/activesmart/smart-attributes/
さて、これら調べた結果と、smartmontoolsのsmartctlで
出力した結果と比較して見る事にした。
まずは、測定値などの項目から。
| 2004年に購入したパソコンの場合の結果 |
|---|
[root@server]# smartctl -A /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
3 Spin_Up_Time 0x0027 252 252 063 Pre-fail Always - 113
4 Start_Stop_Count 0x0032 253 253 000 Old_age Always - 1
(以下、省略)
|
赤色のVALUEは「測定値」なのはわかる。
そして、ピンクのTHRESHは「閾値」(しきい値)で、
安全領域と危険領域との境界の値だというのもわかる。
青のWORSTだが、今までの測定した中で、
一番悪かった測定値を表示させている。
さて、この3つの値だが、測定範囲を「0〜253」としている。
そして、253だと最良で、劣化が進むごとに値が減るという形になる。
もちろん、この読み方は全ての項目に当てはまるわけではなく
温度表示や、電源を入れてからの経過時間には、当てはまらない。
RAW_VALUEなのだが、これは測定した値そのものだ。
温度測定や、電源を入れてからの経過時間の場合、この値を見る。
|
次に残りの測定値の名称を見てみる。
| 2004年に購入したパソコンの場合の結果 |
|---|
[root@server]# smartctl -A /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
3 Spin_Up_Time 0x0027 252 252 063 Pre-fail Always - 113
4 Start_Stop_Count 0x0032 253 253 000 Old_age Always - 1
(以下、省略)
|
赤色のTYPEだが、危険な状態になる条件の違いを表す。
「Old-age」の場合、測定値が「0」になった場合、危険な状態になり
「Pre-fail」の場合は、閾値(しきい値)を超えた時、危険な状態になる。
もし、危険な状態になれば「fails」と出るようで、これが出ると
24時間以内にハードディスクがオシャカになるという警告だ。
読みづらい英文を読んだため、英文読解に自信がないので、
一応、私の読解に間違えがあっては良くないので、情報元の記述も書きました。
|
「TYPE」の説明(英文を抜粋)
引用元 http://www.linuxjournal.com/article/6983 |
The TYPE of the Attribute indicates if Attribute failure means
the device has reached the end of its design life (Old_age) or
it's an impending disk failure (Pre-fail). For example,
disk spin-up time (ID #3) is a prefailure Attribute.
If this (or any other prefail Attribute) fails,
disk failure is predicted in less than 24 hours.
|
うーん、ぎこちない日本語になってしまう (--;;
だが、開き直る私。だって・・・
国語も英語も苦手だもーん (^^)V
なのだ。
理系ではなく「非文系」のため、理系に進んだ私なのだ (^^)
さて、だいたい結果出力の見方はわかったのだが、肝心のSMARTの項目だ。
なので、1個づつ見ていく事にする。
もちろん、省略している項目もあります。
それだけでなく、見落としている項目もあるかもしれませんが、
そこは見逃してくださいね (^^;;
| SMARTの自己監視の項目 |
|---|
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
3 Spin_Up_Time 0x0027 252 252 063 Pre-fail Always - 113
4 Start_Stop_Count 0x0032 253 253 000 Old_age Always - 1
5 Reallocated_Sector_Ct 0x0033 253 253 063 Pre-fail Always - 0
6 Read_Channel_Margin 0x0001 253 253 100 Pre-fail Offline - 0
7 Seek_Error_Rate 0x000a 253 252 000 Old_age Always - 0
8 Seek_Time_Performance 0x0027 243 235 187 Pre-fail Always - 64942
9 Power_On_Minutes 0x0032 248 248 000 Old_age Always - 969h+31m
10 Spin_Retry_Count 0x002b 252 252 157 Pre-fail Always - 0
11 Calibration_Retry_Count 0x002b 252 252 223 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 253 253 000 Old_age Always - 32
192 Power-Off_Retract_Count 0x0032 253 253 000 Old_age Always - 0
193 Load_Cycle_Count 0x0032 253 253 000 Old_age Always - 0
|
「ID 3」の「Spin_Up_Time」はハードディスクを回転開始させて
規定の回転数(5600rpmとか7200RPM)に達するまでの平均時間。
測定値では元気一杯の「252」だ!
「ID 4」の「Start_Stop_Count」は、 ディスクの回転に使う
スピンドルモータの回転/停止の回数
「ID 5」の「Reallocated_Sector_Ct」だが、「Real located」と区切るのか
「Re allocated」で区切るのかで、読み方が変わってくる。
「Real」の場合だと、空白で区切るので、後者で「再配置」の意味になる。
この項目は不良セクタがあるため、別の所へ再配置した数の意味だ。
測定値は「253」で、全く問題はない
この値が悪くなると、読み書きの速度に影響が出てくる。
「ID 7」の「Seek_Error_Rate」は磁気ヘッドがデータのあるトラックへ
移動する際に、移動に失敗した割合。これが発生すると
ハードディスクの表面や機械的なシステムに問題がある可能性がある。
「ID 8」の「Seek_Time_Performance」は磁気ヘッドがシーク作業を行う
平均時間。これが悪くなると、ハードディスクの機械的なシステムに
問題があるという事だ。
「ID 9」の「Power_On_Minutes」は工場出荷時から現在まで、
ハードディスクが稼働している(電気が通っている)時間だ。
「ID 10」の「Spin_Retry_Count」は、規定の速度のままで
スピンアップしようとした回数。ところでスピンアップって何?
|
うーん、ほとんど色々なサイトの丸写しの説明なのだが
それしか情報がないもーん (^^;;
ハードベンダーなどから直接情報が手に入らないため、2次、3次、4次情報、
(本当の所、何次情報かわからないが)などを照らし合わせるしかないのだ。
伝言ゲームのように、最初(1次情報)と最後(私が入手する所)では
内容が大きく異なる可能性も否定できないのだが、入手経路がないため
いくつかの情報を照らし合わせるしかないのだ・・・。
さて、SMARTの項目を引続き、見ていく事にする。
| SMARTの自己監視の項目 |
|---|
194 Temperature_Celsius 0x0032 253 253 000 Old_age Always - 13
195 Hardware_ECC_Recovered 0x000a 253 252 000 Old_age Always - 847
196 Reallocated_Event_Count 0x0008 253 253 000 Old_age Offline - 0
197 Current_Pending_Sector 0x0008 253 253 000 Old_age Offline - 0
198 Offline_Uncorrectable 0x0008 253 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0008 199 199 000 Old_age Offline - 0
200 Multi_Zone_Error_Rate 0x000a 253 252 000 Old_age Always - 0
201 Soft_Read_Error_Rate 0x000a 253 252 000 Old_age Always - 6
202 TA_Increase_Count 0x000a 253 252 000 Old_age Always - 0
203 Run_Out_Cancel 0x000b 253 252 180 Pre-fail Always - 0
204 Shock_Count_Write_Opern 0x000a 253 252 000 Old_age Always - 0
205 Shock_Rate_Write_Opern 0x000a 253 252 000 Old_age Always - 0
207 Spin_High_Current 0x002a 252 252 000 Old_age Always - 0
208 Spin_Buzz 0x002a 252 252 000 Old_age Always - 0
209 Offline_Seek_Performnce 0x0024 253 253 000 Old_age Offline - 0
|
「ID 194」の「Temperature_Celsius」はハードディスクの温度。
これはRAW値を見た方が良い。単位は摂氏なので日本人にはわかりやすい。
「ID 195」の「Hardware_ECC_Recovered」はハードディスク上の
ECC(誤り訂正)を行った際に、検出した数を出す。
「ID 196」の「Reallocated_Event_Count」は、不良セクタのために
代わりのセクタを用意した回数。
「ID 197」の「Current_Pending_Sector」は、現在の不安定セクタ数。
「不良」ではなく「不安定」という表現から、
「不良」になりかけているセクタの事だと思う。
もし、読み込みが成功したら、この値は減少するが、
読み込みに失敗すれば、「不良」セクタとなる。
「ID 198」の「Offline_Uncorrectable」は、回復不可能な不良セクタの数
この数が増えると、ディスク表面に問題があるといえる。
「ID 199」の「UDMA_CRC_Error_Count」は、UltraDMAモードでの
データ転送時、データ転送の誤り訂正(CRC符号)で、エラーが出た時の数。
「ID 200」の「Multi_Zone_Error_Rate」は、セクタへの書き込みの際の
エラーの発生割合。この割合が高いとディスク表面に問題がある。
「ID 201」の「Soft_Read_Error_Rate」は、ソフトウェアが
ディスクからの読み取りの際に発生したエラーの割合だ。
|
さて、「ID 195」のECCだが、おそらくハードディスクのセクタごとに
用意される、エラー対策のためのECCだと思う。
実は、ハードディスクのセクタには、データが入る部分と、
そのデータの整合性をチェックするECCの領域がある。
| ハードディスクのセクタ |
|---|
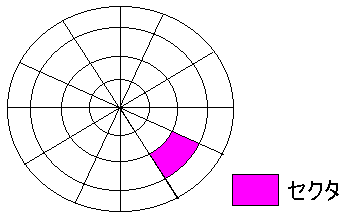 |
| ハードディスク内のECC領域 |
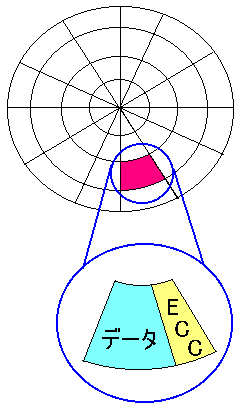 |
セクタ内のECCが何ビット(何バイト)かは、ハードディスクの種類による。
hdparm コマンドで、ECCのビット数(バイト数)が表示できる。
| セクタ内のECCのバイト数を見る |
|---|
[root@server]# /sbin/hdparm -i /dev/hda
/dev/hda:
Model=Maxtor 6Y080P0, FwRev=YAR41BW0, SerialNo=Y219K6HE
Config={ Fixed }
RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=57
BuffType=DualPortCache, BuffSize=7936kB, MaxMultSect=16, MultSect=16
CurCHS=16383/16/63, CurSects=16514064, LBA=yes, LBAsects=160086528
IORDY=on/off, tPIO={min:120,w/IORDY:120}, tDMA={min:120,rec:120}
PIO modes: pio0 pio1 pio2 pio3 pio4
DMA modes: mdma0 mdma1 mdma2
UDMA modes: udma0 udma1 udma2 udma3 udma4 *udma5 udma6
AdvancedPM=yes: disabled (255) WriteCache=enabled
Drive conforms to: (null): 1 2 3 4 5 6 7
|
赤い部分が、1セクタごとに付属するECC(誤り訂正符号)のバイト数になる。
このハードディスクでは、57バイトだ。
|
ハードディスクのデータが正しく読み書きできるようにするため、
色々な工夫をしているのが感じ取れる。
CRCを使った誤り訂正の項目もある。
これはデータ転送時に使われる。
「システム奮闘記:その54」で紹介しましたが、IDEのディスクの場合、
ディスクとマザーボードの間は、IDEケーブルで結ばれている。
データは16ビットづつ、並行に伝送される。
ケーブルの途中で、並行している他の回線の信号から発生する電磁波や
他の電磁波の影響で、信号に雑音(ノイズ)が入る事もある。
そのため、正確にデータが転送されない場合が出てくるため、
正確にデータ転送を行ったかどうかをチェックするための、CRCビットだ。
| ハードディスクのCRCビットの役目 |
|---|
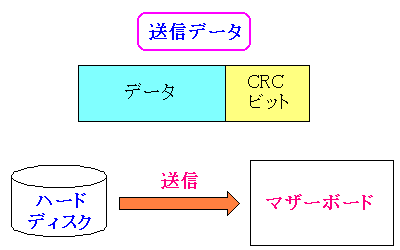 |
このCRCビットだが、ATA3からサポートされるようになった。
現行のIDEのハードディスクなら問題なくサポートされている。
それ以前は、転送エラーを検出できないため、SCSIよりも信頼性が
低いとされた。
CRCビットだが、これもECCビットと同様に各セクタに配置されている。
データ転送は、1セクタごとに転送されるので、1セクタごとのデータの
チェックに使われるのだ。
|
これを見ていると、正確にデータの保管や転送を行う事は、
口では簡単だが、技術的に難しいと素人ながらにも感じる。
それだけハードディスクが繊細で、微妙なバランスの下で
稼働している事が伺える。
さて、いくつかのサイトなどを照らし合わせて、私なりに理解した
SMARTの自己診断項目を書いてみました。まぁ、丸写しの部分もありますが (^^;;
取り上げていない項目もあります。それは
私が理解できなかった項目なのだ!!
言葉では理解したつもりであっても、いざ説明しようと思うと
思ったように文章が書けないのだ。つまり全くわかっていない状態 (--;;
取り上げた項目であっても、あやふやな文章で書いている部分があり
やはりキチンと理解するのは難しいのらー!!
ところで、この項目IDは、SMARTの自己診断項目のIDなので、先に紹介した
Windows用の「SmartHDD Pro」も同じIDが表示されている。
| SmartHDD Proの画面 |
|---|
|
1つ1つの項目の意味がわかれば、何がどう悪いのかが見えてくる。
これは、LinuxでもWindowsでも同じだ。同じでないと恐いのだが・・・。
さて、smartctlの残りのオプションについて見ていく事にする。
前の方にも少し出ましたが、まずは「-i」オプションだ。
これはハードディスクの性能や製品番号などの情報を表示させる。
| smartctlの「-i」オプションの役目 |
|---|
[root@server]# smartctl -i /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF INFORMATION SECTION ===
Model Family: Maxtor DiamondMax Plus 9 family
Device Model: Maxtor 6Y080P0
Serial Number: Y219K6HE
Firmware Version: YAR41BW0
User Capacity: 81,964,302,336 bytes
Device is: In smartctl database [for details use: -P show]
ATA Version is: 7
ATA Standard is: ATA/ATAPI-7 T13 1532D revision 0
Local Time is: Sat Dec 23 17:45:27 2006 JST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
[root@server]#
|
ハードディスクの製品、シリアル番号、ファームウェア、容量
ATAのバージョン(この場合は、ATA7)が表示される。
|
次は「-t」オプション。これは自己診断を行うオプションだ。
自己診断には2種類ある。
簡易的な検査の「short」と、完全なテストの「long」がある。
「 -t」の後ろに「short」か「long」を入れる。
| smartctlの「-t short」の検査 |
|---|
[root@server]# smartctl -t short /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Short self-test routine immediately in off-line mode".
Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 2 minutes for test to complete.
Test will complete after Fri Dec 8 10:25:49 2006
Use smartctl -X to abort test.
[root@server]#
|
簡易テスト「short」の場合、2分ぐらいで終わる。
ところで、2分かかるのだが、バックグラウンドでプログラムが走るため
実行した後、すぐにコマンドプロンプトが出てくる。
|
さて、このテストの結果を見る場合は、smartctlコマンドに
「-l」オプションをつける。
| 簡易検査の結果を見てみる |
|---|
[root@server]# smartctl -l selftest /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 1589 -
|
|
青い部分にある通り、検査の結果、問題なしだった。
|
次に、完全検査の「long」を行ってみる。
| smartctlの「-t long」の検査 |
|---|
[root@server]# smartctl -t long /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Extended self-test routine immediately in off-line mode".
Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 37 minutes for test to complete.
Test will complete after Fri Dec 8 11:08:00 2006
Use smartctl -X to abort test.
|
完全テスト「long」の場合、37分ぐらいで終わる。
37分は、あくまでもこのハードディスクの場合であって、
他のハードディスクの場合、1時間くらいかかる場合もある。
これはディスクの容量に依存するためだ。
テストの時間中は、バックグラウンドでプログラムが走る。
もし、テストを中断させる場合は、赤い部分に書かれている通り
「smartctl -X /dev/hda」を行えば、検査を中断する事ができる。
|
さて、完全検査の結果を見てみる。
これも簡易検査と同様に、smartctlコマンドの後ろに
「-l」オプションをつける
| 完全検査の結果を見てみる |
|---|
[root@server]# smartctl -l selftest /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 1593 -
# 2 Extended offline Completed without error 00% 1592 -
# 3 Short offline Completed without error 00% 1590 -
|
|
赤い部分が完全テストの結果だ。問題なしだ。
|
ちなみに、自己診断のテスト中に「-X」オプションを使って中断させると
以下のようになる。
| 自己診断テストを中断させると |
|---|
| 「-X」オプションをつけて中断させる |
[root@server]# smartctl -X /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Abort SMART off-line mode self-test routine".
Self-testing aborted!
|
| 「-l」オプションをつけて診断結果を見る |
[root@server]# smartctl -l selftest /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 1593 -
# 2 Extended offline Aborted by host 40% 1590 -
|
青い部分は、完全テストを中断した場合だ。
中断した場合もリストに載るのだ。
|
自己診断の検査結果を出す「-l」オプションだが、
上ではオプションの後ろに「selftest」にした。
これは自己診断の検査ログを出力の意味になる。
今まで「-l」オプションは、自己診断の検査結果を出力すると書いたが
実は、自己診断の検査ログを出力するためのオプションだ。
「-l」オプションの後ろに「error」をつければ、エラーログを表示させる。
今、手元には壊れそうなハードディスクがない。
そのため「-l error」をつけても、何も出力されない。
| 「smartctl -l error /dev/hda」の出力結果 |
|---|
[root@server]# smartctl -l error /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Error Log Version: 1
No Errors Logged
|
|
ハードディスクは、どこも悪くないため、赤い表示になる。
|
さて、実際にハードディスクの自己診断テストを行って、
合格か不合格かを表示させるオプションがある。
それは「-H」オプションだ。
| 「-H」オプションの出力結果 |
|---|
[root@server]# smartctl -H /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
|
ハードディスクは、どこも悪くないため、赤い部分の「合格」が表示される。
だが、不合格と表示された場合、24時間以内にハードディスクが
オシャカになるかもしれないので、急いで、バックアップをとって
ハードディスクを交換した方が良いようだ。
|
ここで、smartctlコマンドのオプションの整理を行ってみる。
| オプションの種類と内容 |
|---|
| オプション | 内容 |
| -s |
SMARTを有効にするオプション
「-s」の後ろに「on」をつける。
|
| -t |
自己診断テストを行う
「-t short」だと簡易テスト
「-t long」だと完全テストになる。
|
| -X |
自己診断テストを中断させる |
| -l |
自己診断テストのログの表示を行う
「-l selftest」だと自己診断テストのログ
「-l error」だとエラーがある場合の表示になる。
|
| -H |
自己診断テスト後、テストの合否を出すための物 |
| -i |
ハードディスクの各種情報の出力
機種名、シリアル番号、容量、ファームウェアのバージョンなど |
| -A |
SMARTの監視項目と測定値や閾値の表示 |
他にもオプションがあるのだが
理解できへんかった (TT)
なのだ。
説明文が日本語だろうが英語だろうが、説明文の中にある
コンピューター用語などを理解していないと、どういう事が書いているのか
理解できないのだ。
そのため、自分が理解できる範囲でしかオプションの紹介ができないのだ。
さて、自己診断テストだが、簡易の「short」と完全の「long」がある。
この2つの違いは何だろうか。考えてみれば
謎だ・・・
smartmontoolsの資料などを調べても、簡易と完全としか書かれた資料しか
見つからない。
「short」と「long」の違いが、単に「簡易」と「完全」といった
形容詞的な表現の違いではなく、具体的に何がどう違うのか知りたくなった。
そこで思いついたのは
ソースを読めばええやん!
だった (^^;;
相変わらず単純な発想でしかない私。
さて、smartmontoolsのソースを見る。
ソースはバージョン「5.36」を読む事にする。
2006年12月に「5.37」にバージョンが上がったが、5.36を読む。
それには訳がある。
5.37はC++で書かれているもーん (^^;;
そうなのです。C++言語は、全く読めないのだ。
まぁ、C言語といっても、ftpクライアントソフトを書いて「やったー!」と
喜んでいるようなレベルなのだが、それでもC言語の場合「なんとかなるかも」
という淡い期待がある。しかし、C++の場合、淡い期待すら持てないのだ。
早速、smartctl.cのソースを見てみる。
| smartctl.c の中身 (Ver5.36) |
|---|
case 't':
if (!strcmp(optarg,"offline")) {
con->smartexeoffimmediate = TRUE;
con->testcase = OFFLINE_FULL_SCAN;
} else if (!strcmp(optarg,"short")) {
con->smartshortselftest = TRUE;
con->testcase = SHORT_SELF_TEST;
} else if (!strcmp(optarg,"long")) {
con->smartextendselftest = TRUE;
con->testcase = EXTEND_SELF_TEST;
|
オプション「-t」の部分の処理だ。
そして「short」と「long」の部分の処理があるが、
単に変数に値を代入している部分しか、ここでは記述されていない。
「SHORT_SELF_TEST」や「EXTEND_SELF_TEST」の値は、
atacmds.h のヘッダーファイルで、マクロ定義されている。
|
| atacmds.h の中身 (Ver5.36) |
// Sector Number values for ATA_SMART_IMMEDIATE_OFFLINE Subcommand
#define OFFLINE_FULL_SCAN 0
#define SHORT_SELF_TEST 1
#define EXTEND_SELF_TEST 2
|
この先、shortやlongの処理は、atacmds.cで行われているのだろうと思った。
そこで、atacmds.c のソースを見てみる事にした。
| atacmds.cのソース (Ver5.36) |
|---|
// This is the way to execute ALL tests: offline, short self-test,
// extended self test, with and without captive mode, etc.
int ataSmartTest(int device, int testtype, struct ata_smart_values *sv) {
char cmdmsg[128],*type,*captive;
int errornum, cap, retval, select=0;
(途中、省略)
// Now send the command to test
errornum=smartcommandhandler(device, IMMEDIATE_OFFLINE, testtype, NULL);
|
赤い部分で、自己診断テストの関数の記述だとわかる。
青い部分は、ハードディスクに自己診断のための値などを送る命令だ。
さて、このsmartcommandhandler()関数は、同じ atacmds.cの中で
定義されている関数なのだ。
|
smartcommandhandler()関数の定義を見てみる
atacmds.h の中身 (Ver5.36) |
// This function provides the pretty-print reporting for SMART
// commands: it implements the various -r "reporting" options for ATA
// ioctls.
int smartcommandhandler(int device, smart_command_set command, int select, char *data){
int retval;
(途中、省略)
// now execute the command
switch (con->controller_type) {
case CONTROLLER_3WARE_678K:
case CONTROLLER_3WARE_678K_CHAR:
case CONTROLLER_3WARE_9000_CHAR:
retval=escalade_command_interface(device, con->controller_port-1, con->controller_type, command, select, data);
if (retval && con->controller_port<=0)
pout("WARNING: apparently missing '-d 3ware,N' disk specification\n");
break;
case CONTROLLER_MARVELL_SATA:
retval=marvell_command_interface(device, command, select, data);
break;
default:
retval=ata_command_interface(device, command, select, data);
|
青い部分は、RAIDでもなく、S-ATAでもない場合に、自己診断テストの際に
実行される関数だ。
このata_command_interface()だが、smartctlをLinux上で動かす場合、
os_linux.c で定義されたata_command_interface()関数を使う。
|
さて、os_linux.cのソースの中身を見てみる事にする。
| os_linux.cのソースの中身 (Ver5.36) |
|---|
// huge value of buffer size needed because HDIO_DRIVE_CMD assumes
// that buff[3] is the data size. Since the ATA_SMART_AUTOSAVE and
// ATA_SMART_AUTO_OFFLINE use values of 0xf1 and 0xf8 we need the space.
// Otherwise a 4+512 byte buffer would be enough.
#define STRANGE_BUFFER_LENGTH (4+512*0xf8)
int ata_command_interface(int device, smart_command_set command, int select, char *data){
unsigned char buff[STRANGE_BUFFER_LENGTH];
// positive: bytes to write to caller. negative: bytes to READ from
// caller. zero: non-data command
int copydata=0;
const int HDIO_DRIVE_CMD_OFFSET = 4;
// See struct hd_drive_cmd_hdr in hdreg.h. Before calling ioctl()
// buff[0]: ATA COMMAND CODE REGISTER
// buff[1]: ATA SECTOR NUMBER REGISTER == LBA LOW REGISTER
// buff[2]: ATA FEATURES REGISTER
// buff[3]: ATA SECTOR COUNT REGISTER
(途中、省略)
// We are now doing the HDIO_DRIVE_CMD type ioctl.
if ((ioctl(device, HDIO_DRIVE_CMD, buff)))
return -1;
|
ata_command_interface()関数の中身を見ると、行き着く先は
青い部分の何でも屋の入出力のシステムコールのioctl()に辿り着いた。
このシステムコールを介して、自己診断を行う際に、shortかlongかを
ハードディスクに伝えているのだ。
|
うーん、ioctl()のシステムコールに辿り着いてしまった。
ここから先は、システムコールの実装を見ていく必要がある。
ここまで来ると、お手上げだ。
読者の中には「システムコールの先も追っかけてみろ!」と
思われる方もおられると思います。
なので、一応、ioctl()のシステムコールではなく、IDEのハードディスクの
ドライバのプログラムをのぞいてみる事にした。
そこを見れば、何かがわかると思ったからだ。
|
Linuxカーネル 2.4.33 にある drivers/ide/ide-disk.c の中身 |
|---|
static int smart_enable(ide_drive_t *drive)
{
ide_task_t args;
memset(&args, 0, sizeof(ide_task_t));
args.tfRegister[IDE_FEATURE_OFFSET] = SMART_ENABLE;
args.tfRegister[IDE_LCYL_OFFSET] = SMART_LCYL_PASS;
args.tfRegister[IDE_HCYL_OFFSET] = SMART_HCYL_PASS;
args.tfRegister[IDE_COMMAND_OFFSET] = WIN_SMART;
args.command_type = ide_cmd_type_parser(&args);
return ide_raw_taskfile(drive, &args, NULL);
}
static int get_smart_values(ide_drive_t *drive, u8 *buf)
{
ide_task_t args;
memset(&args, 0, sizeof(ide_task_t));
args.tfRegister[IDE_FEATURE_OFFSET] = SMART_READ_VALUES;
args.tfRegister[IDE_NSECTOR_OFFSET] = 0x01;
args.tfRegister[IDE_LCYL_OFFSET] = SMART_LCYL_PASS;
args.tfRegister[IDE_HCYL_OFFSET] = SMART_HCYL_PASS;
args.tfRegister[IDE_COMMAND_OFFSET] = WIN_SMART;
args.command_type = ide_cmd_type_parser(&args);
(void) smart_enable(drive);
return ide_raw_taskfile(drive, &args, buf);
}
static int get_smart_thresholds(ide_drive_t *drive, u8 *buf)
{
ide_task_t args;
memset(&args, 0, sizeof(ide_task_t));
args.tfRegister[IDE_FEATURE_OFFSET] = SMART_READ_THRESHOLDS;
args.tfRegister[IDE_NSECTOR_OFFSET] = 0x01;
args.tfRegister[IDE_LCYL_OFFSET] = SMART_LCYL_PASS;
args.tfRegister[IDE_HCYL_OFFSET] = SMART_HCYL_PASS;
args.tfRegister[IDE_COMMAND_OFFSET] = WIN_SMART;
args.command_type = ide_cmd_type_parser(&args);
(void) smart_enable(drive);
return ide_raw_taskfile(drive, &args, buf);
}
|
SMARTに関する記述があったが、手がかりらしい物はなかった。
カーネルのソースを見ても、目が点になる私なのだ。
|
これを見て、ソースレベルで、shortとlongの違いを知るのを諦めた私。
なので常套手段で
事務員なので、わかりませーん (^^)V
で逃げようと考え、これで終わりにしようと思ったら、
Seagate社の英語のマニュアルで、この違いが書いていた。
「Enhanced SMART - Get SMART For Reliability」のPDFファイル
http://www.seagate.com/docs/pdf/whitepaper/enhanced_smart.pdf
これには次のように書いている。
ちなみに翻訳ではなく、私の解釈なので、原文と違う事が書いています (^^;;
| 2つの違い |
|---|
shortテスト
(Quick Test) |
2分でテストができるようにしている
なので、ハードディスクの一部分のみの検査になる
少なくとも1.5Gバイトは点検している
|
longテスト
(Extended Test) |
ハードディスク全てをチェック。
テストの時間はハードディスクの容量で決まる
|
この文章は、1999年の物な上、Seagate社の技術文書なので、現在の仕様や
他社の仕様とでは違う仕様になっている可能性はあるかもしれないが、
メーカや年代は違えど、次の事は共通して言えるのではないかと思う。
shortテストは2分で終わるようにしている。
そのためハードディスクの一部分だけを点検している。
原文では「read」と書いていたので、読み込み点検をしているようだ。
longテストは、ハードディスク全体を点検している。
そのため、点検時間は、ハードディスクの容量で決まるのだ。
この時は、疑問に思わなかったのだが、Seagete社の技術資料を見て
ある事に気づいた。
Seagate社の「Enhanced Drive Self-Test」
http://www.seagate.com/docs/pdf/whitepaper/Enhanced_DST_Tech_Paper.pdf
簡易テスト「short」は、一部分しか点検していないので
測定値として使うには、不十分ではないだろうか。
アンケートの統計のように、ある程度の数に達すれば、
統計誤差が低くなるため、NHKなどの世論調査では1500人くらいで、
だいたいの目安が出る。
だが、ハードディスクの場合、どこか1ヶ所に重大な問題点があれば、
他が正常であっても、異常として感知する必要がある。
なので、一部分だけのチェックで、統計的な予想が通用するのかどうか
素人的発想では、疑問に感じる。
さて、Seagateの技術文書を読み進める。
完全検査「long」の場合、95%の正確さでハードディスクがオシャカに
なるのを予想できるという。
普通に簡易検査「short」の場合だと60〜70%の確率でしか
ハードディスクの故障が予想できないという。
だが、「Enhanced Drive Self Test」(NDST)という簡易検査の場合だと、
95%の正確さで予想できるというのだ。
まぁ、一部分の点検だけで、60〜70%の確率でディスクの故障が
予想できる事自体、これも不思議で仕方ないのだが、これ以上、
突っ込んだ話になると、いくら技術文書があったとしても、
私の頭では理解できないのらー!!
なので、深く追求する事はしない。というより「できない」のだ。 (^^;;
技術文書を読んで行くと、簡易検査のエラーログに加えて
重要な項目のログもディスク上に記録しているという。
それらのデータと比較して判断しているようだ。
これだと正確さが増すのは納得ができる。
だが、95%の数値の根拠は見えない。でも、追求したって・・・
私の頭では理解できないのらー!!
なのだ (^^)
他社のハードディスクでは、どうなっているのかは、技術文書を
読んでいないので、何とも言えないが、Seagate社のハードディスクでは
簡易テストを何度も行う事で、ハードディスクがオシャカになる時期を
予想する精度を上げているのだ。
この先の突っ込んだ話は、頭の良い人に譲りたいと思います。
頭の良い方、あとヨロピクね! (^^)
さて、SMART値の更新方法で、「online」と「offline」の分類もある。
「-A」オプションでハードディスクの状態を見た時、この2つは表示される。
| 「online」と「offline」の表示 |
|---|
[root@server]# smartctl -A /dev/hda
smartctl version 5.36 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
3 Spin_Up_Time 0x0027 252 252 063 Pre-fail Always - 113
4 Start_Stop_Count 0x0032 253 253 000 Old_age Always - 1
5 Reallocated_Sector_Ct 0x0033 253 253 063 Pre-fail Always - 0
6 Read_Channel_Margin 0x0001 253 253 100 Pre-fail Offline - 0
7 Seek_Error_Rate 0x000a 253 252 000 Old_age Always - 0
|
UPDATEの部分で、各項目の値の更新が「online」か「offline」なのか
表示される。
「always」と表示されているのが「online」テストで更新される意味で
青い部分が「offline」テストで更新されるという意味だ。
|
さて、「online」と「offline」の違い。
「online」の方は、ハードディスクの性能に影響を与えない方法で、
「offline」の方は、ハードディスクの性能が落ちる方法だという。
わかったような、わからん説明だ (--;;
調べてみると、「offline」の方は自己診断テストを行った時に
SMART値の更新されるという。
「-t」オプションを使った点検をしないと、データの更新がないという。
次のような事なのだ。
「online」は、常にデータの更新があるが、データ更新中に
特に、ハードディスクの性能が落ちる物ではない。
常に更新できる物だ。なのでUPDATEの種類で「always」と
表示されているのも合点がいく。
だが、「offline」では、自己診断の検査を行う必要があるため、
検査中、ディスクの入出力などの性能は落ちる事がある。
これで、すっきりしたのだ (^^)
smartmontoolsだが、もう1つのソフトがある。smartdだ。
これは、ハードディスクの監視を行うデーモンだ。
具体的に、どんな監視をするのか、man smartd で見てみる事にした。
| man smartd の結果 |
|---|
smartd will attempt to enable SMART monitoring on ATA devices
(equiva-lent to smartctl -s on) and polls these and SCSI devices
every 30 minutes (configurable), logging SMART errors
and changes of SMART Attributes via the SYSLOG interface.
The default location for these SYSLOG notifications and
warnings is /var/log/messages.
To change this default location, please see the '-l' command-line
option described below.
In addition to logging to a file, smartd can also be configured to send
email warnings if problems are detected. Depending upon the type of
problem, you may want to run self-tests on the disk, back up the disk,
replace the disk, or use a manufacturer's utility to force reallocation
of bad or unreadable disk sectors. If disk problems are detected,
please see the smartctl manual page and the smartmontools web page/FAQ
for further guidance.
|
赤い部分を見ると、smartdは、初期設定では30分ごとに、SMARTの値を
見にいく仕掛けになっている。
青い部分は、30分ごとに監視した結果、SMARTの監視項目で異常や、
異常がなくても項目の値に変化があれば、syslogを経由してログが書き込まれる。
初期設定では、/var/log/messages ファイルに書き込まれるのだ。
ピンクの部分は、SMARTの値に異常があれば、メールでも知らせるという。
|
smartctlコマンドだと、手動でSMARTの項目の値を見るのだが、
smartdというデーモンを使うと、24時間体制で自動的に監視してくれるのだ。
| /var/log/messages ファイルの中身 |
|---|
Jan 7 20:44:25 samba smartd[16020]: Device: /dev/hda, SMART
Usage Attribute: 9 Power_On_Minutes changed from 247 to 246
Jan 7 21:14:25 samba smartd[16020]: Device: /dev/hda, SMART
Prefailure Attribute: 8 Seek_Time_Performance changed from 248 to 247
|
smartdがsyslog経由で書き込んだログだ。
青い部分は、SMARTの項目の「ID 9」の値が変化したため書き込まれた。
赤い部分は、SMARTの項目の「ID 8」の値が変化したため書き込まれた。
|
30分ごとの監視で捉えたSMARTの項目の異常だけでなく、
刻一刻と変化するSMARTの監視項目の値もログに書き込んでくれるのだ。
smartdデーモンの設定の話を飛ばして、機能の方を先に紹介したが、
設定方法を説明します。
smartdデーモンには設定ファイルがある。smartd.conf というファイルだ。
このファイルは、RedHat系なら /etc ディレクトリにある。
他のディストリビューターの場合は、/usr/local/etc にあったりする。
ソースコンパイルをされた方は、「--sysconfdir」に指定した
ディレクトリにある。
さて、IDEのハードディスクで、毎日、15時に簡易テストを行い、
毎週土曜日の午前2時に完全テストを行う場合、以下のように設定を行う。
| smartd.confの設定 |
|---|
# First (primary) ATA/IDE hard disk. Monitor all attributes, enable
# automatic online data collection, automatic Attribute autosave, and
# start a short self-test every day between 2-3am, and a long self test
# Saturdays between 3-4am.
/dev/hda -a -o on -S on -s (S/../.././15|L/../../6/02) -m root
|
「-a」オプションは、4つのオプションを組み合わせた物だ。
(1) ハードディスクの健康診断結果を出し、異常があればログに書き出す「-H」
(2) ハードディスクの検査のログを出す「-l selftest」
(3) SMARTの項目で閾値以下の値が出た場合、異常を出す「-f」
(4) 前回のSMART値を見にいってから、30分でSMART値に変化がある物をログに書く
「-o」は、offline検査の自動化のオプション。後ろに「on」をつける
「-S」は、ハードディスクのSMART機能をオンにする。後ろに「on」をつける。
「-m」は、異常があれば、メールを送信するためのオプションで、
「-m」の後ろにメールアドレスを記述。
「-s」は検査の日時を指定する。
上の設定だと、簡易検査は毎日15時に行い、
完全検査は土曜日の2時に行う設定になっている。
|
さて、日時の設定方法を詳しく見てみる事にする。
| 検査日時の設定 |
|---|
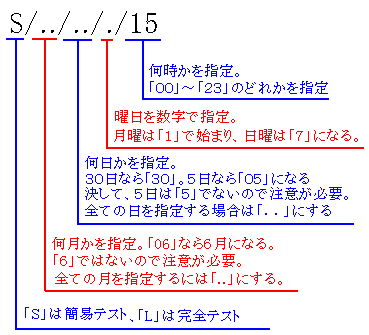 |
時間に対して注意が必要なのは、22と指定しても、22時に検査が
開始されるのではなく、22時から23時の間という意味だ。
なので、22と指定しても、22時30分くらいに検査が行われたりする。
|
月日、時間など任意で行う場合は「..」を入れるのだ。曜日は「.」だ。
月日、時間の数値の指定は「6」ではなく「06」なので、注意がいる。
さて、複数の時間帯で検査を行いたい場合もある。
朝の7時と、晩の22時に簡易検査を行いたい場合などある。
そんな場合、以下のように設定ができる。
| 検査日時の設定 |
|---|
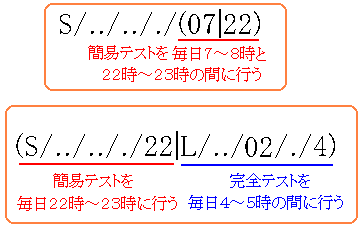 |
複数の指定ある場合は()で囲む。そして「|」を仕切りにして
検査を行いたい時間などを指定する。
|
これで設定が完了だ。
といっても、IDEのディスクの場合だけど・・・。
さて、自動的に監視させるsmartdデーモンを動かしてみる。
すると、/var/log/messagesファイルにログが記録される。
| /var/log/messages の中身 |
|---|
Jan 9 12:15:03 samba smartd[18158]: Device: /dev/hda, starting scheduled Long Self-Test.
Jan 9 12:45:03 samba smartd[18158]: Device: /dev/hda, SMART Prefailure Attribute: 8 Seek_Time_Performance changed from 249 to 250
Jan 9 13:45:03 samba smartd[18158]: Device: /dev/hda, SMART Prefailure Attribute: 8 Seek_Time_Performance changed from 250 to 249
Jan 9 14:15:03 samba smartd[18158]: Device: /dev/hda, SMART Usage Attribute: 209 Offline_Seek_Performnce changed from 253 to 193
Jan 9 14:15:04 samba smartd[18158]: Device: /dev/hda, starting scheduled Short Self-Test.
|
1行目は、完全検査開始のログ。
2、3行目は、SMARTの点検項目(ID 8)の平均シーク時間の変動があったため
ログに書き込まれた。
4行目は、offline検査で数値が変化があったもの。
5行目は、簡易検査の開始のログ。
|
常にログでも監視できる。
ただ、個々の値の変化を見ても、全体像は掴めないので、
時々、「smartctl -A」で全項目の値を見れば、だいたいの監視はできる。
RAIDが組めない場合などには有効だ!
さて、smartdの部分を読んで、妙に話が円滑に進んでいると思った読者の方、
非常鋭いです。実は・・・
かなり試行錯誤しながら動かしていました
なのだ (^^)
別に、七転八倒ぶりを隠すつもりはないのだ。
編集上の都合、話が飛びまくると・・・
編集する方が混乱するのらー!!
という事で、円滑に話を進めているのは、私の技術が向上して
実際に円滑に進んでいるのではなく、「私が楽するための編集のせい」
と思ってください (^^)
まとめ
ハードディスクの自己診断。
非常に便利な機能だと思いました。
Windows版のsmartmontoolsもあります。
ハードディスクが壊れる日を完全に予想できるわけではありませんが、
目安がある事で、オシャカになる時に備えて準備ができます。
RAIDを組んでいないサーバーなどに使えます。
ハードディスクのお勉強。
システム奮闘記:その54」でhdparmコマンドの時でも取り上げましたが
奥が深い上、わかりやすい資料等が少ないため、悪戦苦闘します。
精密機械を素人の私が理解する事自体、無茶な事なのかなぁと
思ったりしました (^^;;
ハードウェアベンダーの講習などが受講できたら、もっと楽に
勉強できるのかもしれないですが、そんな機会も費用もないので、
深く突っ込んだ話に踏み込めないのが残念です。
次章:「上海ペンギン旅行記」を読む
前章:「iSeriesAccessを活用したODBC経由のAS400(iSeries,i5)とLinuxの連動に成功」を読む
システム奮闘記に戻る