システム奮闘記:その52
Pukiwiki設定入門
(2006年9月11日に掲載)
はじめに
勤務先のホームページ制作や更新作業。
デザインセンスが全くない私にとっては、一番嫌な作業なのだ。
2000年に、会社のホームページを作成したのだが、ボロカスだった。
詳しくは「システム奮闘記:その4」をご覧ください。
(ホームページ公開)
そのため、2001年に、元社員の方で、Web制作の専門学校に通われた方に
ホームページの作成とメンテを依頼をしたのだった。
だが、その人が本業が忙しくなり、うちの会社のメンテができなくなった。
デザインセンスのない事を嫌ほど自覚している私にとって
ホームページの仕事は、絶対に「やりたくない仕事」なのだ。
そこで私は「外注した方が良い」と主張したものの、勤務先の回答は
「費用が発生する上に、外注の場合は、更新に時間がかかる」だった (--;;
外注の問題点として、コンテンツの変更などを依頼する時に
変更箇所の説明や、デザインなどの打ち合わせの手間と時間がかかる。
必死になって逃げたので、同僚が引き受ける事になったのだが、
そんな平和な時間も束の間だった。
君がやるように!
と言われるようになる。
同僚が使ったのは、ホームページビルダーというソフトだ。
これを使えば、誰でもホームページが作れる上、
デザインは指示するから、指示した通りソフトを使って作れというわけだ。
なんとか逃げようと考えたが、「IT担当者だろ」という事で
散々、文句を言われる。
|
コンピューターの場合だけ何でもできて当然と思われる訳 |
医者の場合、内科が心臓外科手術ができなくても、
脳外科医が耳鼻科の診察ができなくても、誰も不思議には思わない。
個々に専門分野があると認知されているからだ。
車でも、エンジンの設計している技術者が、ギアチェンジの部分や
内装のデザインができなくても文句は言われない。
だが、コンピューターの場合は、全体で1つの分野と思われている。
ネットワークもデータベースも普通の人から見れば、
同じコンピューターというわけだ。
その上、コンピューターの場合、表面的な知識やソフトの操作だけでも、
ある程度の事ができてしまう事に大きな問題がある。
そのため「俺でもできるから、君はできて当然」という発想が生まれる。
だが、IT担当者は、表面的な知識だけでの操作や運用が許されない
トラブルが発生すると、対処しなければならないからだ。
トラブルの対処を行うには、動作の仕組みなどを知る必要があり、
それには、ある程度のレベルを超えなければならない。
だが、ある程度のレベルを超えて、踏み込んだ場合、必要とされる知識が
一気に増える。しかも専門性も高くなり、学習に時間がかかる。
そのため、専門知識の習得に追われっぱなしのIT担当者とは裏腹に
普通の人から見れば「積極性がない」と映る。
|
ただでさえ、ホームページ関係の仕事はやりたくないのに、
ホームページビルダーを使って制作を行うのは絶対に嫌だ。
私はホームページビルダーを使いたくない。
その理由は、ホームページビルダには大きな問題点があるからだ。
それは一人でホームページを作成するには良いかもしれないが、
複数人でホームページを作成するには全く向いていない
|
ホームページビルダーの問題点 |
ホームページビルダーは初心者がホームページを作成する分には
HTML言語を覚える必要がないため、手軽な面がある。
だが、手軽さが厄介な問題を引き起こす事がある。
HTML言語を知らなくても作成できる反面、
生成されるHTMLソースを意識しないで作成するために
厄介な問題を引き起こす。ここが大きな落し穴となる。
例えば、画面を分割させる表示を行う時、フレームで分けるのか
それともテーブルや<div>のタグを使うのかを意識しない場合、
どんなソースかが中身を見てみないと、わからない。
そのため、別の人が変更を行う際、全体像を把握するために
HTMLを解読しないといけないのだ。これは大きな問題だ。
吐き出されるHTMLのタグは、ゴチャゴチャして非常に読みずらい上
CSSやJavaScriptなども埋め込まれる場合もあるため、
それらの知識がないとソースが読めない場合もあり、
解読するのに立ちふさがる厄介な問題だ。
特に「どこでも配置モード」で作成された場合は、
<div>タグだらけの発狂しそうなHTMLのソースになる。
個人で利用する分には良いかもしれないが、
複数人でメンテナンスを行うには不向きなのだ。
特に、ホームページビルダーの様々な機能を使ったホームページの場合、
吐き出されるHTLMソースを見ると、おぞましい状態になっている。
とても読む気が起こらない・・・
|
さて、ホームページビルダなんぞ触りたくない私。
だが、この奮闘記のようにタグ打ちだけでは、見栄えの良いサイトを
作るのは至難の技だ。
ホームページビルダーからの解放と、デザインセンスのなさの問題。
この2点を克服するため何か良い方法がないかなぁと考えた。
そこで思いついたのが、コンテンツ管理のソフトだ。
デザインは型にハマった物になり、自由度は下がるのだが、
デザインセンスが全くない私にとっては、決まった事しかできない方が
ありがたい。
今、話題のCMSなのらー!!
さて、最初はPukiwikiではなく、XOOPSを考えた。
色々、XOOPSの事例などを調べていくと「使えそう」という感触を得た。
そこで、早速、XOOPSとMySQLをLinuxマシンいれてみるが・・・
XOOPSの表示にエラーが出る (TT)
だった。
お得意のドツボにハマるパターンだ。
とてもXOOPSのソースを読んで対処する気が起こらない。
XOOPSの公式サイトには以下のような謳い文句がある。
|
XOOPSの公式サイトにある謳い文句 |
PHPおよびMySQLが利用可能なサーバであれば、
約 5 分でインストールでき、直ちに当サイトのような
ユーザ登録型コミュニティサイトを立ち上げることが可能です。
|
だが、地雷を踏む事に関しては卓越した才能を持っている私なので、
5分でインストールどころか、エラーが出て立往生する事になった。
(注意)
XOOPSに対しての批判の意図は毛頭にありませんので誤解のないように (^^;;
それだけでなく、XOOPSを使う際に、次の問題もあった。
MySQLがわからないもーん (^^;;
今まで、MySQLなんぞ触った事がない。
もちろん、PostgreSQLは触っているが、詳しいわけではない。
表面的な操作方法しか知らないのだが、MySQLの場合は全くの白紙だ。
MySQLでドツボにハマりそうだと本能的に察知した私は、
あっさりとXOOPSの導入を断念したのだった。
3月半ば、書店でふとPukiwikiの本をとる。
「Wikiでつくる かんたんホームページ」(ケイズプロダクション:九天社)
そういえばWikiがあった!
と思った私。
Pukiwikiは知らなかったが、Wikiが何なのかは以前から知っていた。
2003年3月、LILOのLMSで、たなかとしひささんが「Wikiの事始め」を
発表された時、私は「これ、ネタにもらった!」と言ったのを覚えている。
それから3年、全然、ネタになっていなかったのだ (^^;;
Pukiwikiに決めた大きな理由。
データベースが不要なのらー!!
データベース不要なので導入しやすいと考えた私だった。
まずは練習台として、社内向けホームページに使う事にした。
練習台として社内向けホームページで使っていて、
社外向けにも使えそうなら、使ってみる事にした。
さて、Pukiwikiの公式サイトから最新バージョンをダウンロードする。
http://pukiwiki.sourceforge.jp/
ちなみに、この時は、1.4.6が最新だった。
そのため今回の話は、バージョン1.4.6の話になります。
|
Pukiwikiの画面(初期状態) |
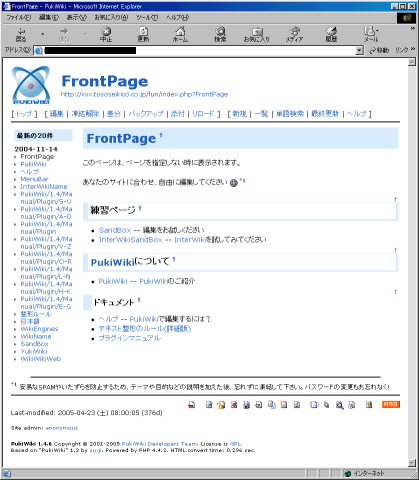 |
ただ、上の状態だと管理メニューが出ている状態だ。
これを、そのまま外部向けのホームページに出すのは不格好な上
セキュリティー上、好ましいとは思えない。
いくらパスワードがあっても、破られたら、元も子もない。
まさかホームページを「ご自由に内容を改竄してください」
という事なんぞできない。
そこで根元から絶つという事で、管理メニューを表示させないようにしたい。
それと、ゴチャゴチャした物も省きたい。
つまり以下の青と赤で囲んだ部分を表示させないようにしたいのだ。
|
表に出すと具合の悪い部分 |
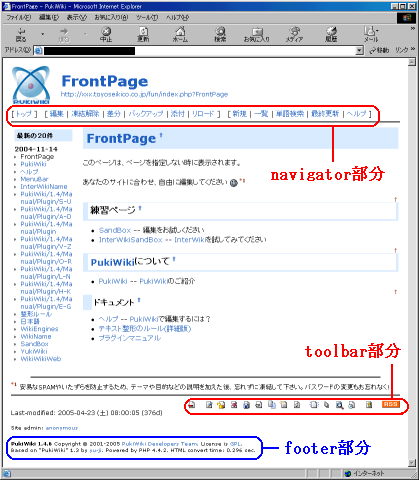 |
消したい部分を赤と青で囲んでみた。
|
さて、前述のPukiwikiの本を見て、ソースの書き換え場所を見る。
すると、skin/pukiwiki.skin.phpのソースを書き換えるという。
navigatorとtoolbar部分の表示を消す方法
skin/pukiwiki.skin.php の変更箇所 |
// SKIN_DEFAULT_DISABLE_TOPICPATH
// 1 = Show reload URL
// 0 = Show topicpath
if (! defined('SKIN_DEFAULT_DISABLE_TOPICPATH'))
define('SKIN_DEFAULT_DISABLE_TOPICPATH', 1); // 1, 0
// Show / Hide navigation bar UI at your choice
// NOTE: This is not stop their functionalities!
if (! defined('PKWK_SKIN_SHOW_NAVBAR'))
define('PKWK_SKIN_SHOW_NAVBAR', 0); // 1, 0
// Show / Hide toolbar UI at your choice
// NOTE: This is not stop their functionalities!
if (! defined('PKWK_SKIN_SHOW_TOOLBAR'))
define('PKWK_SKIN_SHOW_TOOLBAR', 0); // 1, 0
|
青い部分が上の図のnavigatorの部分を表示させるかどうかの設定。
赤い部分が上の図のtoolbarの部分を表示させるかどうかの設定
初期設定では定数を「1」に設定しているのだが、
ともに定数を「0」に設定してしまえば、表示されなくなる。
|
残りはfooter部分。これは強引に、footer部分の記述を削除する。
footer部分の記述(削除する部分)
skin/pukiwiki.skin.php
|
<div id="footer">
Site admin: <a href="<?php echo $modifierlink ?>"><?php echo $modifier ?></a><p />
<?php echo S_COPYRIGHT ?>.
Powered by PHP <?php echo PHP_VERSION ?>. HTML convert time: <?php echo $taketime ?> sec.
</div>
|
これで邪魔な物は綺麗さっぱり消えたと思った。
だが、まだ、邪魔な物が残っている。
|
まだ残っている邪魔な部分 |
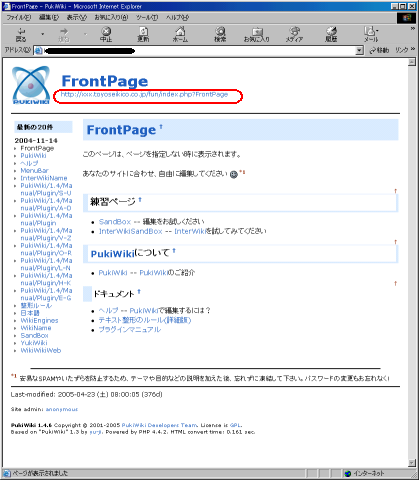 |
|
赤く囲んだ部分も消したい。
|
そこでskin/pukiwiki.skin.phpのソースを触る。
|
skin/pukiwiki.skin.php の変更箇所 |
// SKIN_DEFAULT_DISABLE_TOPICPATH
// 1 = Show reload URL
// 0 = Show topicpath
if (! defined('SKIN_DEFAULT_DISABLE_TOPICPATH'))
define('SKIN_DEFAULT_DISABLE_TOPICPATH', 0); // 1, 0
|
初期設定では定数を「1」に設定しているのだが、
定数を「0」に設定してしまえば、表示されなくなる。
|
だが、まだ邪魔な物が残っている。
|
しぶとく残っている邪魔な物 |
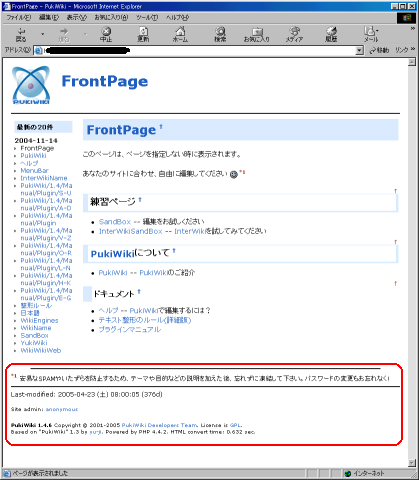 |
|
赤い部分を消したい。
|
これも強引に該当のソースの部分を削除する。
削除するソースの箇所(2ヶ所)
skin/pukiwiki.skin.php
|
<?php if ($notes != '') { ?>
<div id="note"><?php echo $notes ?></div>
<?php } ?>
<?php if ($attaches != '') { ?>
<div id="attach">
<?php echo $hr ?>
<?php echo $attaches ?>
</div>
<?php } ?>
<?php echo $hr ?>
|
<?php if ($lastmodified != '') { ?>
<div id="lastmodified">Last-modified: <?php echo $lastmodified ?></div>
<?php } ?>
<?php if ($related != '') { ?>
<div id="related">Link: <?php echo $related ?></div>
<?php } ?>
|
削除した結果、以下の画面になった。
|
Pukiwikiの画面 |
 |
これで綺麗サッパリになった。
あとは、綺麗な画面に画像などを載せたり、文章を編集したりすれば
ホームページができる。
だが、管理メニューの選択ができないのは問題だ。
そこで管理画面として初期状態の画面を残して、管理者以外が見るための
綺麗さっぱりな画面(閲覧用の画面)の2つにわける事にした。
さて、ソースを追っかける事にした。
まずは表示関係のソースskin/pukiwiki.skin.phpを出発点として、
このソースを読みいっているファイルはdefault.inc.php
default.inc.phpを読みにいっているファイルはpukiwiki.inc.php
といった感じで、ソースを遡っていく事にした。
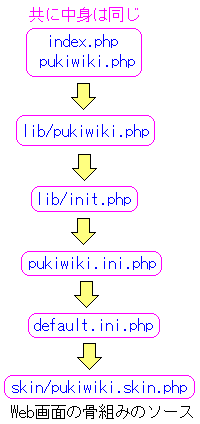
すると、以下のソースのつながりが見えてきた。
|
ソースのつながり |
 |
そこで閲覧画面と管理画面の両立のため、閲覧用画面のソース部分と
管理画面用のソースの部分に分ける。
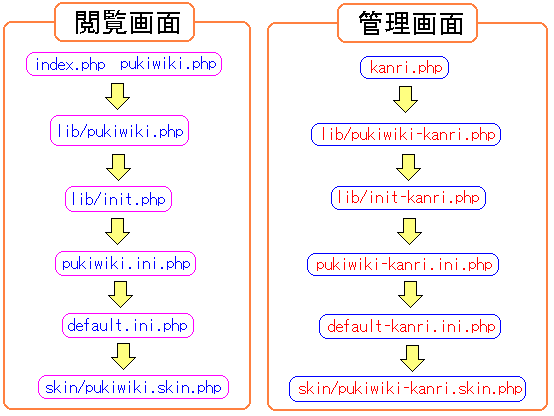
以下のようなソースのつながりになる。比較のため両方載せてみました。
|
ソースのつながり |
 |
閲覧用画面のトップは「index.php (pukiwiki.php)」にしておいて、
管理用画面のトップは「kanri.php」にする。
ソースの中身をちょこと触る。
|
ソースの違いを比較 |
| index.php (閲覧画面) |
/////////////////////////////////////////////////
require(LIB_DIR . 'pukiwiki.php');
|
| kanri.php (管理画面) |
/////////////////////////////////////////////////
require(LIB_DIR . 'pukiwiki-kanri.php');
|
|
ソースの違いを比較 |
| lib/pukiwiki.php (閲覧画面) |
// 初期化: 設定ファイルの読み込み
require(LIB_DIR . 'init.php');
|
lib/pukiwiki-kanri.php (管理画面) |
// 初期化: 設定ファイルの読み込み
require(LIB_DIR . 'init-kanri.php');
|
|
ソースの違いを比較 |
| lib/init.php (閲覧画面) |
// Require INI_FILE
define('INI_FILE', DATA_HOME . 'pukiwiki.ini.php');
|
| lib/init-kanri.php (管理画面) |
// Require INI_FILE
define('INI_FILE', DATA_HOME . 'pukiwiki-kanri.ini.php');
|
|
ソースの違いを比較 |
| pukiwiki.ini.php (閲覧画面) |
// Loose default: Including something Mozilla
array('pattern'=>'#^([a-zA-z0-9 ]+)/([0-9\.]+)\b#', 'profile'=>'default'),
array('pattern'=>'#^#', 'profile'=>'default'), // Sentinel
|
| pukiwiki-kanri.ini.php (管理画面) |
// Loose default-kanri: Including something Mozilla
array('pattern'=>'#^([a-zA-z0-9 ]+)/([0-9\.]+)\b#', 'profile'=>'default-kanri'),
array('pattern'=>'#^#', 'profile'=>'default-kanri'), // Sentinel
|
|
ソースの違いを比較 |
| default.ini.php (閲覧画面) |
// Skin file
if (defined('TDIARY_THEME')) {
define('SKIN_FILE', DATA_HOME . SKIN_DIR . 'tdiary.skin.php');
} else {
define('SKIN_FILE', DATA_HOME . SKIN_DIR . 'pukiwiki.skin.php');
}
|
| default-kanri.ini.php (管理画面) |
// Skin file
if (defined('TDIARY_THEME')) {
define('SKIN_FILE', DATA_HOME . SKIN_DIR . 'tdiary.skin.php');
} else {
define('SKIN_FILE', DATA_HOME . SKIN_DIR . 'pukiwiki-kanri.skin.php');
}
|
これで準備OK。
さて、Pukiwikiを動かすと・・・
管理画面と閲覧画面の両立ができた (^^)V
さて、これで社内向けホームページの制作の下準備ができた。
ここで読者から質問が次の質問があるかもしれない。
上のように、2つの画面に分けた場合でも
両方の画面で同じコンテンツが表示されるのか?
ここで正直な事を書きますと、2つの画面にわけた時点では
ソースを読まずに、ただ直感で見れると思い、結果、同じコンテンツが
表示されたというわけでした。
あとでソースを読んで、実際には問題なく、同じコンテンツが表示される事が
わかった。その理由は、Pukiwikiのソースで、コンテンツを取り込む部分で
全く同じ所からコンテンツを読み込んでいるためです。
さて、Pukiwikiだが、CSSを知らないとレイアウト関連が理解できない。
PukiwikiのCSSのファイルは、skin/pukiwiki.css.phpだ。
「一週間でマスターする CSS for Windows」
(相原哲哉:毎日コミュニケーションズ)
Windows向けと書いてあるが全く気にしない。
逆に「なぜ、Windows向けなの?」というツッコミを入れてみたくもなる (^^)
それにしても、Webデザイナーでもない私がスタイルシートの勉強を
するハメになった。
この本を読み始めた時、衝撃が走った。
<Hn>タグは文字の大きさの指定ではない!
<H1>が一番大きな文字で、<H6>が一番小さな文字を表示させると
思い込んでいた。
この奮闘記では、文字の大きさを変えるのに<FONT>タグを使っている。
<FONT>タグを使っているのは、<Hn>だと色の指定ができないと
思っていたためで、色の指定さえ考えなければ、文字の大きさの指定に
<Hn>タグを使っていた可能性もある。
<Hn>タグを調べてみると「見出し」のタグだという。
|
<Hn>タグについて |
<Hn>タグは「見出し」のタグだという。
初期設定では<H1>が一番大きく、<H6>が一番小さな文字の
見出しの表示になる。
このタグの前後は改行が入るため、文章の中で一部分だけ
文字の大きさを変えるのには向いていない。
そのため<FONT>タグを使うのが無難。
さて、CSSを使えば、<H1>タグの設定が行えるため、
<H1>より<H2>、<H2>よりも<H3>の方が
大きな文字の見出しにする事も可能だ。
|
<H1>より<H2>、<H2>よりも<H3>の方を
大きな文字の見出しにするCSSの中身 |
h1 {
font-size:100%;
}
h2 {
font-size:150%;
}
h3 {
font-size:200%;
}
|
論より証拠として、実際に以下のHTMLとCSSの組合せが
どのように表示されるのか見てみる事にした。
|
test.html |
<HTML><HEAD><TITLE>CSSの実験</TITLE></HEAD>
<META http-equiv="Content-Style-Type" content="text/css">
<link rel="stylesheet" media="screen,tv" HREF="style.css">
<BODY BGCOLOR="WHITE">
<H1>ああ</H1>
<H2>いい</H2>
<H3>うう</H3>
</BODY></HTML>
|
| style.css |
h1 {
font-size:100%;
}
h2 {
font-size:150%;
}
h3 {
font-size:200%;
}
|
さて、 <H1>より<H2>、<H2>よりも<H3>の方が大きい文字に
なっているかどうか、表示させてみる。
|
表示の結果 |
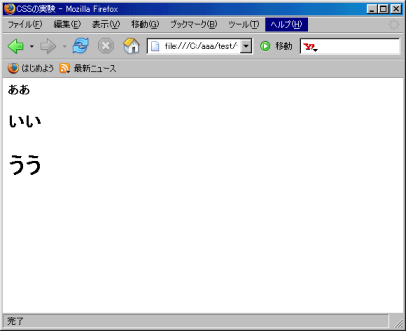 |
うまく表示できた (^^)V
<H1>より<H2>、<H2>よりも<H3>の方が大きい文字が
表示される事を示せた。
CSSを使えば、<Hn>タグの文字の大きさの変更だけではない事がわかった。
綺麗な見出しが表示できるのだ。
文字の周囲に余白があるのだが、その余白に色の設定ができるという。
|
margin(余白)とは何か? |
 |
文字の周囲の余白で、margin(マージン)という物がある。
この余白部分の色や余白の厚みをCSSを使って指定する事ができる。
そもそも、マージン(Margin)とは一体何なのか。
英語をそのまま使うから意味がわかりにくいし
覚えにくくする要因にもなる。
そこで、英英辞典で調べると marginの意味は次の通りだった。
the blank space round the written or printed matter or page
つまり「文章などが書かれた部分を囲んだ周囲の余白」という意味だ。
ITの技術が日本初だと、言葉の問題で技術の理解を阻害される事はないが
発祥の地が英語圏の場合、言葉の壁があるため、この問題が付きまとう。
まぁ、和製英語で混乱するよりも、英語圏の人が名付けた方が
マシだと思う場合もあるのだが・・・
|
さて、このmarginは4分割にする事ができる。
|
余白(Margin)は4つに分割されている |
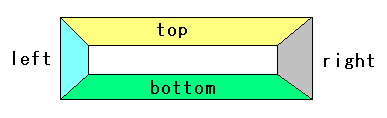 |
余白(Margin)は、上・下・右・左に分割する事ができる。
これにより上の余白部分は青で、右の余白部分は緑という指定ができる。
もちろん、上の余白と、下の余白とでは厚みの指定を別にする事が可能だ。
|
これも論より証拠で確かめて見る事にした。
余白の部分の色の指定だが、上の余白がオレンジ色。左の余白は青。
右の余白は緑で、下の余白は赤にした。
余白の厚みは、どれも10ピクセルにした。
|
test2.html |
<HTML><HEAD><TITLE>CSSの実験</TITLE></HEAD>
<META http-equiv="Content-Style-Type" content="text/css">
<link rel="stylesheet" media="screen,tv" HREF="style2.css">
<BODY BGCOLOR="WHITE">
<H1>ああ</H1>
<H2>いい</H2>
<H3>うう</H3>
<H4>ええ</H4>
<H5>おお</H5>
</BODY></HTML>
|
|
style2.css |
h1 {
font-size:150%;
border-top:10px solid ORANGE;
}
h2 {
font-size:150%;
border-left:10px solid BLUE;
}
h3 {
font-size:150%;
border-bottom:10px solid RED;
}
h4 {
font-size:150%;
border-right:10px solid GREEN;
}
h5 {
font-size:150%;
border-top:10px solid ORANGE;
border-left:10px solid BLUE;
border-right:10px solid RED;
border-bottom:10px solid GREEN;
}
|
さて、ブラウザで表示してみる。すると
|
表示の結果 |
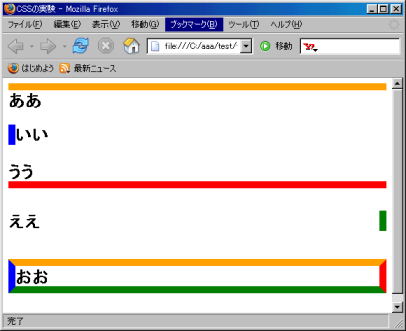 |
見事、余白に色をつける事ができた (^^)V
CSSを使えば、背景の色や、そのタグの中に入る文字の大きさ、
文字の色の指定などもできる。
色々な事ができるのかと感心しながらも「これによって、ホームページの
記述が余計に複雑になったのかい」と思ったりもする。
さて、CSSの役目とは一体、何なのか。それは本に書いてあった。
ブラウザはHTMLを読み込み際、各ブラウザが独自に持っている
初期値を使って、文字の大きさや色などを決めたりしている。
CSSのファイルを使えば、その値を変更する事ができるので、
ブラウザへの仕様変更のための指示書という感じだ。
<Hn>タグで、タグの中に入る文字の大きさも初期状態では
<H1>が一番大きな文字だったが、CSSで変更を加える事により
自由に設定できるというのだ。
ちょこちょことソースの中身を見てみる事にした。
Pukiwikiを使ってブラウザに表示させる時、形としては、
基本的には以下のような枠組になる。
|
ブラウザ上での表示の枠組 |
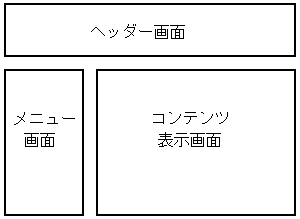 |
頭にヘッダー部分が来て、その下の部分はメニューの表示部分と
コンテンツの表示部分がやってくる。
|
メニュー部分とコンテンツ部分。
skin/pukiwiki.skin.php ソースを見ると以下のようになっている事がわかる。
|
ブラウザ上での表示の枠組 |
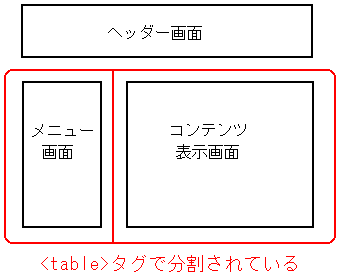 |
メニューの表示部分とコンテンツの表示部分だが、
<table>タグを使って、分けている。フレームではないし、
<div>タグだけを使って場所を指定しているわけではない。
|
|
skin/pukiwiki.skin.php ソースの該当箇所 |
<?php if (arg_check('read') && exist_plugin_convert('menu')) { ?>
<table border="0" style="width:100%">
<tr>
<td class="menubar">
<div id="menubar"><?php echo do_plugin_convert('menu') ?></div>
</td>
<td valign="top">
<div id="body"><?php echo $body ?></div>
</td>
</tr>
</table>
<?php } else { ?>
<div id="body"><?php echo $body ?></div>
<?php } ?>
|
ここを触れば、メニュー画面をコンテンツ画面の右側に置き換える事も
簡単にできるのだ。
次に、Pukiwiki独自のタグの処理について見てみる。
そのソースかなぁと思いつつ、適当にソースを見てみると
lib/convert_html.phpのソースに以下の記述があった。
lib/convert_html.phpのソース
(テーブルのタグ部分) |
// | title1 | title2 | title3 |
// | cell1 | cell2 | cell3 |
// | cell4 | cell5 | cell6 |
class Table extends Element
{
var $type;
var $types;
var $col; // number of column
function Table($out)
{
(以下省略)
|
どうやら「|」で囲むタグの処理部分のようだ。
lib/convert_html.phpのソースは、独自タグをHTMLへ変換させるための
ソースだと思った。
実際、ファイル名「convert_html」にある通り、変換のための部分だ。
しかし、この時は手探りで、ソースを見ていったため、
つまみ食い的にソースを見ては「この部分かなぁ」という推測をしていた。
さて、管理画面と表示画面の切り分けにも成功した上、
多少は、CSSも触れるようになった。
CSSが触れるのは、改造が多少できる事を意味する。
さて、まずは社内向けホームページで試験的に導入する事にした。
なにせ、Pukiwikiの使い方を覚えないといけないのだ。
そして、改造の必要が生じてきた時の練習にも使える。
社内向けなので実験として使えるのら!!
Pukiwikiの独自タグを覚える事を兼ねて、社内向けのサイトを作った。
使っていて思うのは、ホームページビルダーの場合、ファイルを
ftpなどでWebサーバーへ転送する必要がある。
しかし、Pukiwikiだと目の前のPC上で操作できるため、更新作業の中の
ファイル転送作業が省かれる事になる。これだけでも手間が減る。
実際に作ったら、社内では「なかなか、ええやん」という声だった。
「これはいける」と思った私なので、部長に次の事を宣言した。
今までのホームページを全てやり直して
Pukiwikiで作成します!
ホームページビルダーから解放されたいという強い気持ちだ。
なにせ、ホームページビルダーだと、発狂しそうなHTMLソースと
マウス操作のGUIの画面の両方を見ながら修正を行うという地獄の作業だからだ。
Pukiwikiの独自タグや、CSSの使い方を覚えるため、社内向けホームページを
実験台に色々触って行く。
それと並行して、ちょこちょことPukiwikiのソースの、つまみ食いを行う。
default.ini.phpのソースを眺めてみる。
次の部分があるのに気がつく。
|
default.ini.phpのソースで気づいた部分 |
// Face marks, Japanese style
'\s(\(\^\^\))' => ' <img alt="$1" src="' . IMAGE_DIR . 'face/smile.png" />',
'\s(\(\^-\^)' => ' <img alt="$1" src="' . IMAGE_DIR . 'face/bigsmile.png" />',
'\s(\(\.\.;)' => ' <img alt="$1" src="' . IMAGE_DIR . 'face/oh.png" />',
'\s(\(\^_-\))' => ' <img alt="$1" src="' . IMAGE_DIR . 'face/wink.png" />',
'\s(\(--;)' => ' <img alt="$1" src="' . IMAGE_DIR . 'face/sad.png" />',
'\s(\(\^\^;)' => ' <img alt="$1" src="' . IMAGE_DIR . 'face/worried.png" />',
'\s(\(\^\^;\))' => ' <img alt="$1" src="' . IMAGE_DIR . 'face/worried.png" />',
|
これを見た時、文字で作った顔文字が画像に変わるのではと思った。
早速、Pukiwikiに以下のデータを作ってみる。
だが・・・
(^^) のままだった・・・
試行錯誤の上、次のようにしたら、絵文字になる事がわかった。
ちなみに、顔文字が、どんな絵になるのか3つほど出してみる。
|
顔文字と絵 |
| 顔文字 |
変換される絵 |
| (^^) |
 |
| (^_-) |
 |
| (^^; |
 |
ソースを見れば、色々、仕掛けが見えてくるのだなぁと思った。
さて、本番のホームページの作成の段階に移る。
以前の私なら「よっしゃ、このまま作ってしまえ!」となるのだが、
数々のトラブルやドツボにハマった経験から
ある程度、ソフトの中身を把握せんとアカンやろ
と思った。
そして、以前なら「事務員なのでソースは読めません」で逃げるのだが
中途半端に実力がつくと、勢いで進める部分も出てしまい
ソースを読めばええやん!
となる。
我ながら単純な思考回路だと感心してしまう (^^;;
トラブル対応以外にも、プログラムの改造にはソースを読む必要がある。
そのため、単に使い方だけを知るのではなく、Pukiwikiの仕組みを
ある程度は把握する必要があるのだ!
だが、PHPのソースを触るのは久しぶり。
しかも、以前、PHPを勉強した時は、本の見よう見まねでPHP3を使っただけで
体系的にPHPを勉強した事がない。
そこで頭の整理を兼ねて体系的にPHPの勉強を行う。
「改訂新版 基礎PHP」(WINGSプロジェクト:インプレス)
を読む事にした。
PHP5の本だが、PHP4にも対応した非常にわかりやすい本だ。
ある程度、C言語を勉強した事もあるせいか、非常にとっつきやすいのだ。
ただ、私を苦しめたのは2つあった。
1つは正規表現。
PHPの場合、2種類の正規表現をサポートしているという。
|
PHPで使える2種類の正規表現 |
| Perl互換正規表現 |
| POSIX互換正規表現 |
シェルの勉強をした時も出てきた正規表現だが覚えられない。
この時は、軽く触れただけだったが、逃げたくても逃げられない物だ。
Pukiwikiのソースを読むのに必要な知識だという事が
後になってわかったからだ (^^;;
そして、次に私を苦しめたのはクラスの概念だった。
何せオブジェクト指向なんて勉強した事がないのだ。
しかも、以前、PHPを触った時は、クラスなんぞ理解できなかった。
もちろん、お得意の先送りをしたのだが、Pukiwikiを読むには
クラスの概念を理解する必要がある。
色々、プログラムの例を丸写しして動かして見る。
ふと思う。
C言語の構造体に似ているやん
|
構造体とオブジェクトの対比をしてみる |
| 構造体の定義 |
クラス |
| 構造体の変数 |
オブジェクト |
| 構造体のメンバー |
メンバー |
上のように考えると、わかりやすい。
実は、今までPHPでクラスを使った事はある。
PostgreSQLの関数を使った際、返り値がオブジェクトの物がある。
SQL文の結果をオブジェクトに入れたり、表示のため取り出したりしていた。
|
実は以前からPHPのクラスは使っていた |
PostgreSQL + PHP で検索システムを構築する際に、
PostgreSQLに関連するPHPの関数で、返り値がオブジェクトの物がある。
pg_fetch_object()関数だ。
引数に、SQLの実行結果のIDと、SQLの実行結果で取り出したいレコードの行番号。
返り値に、取り出したいレコード行のデータが入ったオブジェクトが入る。
以下のような形で使われる。
|
// PostgreSQLに接続する
$connect = pg_connect("host=HOSTNAME port=5432 dbname=DBNAME
user=ID password=PASSWORD");
// SQL文を $sql変数に覚えさせる
$sql = "SELECT * FROM table";
// SQLの実行結果のIDを返す
$execid = pg_exec($connect,$sql);
// 実行結果のレコードから4番目のレコードを取り出し、
// $qrecオブジェクトに入れる
// レコードは0番目から始まるため、数字が1ずれるので注意が必要!
$qrec = pg_fetch_object($execid,3);
// オブジェクト $qrec に入ったデータを取り出す
$name = $qrec->name ;
$address = $qrec->address ;
$tel = $qrec->tel ;
|
だが、「クラス」を意識して使っていたのではなく、PostgreSQL + PHP の
検索システムなどの例題プログラムのソースを、見よう見まねで
使っていただけなのだ。
今回の勉強のお陰で知識の整理ができたのだった (^^)
さて、クラスと正規表現。
難しいとはいえ、2つともC言語のポインタほど高い壁ではなかった。
なぜなら、理解するのに10年かかってませーん (^^)V
そうなのです。私はポインタを理解するのに、10年かかりました。
詳しくは「システム奮闘記:その36」をご覧ください。
副読本として以前に購入した次の本も役に立つ。
パフォー!!
パフォーって何やねん・・・。
そう、マンモスの鳴き声。つまりマンモス本なのだ!
「PHP4徹底攻略」(堀田倫英・石井達夫・廣川 類:ソフトバンクパブリッシング)
さて、マンモスといえば「はじめ人間ギャートルズ」を思い出す。
|
マンモスといえば「はじめ人間ギャートルズ」 |
私が幼稚園か小学校低学年の頃にテレビで放送されていた。
バームクーヘンのような、輪切りにされたマンモスの肉が
美味しそうに思えたりした。
アニメでは、人が大声で叫ぶと声が石化して飛んでいく。
そのため、主人公のゴンが石化した声に乗って遠くへ移動したりする。
貨幣は5円玉、50円玉のように真中に穴の空いた丸い石で、
貨幣価値は石の大きさで決まるため、高価な物を手に入れるため
大きな石を転がす部分も覚えている。
25年くらい前の記憶だが、結構、覚えていたりするぐらい
印象のあるアニメだった。
|
一通り、PHPのお勉強が終わった。
これでソースを読んでいくための道具は揃った。
なので、本格的に、Pukiwikiのソースの中身を見て行く事にする。
Pukiwikiの場合、index.phpから始めるが、require()を使って
色々なソースを取り込んでいる。
さて、闇雲にソースを見ていっても、混乱するだけなので、
どういう流れになっているのかを調べてみる事にした。
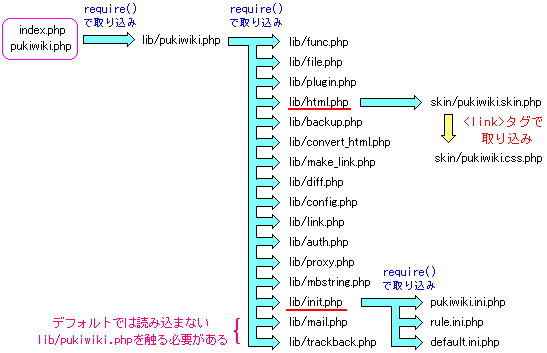
すると以下の図のようになる事がわかった。
|
ソース全体の様子 |
 |
|
もしかして、抜けている所があるかもしれませんが・・・ (^^;;
|
どこから攻めていけば良いのかわからない。
とりあえず、index.phpが最初に取り込んでいる lib/pukiwiki.phpのソースを
眺めてみる事にした。
ソースの最後の部分に注目してみる。
|
lib/pukiwiki.phpのソースの最後の部分 |
// Output
catbody($title, $page, $body);
exit;
|
catbody()関数とは何なのか。
$title、$page、$bodyの変数とは何の変数なのか。
それから調べてみる事にした。
まずは、$title変数から調べてみた。
これは、skin/pukiwiki.skin.phpのソースを見ればわかった。
|
skin/pukiwiki.skin.phpのソースの部分 |
|
<title><?php echo $title ?> - <?php echo $page_title ?></title>
|
上のソースを見ると、ブラウザーのツールバーの表示のための
変数だという事がわかる。
次に、$page変数を見てみる事にした。
これも、skin/pukiwiki.skin.phpのソースを見ればわかった。
|
skin/pukiwiki.skin.phpのソースの部分 |
<div id="header">
<a href="<?php echo $link['top'] ?>"><img id="logo"
src="<?php echo IMAGE_DIR . $image['logo'] ?>" width="80"
height="80" alt="[PukiWiki]" title="[PukiWiki]" /></a>
<h1 class="title"><?php echo $page ?></h1>
|
上の事から、$pageの変数は、Pukiwikiのヘッダー部分(header部分)に於いて
「ページ名」を表示させるため、ページ名を格納した変数なのだ。
残りの$body変数なのだ。
これも、skin/pukiwiki.skin.phpのソースを見ればわかった。
|
skin/pukiwiki.skin.phpのソースの部分 |
<?php if (arg_check('read') && exist_plugin_convert('menu')) { ?>
<table border="0" style="width:100%">
<tr>
<td class="menubar">
<div id="menubar"><?php echo do_plugin_convert('menu') ?></div>
;
</td>
<td valign="top">
<div id="body"><?php echo $body ?></div>
</td>
</tr>
</table>
<?php } else { ?>
<div id="body"><?php echo $body ?></div>
<?php } ?>
|
上のソースから、$bodyは、コンテンツの中身を格納した変数だと言える。
ふと思った。$bodyの中身は、どこから取り込んでくるのか。
そこで、lib/pukiwiki.phpのソースを見てみた。
|
lib/pukiwiki.phpのソースの部分 |
|
$body = convert_html(get_source($base));
|
この時点では、lib/pukiwiki.phpのソースを理解したわけでないため
当てずっぽで、この部分に目をつけたのだった。
だが、珍しく私の勘が当たり、正しい所に目をつけたのだった (^^;;
|
ページ名をget_source()関数に代入し、その結果をconvert_html()関数で
処理された結果が $body 変数の中身になる。
ページ名から、そのページ名のコンテンツの中身を引き出すという訳だ。
踏み込んで、get_source()関数とconvert_html()関数を見てみる事にした。
|
get_source()関数とconvert_html()関数について |
 |
get_source()は、lib/file.phpの中で定義された関数で
convert_html()は、lib/convert_html.phpの中で定義された関数だ。
|
さて、まずは get_source()から見ていく事にした。
まずはソースの内容から。
|
get_source()の定義部分(lib/file.php) |
function get_source($page = NULL, $lock = TRUE)
{
$array = array();
if (is_page($page)) {
$path = get_filename($page);
if ($lock) {
$fp = @fopen($path, 'r');
if ($fp == FALSE) return $array;
flock($fp, LOCK_SH);
}
// Removing line-feeds: Because file() doesn't remove them.
$array = str_replace("\r", '', file($path));
if ($lock) {
flock($fp, LOCK_UN);
@fclose($fp);
}
}
return $array;
}
|
初め、このソースを見て「あれ?」と思いました。
function get_source($page = NULL, $lock = TRUE)
の部分ですが、$page = NULL と $lock = TRUE があります。
なんで、こんな記述をするのかと思い、調べてみましたら、
次の意味がある事を知りました。
この関数を呼び出す時に get_source() という事で
引数を記述しなかった場合、関数の中では仮引数の値が決まりません。
そこで、デフォルト値として、$page = NULL と $lock = TRUE と設定し、
get_source("aaa",FALSE) とすれば、関数の中の仮引数は
それぞれ、$page = "aaa" 、 $lock = FALSE の値になります。
関数に引数を代入しない場合と、代入する場合の2つに備えた
設定というわけです。
|
さて、この get_source()が、どういう風に定義されているのか
簡単に図で説明すると、次のようになる。
|
get_source()について |
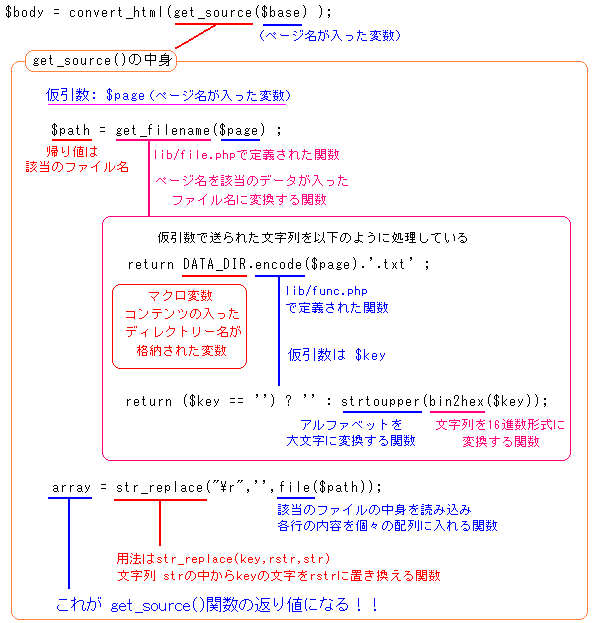 |
get_source()の中では上の図のような処理が行われている。
仮引数 $page (ページ名)を、get_filename()の中に代入しています。
get_filename()の中では、ページ名から該当のファイル名を割り出します
そして、割り出されたファイル名から file()関数を使って、
ファイルの中身を、1行、1行、配列の中に格納していきます。
その配列はget_source()の返り値になります。
|
さて、get_filename() でページ名を代入してファイル名を割り出す関数。
ページ名を16進数の文字列に変換した後、その文字列のアルファベット部分を
全て大文字にする処理。
これで、1つ謎が解けた。
Pukiwikiで作成したコンテンツの入ったファイルは、wiki/ のディレクトリに
格納されている。
そこに格納されているファイル名は数字とアルファベットで構成されている。
|
wiki/ の中のファイル名を見てみると |
suga@wiki[~/src/pukiwiki-1.4.6/wiki]% ls
3A52656E616D654C6F67.txt
3A636F6E666967.txt
3A636F6E6669672F5061676552656164696E67.txt
3A636F6E6669672F5061676552656164696E672F64696374.txt
3A636F6E6669672F706C7567696E.txt
3A636F6E6669672F706C7567696E2F6174746163682F6D696D652D74797065.txt
3A636F6E6669672F706C7567696E2F726566657265722F636F6E666967.txt
3A636F6E6669672F706C7567696E2F747261636B6572.txt
3A636F6E6669672F706C7567696E2F747261636B65722F64656661756C74.txt
3A636F6E6669672F706C7567696E2F747261636B65722F64656661756C742F666F726D.txt
|
ページ名が get_filename()によって処理された結果、
上のような名前になっている。
ページ名が、数字とアルファベットだけのファイル名に変換される事を
知る前は、ページ名を日本語にした場合、文字コードの問題などが
生じないのかなぁと思っていたが、これで合点がいく。
つまり日本語であっても、get_filename()によって、英数文字になるため
文字コードなんぞ関係なくなるからだ。
さて、次にファイルの中身が入った配列を処理するための
convert_html()についてみていく事にする。
まずは、convert_html()を定義しているソースの部分を見てみる。
|
convert_html()の定義部分 (lib/convert_html.php) |
function convert_html($lines)
{
global $vars, $digest;
static $contents_id = 0;
// Set digest
$digest = md5(join('', get_source($vars['page'])));
if (! is_array($lines)) $lines = explode("\n", $lines);
$body = & new Body(++$contents_id);
$body->parse($lines);
return $body->toString();
}
|
この関数の働きを図式化してみる事にした。
|
convert_html()関数について |
 |
$body->parse($lines); は、配列に格納されているファイルの中身の
データを処理する部分だ。
これは、Pukiwiki独自のタグを解析して、HTMLのタグに変換している。
そして、最終的な処理を $body->toString(); で行っている。
|
Bodyクラスで定義されている$body->parse()関数は、
コンテンツのデータを処理する部分になる。
あとで気づいた話だが、parseという単語の意味は「構文解析」だ。
つまりデータの中にある独自タグなどの解析を行うという意味だ。
さて、少しだけ $body->parse()関数の中身を見てみる事にした。
Bodyクラスの$body->parse()関数の定義
(lib/convert_html.php) |
function parse(& $lines)
{
$this->last = & $this;
$matches = array();
while (! empty($lines)) {
$line = array_shift($lines);
(処理部分なのだが、省略)
}
}
|
上のソースだが、青い部分の関数に注目する。
この関数をマンモス本で調べると、配列の先頭要素にあるデータを、
変数に移した後、コピー元の配列の要素を消して、残りの要素が
1つズレた形の配列を作る。
つまり図にすると以下の通りになる。
|
array_shift()関数について |
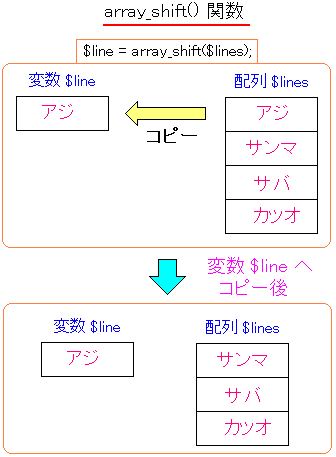 |
上の図のように、array_shift()関数は、配列の先頭要素にあった
「アジ」を変数 $line にコピーした後、元の配列の要素を消して
残りの要素が1つ前にズレた形の配列になる。
|
これを踏まえて、さきほどの$body->parse()関数の中身を見ると
見通しが良くなる。
|
$body->parse()関数について |
 |
array_shift()関数によって、$lines 配列の中に格納されていた
コンテンツのデータが、1行づつ取り出され $line の変数に格納される。
そして、$lineのデータが処理される。
$lines配列の要素がある限り、すなわちコンテンツが最終行に来るまで
処理のループが走るというわけだ。
|
Bodyクラスの中で、コンテンツのデータが1行づつ処理される事がわかった。
この時点では、ここでBodyクラスの中身を追っかけるのは止めた。
なぜなら、この時は「これぐらいで良いか」と思ったからだ。
だが、後になって、しっかりと解読する必要が出てきたので、
詳しくは、後で触れたいと思います。
さて、ふと思った。
管理者だけが使える管理画面と、閲覧専用の画面の分離だが、
以下のように別々のソースにしたのだが、これでは問題があるのではと思った。
|
ソースのつながり |
|
何が問題なのかといえば、このままだと管理画面の kanri.php は
誰でも閲覧できる状態なのだ。
社内向けのホームページなら問題はないのだが、社外向けなので
手当たり次第、探してくる
何か外部からの接続ができないようにしたい。
そこで考えたのが管理者専用のディレクトリーを設けて
管理者専用の画面に関するソース等を、そのディレクトリーに置けば
良いのではないか。
そこで、以下のディレクトリーを設ける。
|
ディレクトリーの追加 |
 |
「kanri」というディレクトリー名にした。
Aapcheの設定で、「kanri」というディレクトリーに対して
アクセス制限をかければ、外部からの接続ができなくなるというわけだ。
|
Apacheの設定 |
<Directory "/usr/local/apache/htdocs/kanri">
Options Indexes FollowSymLinks ExecCGI
AllowOverride None
Order deny,allow
deny from all
Allow from 許可するネットワークアドレス/サブネットマスク
</Directory>
|
このディレクトリー(kanri/)に、管理者画面に関するソースをいれる。
最初の画面表示のための「index.php」と、画面表示に関する
「skin/pukiwiki.php」の2つだ。
つまり、以下のようなソースのつながりにしたいのだ。
|
ソースのつながり |
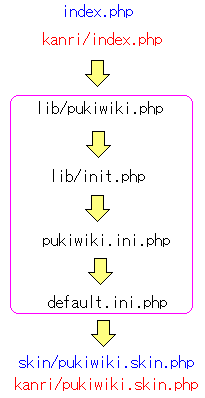 |
|
最初と最後だけ分離させて、後は共通して使う。
|
さて、そのためにはソースを触らねばならない。
まずは、index.php から触る。
|
ソースの違いを比較 |
| index.php (閲覧画面) |
/////////////////////////////////////////////////
// Directory definition
// (Ended with a slash like '../path/to/pkwk/', or '')
define('DATA_HOME', '');
define('LIB_DIR', 'lib/');
define('KANRI_GAMEN',0);
|
| kanri/index.php (管理画面) |
/////////////////////////////////////////////////
// Directory definition
// (Ended with a slash like '../path/to/pkwk/', or '')
define('DATA_HOME', '../');
define('LIB_DIR', '../lib/');
define('KANRI_GAMEN',1);
|
ここで管理画面(kanri/index.php)の場合、kanriのディレクトリーに
格納されるため、ライブラリなどのが入ったディレクトリーの場所を
触らないといけなくなる。
そして、両方のソースに「KANRI_GAMEN」という定数を設けて
場合分けを行えるようにしておく必要がある。
さて、次に default.ini.php を触る。
|
ソースの書き換える箇所 |
| default.ini.php (書き換え前) |
// Skin file
if (defined('TDIARY_THEME')) {
define('SKIN_FILE', DATA_HOME . SKIN_DIR . 'tdiary.skin.php');
} else {
define('SKIN_FILE', DATA_HOME . SKIN_DIR . 'pukiwiki.skin.php');
}
|
| default.ini.php (書き換え後) |
// Skin file
if ( KANRI_GAMEN == 1 ) {
define('SKIN_FILE', DATA_HOME . 'kanri/' . 'pukiwiki.skin.php');
} else {
define('SKIN_FILE', DATA_HOME . SKIN_DIR . 'pukiwiki.skin.php');
}
|
この部分は、pukiwiki.skin.phpを読み込む際、pukiwiki.skin.phpファイルの
保管ディレクトリーをつける部分だ。
管理者画面と、閲覧用では保管場所が違うので、場合分けが必要になる。
image ディレクトリに入っている画像の取り込みに関して
ここも閲覧用の「index.php」と管理者用の「kanri/index.php」では
ディレクトリーが違うため、imageディレクトリーの中にある画像ファイルを
取り込めるようにソースを触る必要がある。
|
ソースの違いを比較 |
| pukiwiki.ini.php (書き換え前) |
// Static image files
define('IMAGE_DIR', 'image/');
|
| pukiwiki.ini.php (書き換え後) |
// Static image files
if ( KANRI_GAMEN == 1 )
{
define('IMAGE_DIR', '../image/');
}
else
{
define('IMAGE_DIR', 'image/');
}
|
最後に、kanri/pukiwiki.skin.php なのだが、
これも触らないと、skin/pukiwiki.css.php を取り込む事ができない。
|
ソースの違いを比較 |
| skin/pukiwiki.skin.php (閲覧画面) |
<link rel="stylesheet" type="text/css" media="screen"
href="skin/pukiwiki.css.php?charset=<?php echo $css_charset ?>"
charset="<?php echo $css_charset ?>" />
<link rel="stylesheet" type="text/css" media="print"
href="skin/pukiwiki.css.php?charset=<?php echo $css_charset ?>
&media=print" charset="<?php echo $css_charset ?>" />
|
| kanri/pukiwiki.skin.php (管理画面) |
<link rel="stylesheet" type="text/css" media="screen"
href="../skin/pukiwiki.css.php?charset=<?php echo $css_charset ?>"
charset="<?php echo $css_charset ?>" />
<link rel="stylesheet" type="text/css" media="print"
href="../skin/pukiwiki.css.php?charset=<?php echo $css_charset ?>
&media=print" charset="<?php echo $css_charset ?>" />
|
(注意)
見やすくするため、実際のソースと違い、区切りの良い所で
改行をいれています。
|
これで準備OK。
さて、Pukiwikiを動かすと・・・
見事、成功 (^^)V
さて、いかにもソースを解読して簡単にやってのけた感じがするのだが、
実際には、試行錯誤している所もある。
imageディレクトリーの画像を取り込む部分で、pukiwiki.ini.phpの
ソースの書き換えを書きました。
この部分に気づく前は、どうやって画像を取り込もうかと考え
最初は、シンボリックリンクという手を使いました。
|
こんな手もある |
|
suga@wiki[~/src/pukiwiki-1.4.6/kanri]% ln -s ../image .
|
でも、シンボリックリンクにするとゴッチャになると考えた私は
ソースの書き換えで解決しようと思いました。
そこで、ソースを追っかけた結果、pukiwiki.ini.php のソースを
触れば良い事がわかり、ソースの書き換えにしました。
これで外部からコンテンツを操作される心配がなくなったと思ったのも
束の間だった。これでは不十分だという事が発覚する。
管理者画面と閲覧画面を分離させたのだが、管理者画面は、
Apacheでアクセス制限をかけている。だが閲覧画面は不特定多数の人に見られる。
誰でも見れる閲覧画面に、セキュリティーの問題が見つかったのだ。
管理者画面で編集した後、コンテンツを凍結しておけば問題ないのだが
凍結しないまま放置すると、閲覧画面のURLのクエリーを操作して、
ホームページの改竄などができる問題だ。
もちろん、凍結する事に越した事はないのだが、人間なので
凍結し忘れる事もあるし、たまたま編集中で凍結を解除している間に
攻撃に遭う事もある。
そこで何が問題で、それを根本から解決する話を書きました。
ズボラな私は編集したコンテンツを凍結せずに置いている。
まぁ、この時は社外に公開する前なので、問題はない。
ふと、ブラウザーのURLの入力部分に注目した。
|
Pukiwikiの画面 |
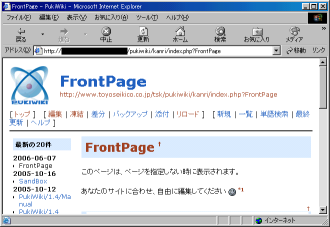 |
|
Pukiwikiの編集画面 |
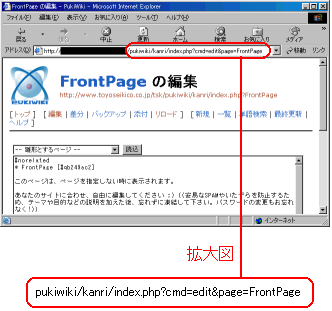 |
ふと次の事を思った。
|
Pukiwikiの編集画面 (管理者用画面) |
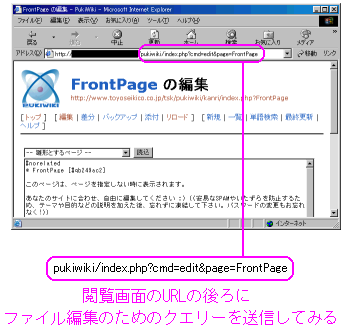 |
上の編集画面は管理者用の画面です。
そこで、URLで閲覧用の画面に、編集画面が開くための
クエリーを付けてみる事にした。
|
|
閲覧画面なのだが |
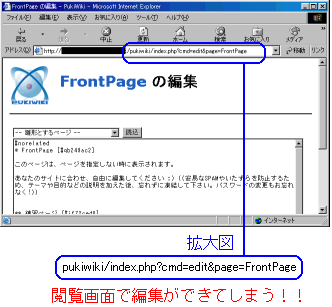 |
閲覧画面なのだが、コンテンツの編集できる状態になった。
|
これはマズい・・・ (^^;;
例え、コンテンツをパスワードで凍結していても、パスワードが
破られる可能性だってある。
ましてや、凍結をするのを忘れていたりすると、URLを操作するだけで、
簡単に、外部の人がコンテンツの編集や、ファイルのアップロードできたりする。
そこで、lib/pukiwiki.phpのソースに以下の細工を行う。
|
lib/pukiwiki.php に以下の細工を行う |
/////////////////////////////////////////////////
// Main
$retvars = array();
$is_cmd = FALSE;
// セキュリティー処理
if ( isset($vars['cmd'])) {
if ( KANRI_GAMEN == 0 && $vars['cmd'] == 'edit' )
{
unset($vars['cmd']);
}
}
if ( isset($vars['plugin'])) {
if ( KANRI_GAMEN == 0 && $vars['plugin'] == 'attach' )
{
unset($vars['plugin']);
}
}
// 処理おしまい
|
クエリーの部分でファイルのアップロードは「plugin=attach」があるため
単純に、URLの尻尾にあるクエリー部分の変数をなくしてしまえば
問題が解決できると考えた。
あと、編集はクエリー部分に「cmd=edit」があるため
単純に「cmd」で送られた変数をなくせば良いと思った。
|
さて、これで編集画面を呼び出すクエリーを送信してみた。
|
これで大丈夫! |
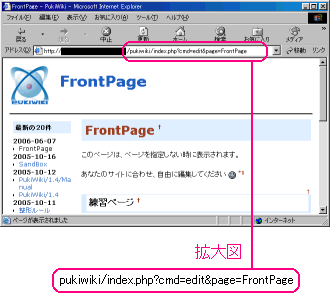 |
URLを操作されても編集画面などが出てこないようになった。
|
だが、これで解決というわけではない。
上で行った lib/pukiwiki.php の細工だけでは、クエリーの中身の
チェックの漏れがある。
その上、問題も発生した。
アップロードしたPDFファイルがダウンロードできへん (TT)
これは問題だ。
PDF型式の商品カタログを顧客向けにダウンロードできないのは問題だ。
|
添付ファイル |
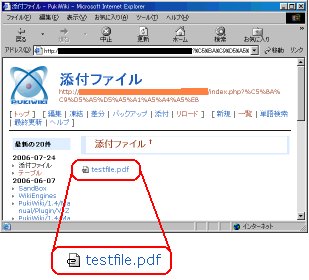 |
そこで、Webサーバーに送るクエリーについて調べてみる。
すると、アップロードしたPDFファイルなどダウンロードにするには
以下のクエリーをつける必要がある。
「 plugin=attach&refer=ページ名&openfile=ファイル名 」
という事で、送られたクエリーの処理を以下のように変更してみた。
|
lib/pukiwiki.php に以下の細工を行う |
/////////////////////////////////////////////////
// Main
$retvars = array();
$is_cmd = FALSE;
// セキュリティー処理
if ( KANRI_GAMEN == 0 )
{
if ( isset($vars['plugin']))
{
// ダウンロード以外は排除
if ( $vars['plugin'] != 'attach' )
{
unset($vars['plugin']);
}
// ダウンロード以外は排除
if ( $vars['plugin'] == 'attach' && ! isset($var['openfile']) )
{
unset($vars['plugin']);
}
}
}
// 処理おしまい
|
送られたクエリーのうち「plugin=attach」と「openfile=ファイル名」に
該当する物は、そのままにして、他の「plugin=XXXX」になる物を無効にした。
|
結果は・・・
見事、ファイルをダウンロードできた!!
しかも、クエリーに、他の plguin=XXXX という物を送っても
見事に弾いてくれる。
さて、まだ残っている物がある。
それは、クエリーに cmd=YYYYY を入れた場合だ。
これもセキュリティー的に具合が悪いので、処理を無効にしなければならない。
そこで上のソースの部分に、クエリーの cmd=YYYYを無効にする処置を
追加してみた。下のソースの赤い部分だ。
|
lib/pukiwiki.php に以下の細工を行う |
/////////////////////////////////////////////////
// Main
$retvars = array();
$is_cmd = FALSE;
// セキュリティー処理
if ( KANRI_GAMEN == 0 )
{
if ( isset($vars['cmd']) )
{
unset($vars['cmd']);
}
if ( isset($vars['plugin']))
{
// ダウンロード以外は排除
if ( $vars['plugin'] != 'attach' )
{
unset($vars['plugin']);
}
// ダウンロード以外は排除
if ( $vars['plugin'] == 'attach' && ! isset($var['openfile']) )
{
unset($vars['plugin']);
}
}
}
// 処理おしまい
|
すると・・・
トップページ以外、どこにも飛ばへん (TT)
だった。
上では、$var['cmd']を完全に無効している上、画像などの閲覧に関する
プラグイン以外は $vars['plugin'];を無効にしている。
実は、その場合、トップページ以外表示されなくなる。
実際に、lib/pukiwiki.php の続きを読めば、わかるのだ。
$var['cmd']を無効にした場合、その後の処理の動きを見る
lib/pukiwiki.php |
$retvars = array();
$is_cmd = FALSE;
if (isset($vars['cmd'])) {
$is_cmd = TRUE;
$plugin = & $vars['cmd'];
} else if (isset($vars['plugin'])) {
$plugin = & $vars['plugin'];
} else {
$plugin = '';
}
if ($plugin != '') {
if (exist_plugin_action($plugin)) {
// Found and exec
$retvars = do_plugin_action($plugin);
if ($retvars === FALSE) exit; // Done
if ($is_cmd) {
$base = isset($vars['page']) ? $vars['page'] : '';
} else {
$base = isset($vars['refer']) ? $vars['refer'] : '';
}
} else {
// Not found
$msg = 'plugin=' . htmlspecialchars($plugin) .
' is not implemented.';
$retvars = array('msg'=>$msg,'body'=>$msg);
$base = & $defaultpage;
}
}
|
赤い部分は、$var['cmd']を無効にしているため FALSE になり
条件文を満たさない。
青い部分は、$var['plugin']を無効にしているため FALSE になり
条件文を満たさない。
そのためピンクの部分にあるように、$plugin 変数の値は、何も入らない。
オレンジ色の部分だが、$plugin 変数の値は何もないので FALSEになり
elseの部分が動く。
elseの部分の、緑色の部分がページ名の指定にあたるのだが、
$defaultpage の変数には、トップページ名が入っている。
つまり、トップページを表示させるという意味だ。
|
以上のような仕掛けになっているのだが、この時点ではソースの内容が
読めていない事もあり
だが、この時は、原因がわからないだけに考え込んでしまった (--;;
考えているうちに、次のような事が思いついた。
そもそも、配列 $var にクエリーの値などを代入させるはず。
実際に、ソースを眺めると、クエリー以外で取得した値も
紛れこんでいる感じがした。
そこで、クエリーを直に取得した部分を触れば良いのではないかと思った。
lib/init.php ソースを眺める事にした。
すると、直にクエリーの値を取得する部分を見つける。
色々、触ったlib/pukiwiki.phpを元に戻して、lib/init.phpを触ってみる。
|
lib/init.php に以下の細工をする |
/////////////////////////////////////////////////
// 外部からくる変数のチェック
// Prohibit $_GET attack
foreach (array('msg', 'pass') as $key) {
if (isset($_GET[$key])) die_message('Sorry, already reserved: ' . $key . '=');
}
// Expire risk
unset($HTTP_GET_VARS, $HTTP_POST_VARS); //, 'SERVER', 'ENV', 'SESSION', ...
unset($_REQUEST); // Considered harmful
// 閲覧画面で不要なクエりーを排除!
if ( KANRI_GAMEN == 0 ) {
if ( $_GET['plugin'] != 'attach' )
{
unset($_GET['plugin']);
}
if ( $_GET['plugin'] == 'attach' && ! isset($_GET['openfile']) )
{
unset($_GET['plugin']);
}
}
// 処理おしまい
|
送られたクエリーのうち「plugin=attach」と「openfile=ファイル名」に
該当する物は、そのままにして、他の「plugin=XXXX」になる物を無効にした。
編集などができなくなるようにする処理は省いてみた。
|
今度は、無事、アップロードした添付ファイルをダウンロードできた。
だが、別の問題が発生した。それは・・・
アップロードした画像が表示できへん (TT)
| 画像が表示できない様子 |
 |
一難去って、また一難 (--;;
そこで上の細工を消して、画像の表示の際のHTMLソースを見てみる事にした。
すると、Pukiwikiでは以下のソースが吐き出される事がわかった。
|
Pukiwikiでアップロードした画像を表示させる際のHTMLの中身 |
<img src="http://pukiwiki.xxxx.co.jp/index.php?
plugin=ref&page=FrontPage&src=top.png"
alt="top.png" title="top.png" width="400" height="348" />
|
見やすいように改行をいれています。
|
上を見る限り、画像を呼び出すのに、Webサーバー(自分自身)に接続している。
そして「plugin=ref」というクエリーを送っている。
さて、さっき、画像が閲覧できなくなったのは「plugin=attach」以外は
排除する仕掛けになっていたため、「plugin=ref」のクエリーだと
見えなくなるというわけだ。
そこでlib/init.php のソースを以下のように書き換えた。
今度は、編集なども排除するようにした。
|
lib/init.php に以下の細工をする |
/////////////////////////////////////////////////
// 外部からくる変数のチェック
// Prohibit $_GET attack
foreach (array('msg', 'pass') as $key) {
if (isset($_GET[$key])) die_message('Sorry, already reserved: ' . $key . '=');
}
// Expire risk
unset($HTTP_GET_VARS, $HTTP_POST_VARS); //, 'SERVER', 'ENV', 'SESSION', ...
unset($_REQUEST); // Considered harmful
// 閲覧画面で不要なクエりーを排除!
if ( KANRI_GAMEN == 0 ) {
// 編集や凍結に関するクエリーは排除
if ( isset($_GET['cmd']) )
unset($_GET['cmd']);
// 添付ファイルのダウンロードと、画像表示以外は排除
if ( $_GET['plugin'] != 'attach' && $_GET['plugin'] != 'ref' )
{
unset($_GET['plugin']);
}
// ファイルのアップロードは排除
if ( $_GET['plugin'] == 'attach' && isset($_GET['pcmd']) )
{
unset($_GET['pcmd']);
unset($_GET['plugin']);
}
}
// 処理おしまい
|
さあ、これで全部、封じ込めたと思ったが、外部のサーバーで作った
編集画面やアップロード画面を悪用して、POST型式で、Webサーバーに
クエリーを送られても困るのだ。
|
編集画面 |
 |
|
編集画面のHTMLソース |
<div id="body">
<form action="http://pukiwiki.xxx.co.jp/index.php" method="post">
<div><input type="hidden" name="encode_hint" value="ぷ" /></div>
<div class="edit_form">
<select name="template_page">
<option value="">-- 雛形とするページ --</option>
<option value="BracketName">BracketName</option>
<option value="FrontPage">FrontPage</option>
(途中省略)
<option value="last">lasr</option>
</select>
<input type="submit" name="template" value="読込" accesskey="r" />
<br />
<input type="hidden" name="cmd" value="edit" />
<input type="hidden" name="page" value="FrontPage" />
<input type="hidden" name="digest" value="fb76413017bc84e930dc7e5d14f5db1e" />
<textarea name="msg" rows="20" cols="80">CENTER:&ref(top.png,nolink);
</textarea>
<br />
<input type="submit" name="preview" value="プレビュー" accesskey="p" />
<input type="submit" name="write" value="ページの更新" accesskey="s" />
<input type="checkbox" name="notimestamp" id="_edit_form_notimestamp" value="true" />
<label for="_edit_form_notimestamp">
<span class="small">タイムスタンプを変更しない</span></label>
<input type="submit" name="cancel" value="キャンセル" accesskey="c" />
<textarea name="original" rows="1" cols="1" style="display:none">
</textarea>
</div>
</form>
|
もし、第三者のサーバーで上みたいなページを作って、データを
うちのサイトに送られたのでは、勝手に文章が編集される危険もある。
|
こんな危険性がある |
 |
という訳で、早速、上の図のような攻撃が起こり得るのか確認するため、
実験を行ってみる事にした。
まずは、第3者のサーバーに以下のHTMLファイルを置いてみる。
|
uwagaki.html |
<HTML><HEAD><TITLE>上書き実験</TITLE></HEAD>
<BODY>
<div><form action="(攻撃先のURL)/index.php" method="post">
<div><input type="hidden" name="encode_hint" value="ぷ" /></div>
<div>
<select name="template_page">
<option value="">-- 雛形とするページ --</option>
<option value="BracketName">BracketName</option>
<option value="FrontPage">FrontPage</option>
<option value="InterWikiName">InterWikiName</option>
<option value="InterWikiSandBox">InterWikiSandBox</option>
<option value="InterWikiテクニカル">InterWikiテクニカル</option>
<option value="MenuBar">MenuBar</option>
<option value="PHP">PHP</option>
</select>
<input type="submit" name="template" value="読込" accesskey="r" />
<br />
<input type="hidden" name="cmd" value="edit" />
<input type="hidden" name="page" value="FrontPage" />
<input type="hidden" name="digest" value="fb76413017bc84e930dc7e5d14f5db1e" />
<textarea name="msg" rows="20" cols="80">
</textarea>
<br />
<input type="submit" name="preview" value="プレビュー" accesskey="p" />
<input type="submit" name="write" value="ページの更新" accesskey="s" />
<input type="checkbox" name="notimestamp" value="true" />
<label for="_edit_form_notimestamp"><span>タイムスタンプを変更しない</span></label>
<input type="submit" name="cancel" value="キャンセル" accesskey="c" />
<textarea name="original" rows="1" cols="1" style="display:none">
</textarea>
</div>
</form>
</BODY></HTML>
|
この場合、攻撃先の閲覧画面にアクセスして、トップ画面の書き換えを
意図するコードになっている。
|
そこで上のHTMLを開いてみる。
そして以下のように文章を編集してみる。
|
第3者のサーバーで編集 |
 |
早速、データを送信してみると
|
コンテンツが書き換わった様子 |
 |
これを見た瞬間・・・
思わず凍りついてしまった (--;;
管理者画面で編集中に、上のような事をされたら恐い。
しかも、コンテンツを凍結し忘れていたら大変だ。
管理者画面の場合は、Apacheでアクセス制限をしているので、
第3者サーバーによる攻撃はないのだが、閲覧用画面は外部に公開するため、
上のような事が行われてしまう。
そこで、閲覧画面の場合、POST型式でやってくるクエリーも排斥したい。
|
lib/init.php に以下の細工をする |
/////////////////////////////////////////////////
// 外部からくる変数のチェック
// Prohibit $_GET attack
foreach (array('msg', 'pass') as $key) {
if (isset($_GET[$key])) die_message('Sorry, already reserved: ' . $key . '=');
}
// Expire risk
unset($HTTP_GET_VARS, $HTTP_POST_VARS); //, 'SERVER', 'ENV', 'SESSION', ...
unset($_REQUEST); // Considered harmful
// 閲覧画面で不要なクエりーを排除!
if ( KANRI_GAMEN == 0 ) {
// POSTでやってくる場合は排除
unset($_POST);
// 編集や凍結に関するクエリーは排除
if ( isset($_GET['cmd']) )
unset($_GET['cmd']);
// 添付ファイルのダウンロードと、画像表示以外は排除
if ( $_GET['plugin'] != 'attach' && $_GET['plugin'] != 'ref' )
{
unset($_GET['plugin']);
}
// ファイルのアップロードは排除
if ( $_GET['plugin'] == 'attach' && isset($_GET['pcmd']) )
{
unset($_GET['pcmd']);
unset($_GET['plugin']);
}
}
// 処理おしまい
|
これで第3者サーバーからの書き換えは防げるようになった。
これで安心 (^^)
と思いきや、まだ、問題があった。
クエリーの cmd が無効になった事を書きました。
管理画面で、何気なく「単語検索」を開いてみた。
|
単語検索の画面を開いてみた |
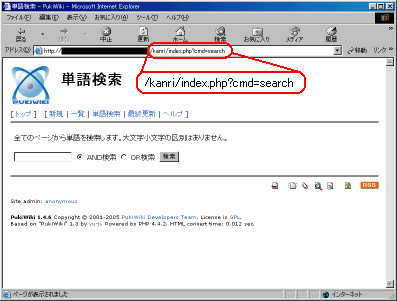 |
|
この時、クエリーの中には「cmd」が含まれている。
|
さて、URLで「kanri」を省いてみて、動かしてみる事にした
すると信じられない画面が出てきた!!
|
編集画面が出てきた。 |
 |
なんと編集画面が出てきただった!!
もう、何がなんだか、さっぱりわからない (TT)
しかし、この問題は放置できない!!
何げなく見つけたのだったが、気がつかなかったら大変な事になっている。
もし、悪い奴にエロ小説を書かれたら大変だ!!
Webの改竄で、エロ画像を張られたりする事件があるが、
同じくエロ小説を書かれるとなれば、非常にカッコが悪い!!
だが、この時点では原因がわからなかった。
実は、lib/init.phpをじっくり読めば、原因がわかるのだが、
この時点では、私の頭の中で lib/init.php の中の動きが整理されおらず
ただ、当てずっぽの対策に終始していたため、お手上げだった。
なので、渋々、先送りする事にした。
だが、ホームページの公開直前になり、原因がわかった。
本来なら、時間軸に忠実に書くため「後述しています」と書きたい所だが
読み易さの都合も考えて、先に紹介する事にします。
ホームページの公開数日前、コンテンツなども載せ終わった事もあり
部長から「そろそろ公開してええやろ」と言われていた。
だが、この時、まだ問題は先送りしたままだった。
この問題は解決せんとマズイやろ (^^;;
と思った。
部長には「最終的なセキュリティーチェックを行っています」と答えつつも
「どないして解決したら、ええねん」と思った。
出力に関する、lib/pukiwiki.phpのソースを眺めてみるが、
原因が見えてこない。
この時、普通にトップページや他のページを開く場合は、
プラグインが働いていないという思い込みがあった。
そのため、lib/pukiwiki.phpにおいて、普通にページを開く場合は
以下のような部分が動くと思い、ソースを読んでいた。
|
lib/pukiwiki.phpのソース |
/////////////////////////////////////////////////
// Main
$retvars = array();
$is_cmd = FALSE;
if (isset($vars['cmd'])) {
$is_cmd = TRUE;
$plugin = & $vars['cmd'];
} else if (isset($vars['plugin'])) {
$plugin = & $vars['plugin'];
} else {
$plugin = '';
}
if ($plugin != '') {
if (exist_plugin_action($plugin)) {
// Found and exec
$retvars = do_plugin_action($plugin);
if ($retvars === FALSE) exit; // Done
if ($is_cmd) {
$base = isset($vars['page']) ? $vars['page'] : '';
} else {
$base = isset($vars['refer']) ? $vars['refer'] : '';
}
} else {
// Not found
$msg = 'plugin=' . htmlspecialchars($plugin) .
' is not implemented.';
$retvars = array('msg'=>$msg,'body'=>$msg);
$base = & $defaultpage;
}
}
|
プラグインが動いていないという思い込むから、赤い部分はFALSEになり
条件文は満たさないと思った。
そのため $pluginの値だが、青い部分にあるように、文字列の値が
入らいないと考えていた。
そして、ピンクの部分だが、これも青い部分で文字列の値が入っていない事から
FALSEになると思い、緑の部分のelse部分が動くと思っていた。
|
上のソースで緑のelseの部分が動けば、開かれるページは
トップページになるのだが、なぜか編集画面が出てしまう。
わけがわからない状態だ (--;;
だが、何気なしに思いついた事が、解決の糸口になった。
その何気ない思いつきとは、lib/pukiwiki.phpのソースを
ちょっと触ってみる事だった。
|
lib/pukiwiki.phpの次の部分を追加してみた |
/////////////////////////////////////////////////
// Main
$retvars = array();
$is_cmd = FALSE;
if (isset($vars['cmd'])) {
$is_cmd = TRUE;
$plugin = & $vars['cmd'];
} else if (isset($vars['plugin'])) {
$plugin = & $vars['plugin'];
} else {
$plugin = '';
}
die("$plugin");
|
この時、$pluginに値があれば、ブラウザは$pluginの値を表示する。
die()関数を使っているので、$pluginの値以外は何も表示されない。
早速、動かしてみると
「read」と表示された!!
この時
なんで「read」やねん (・o・)
と思った。
なぜなら、普通にページを表示させる時は、何もプラグインを
使っていないという思い込みがあったからだった。
もしかして、readというプラグインがあるのではと思い、
プラグインがあるディレクトリを見てみると案の定、plugin/read.inc.phpの
ソースがあった。
さて、これは初期化に関する lib/init.phpソースを読まねば
なぜ、「read」と表示されるのかが見えてこない。
そこで lib/init.phpソースを、じっくり見ていく事にした。
しかし、公開直前ともなれば、Pukiwikiのソースも嫌ほど読んでいるため
この問題が発見された時よりも、Pukiwikiのソースを読む要領がわかっている。
最初に、lib/init.phpのソースを見てみる事にした。
まずは、クエリーを取り出す部分を見てみる。
クエリーを取り出す部分
( lib/init.php ) |
/////////////////////////////////////////////////
// QUERY_STRINGを取得
// cmdもpluginも指定されていない場合は、QUERY_STRINGを
// ページ名かInterWikiNameであるとみなす
$arg = '';
if (isset($_SERVER['QUERY_STRING']) && $_SERVER['QUERY_STRING']) {
$arg = & $_SERVER['QUERY_STRING'];
} else if (isset($_SERVER['argv']) && ! empty($_SERVER['argv'])) {
$arg = & $_SERVER['argv'][0];
}
if (PKWK_QUERY_STRING_MAX && strlen($arg) > PKWK_QUERY_STRING_MAX) {
// Something nasty attack?
pkwk_common_headers();
sleep(1); // Fake processing, and/or process other threads
echo('Query string too long');
exit;
}
$arg = input_filter($arg); // \0 除去
|
赤い部分はクエリーの中身を全て $arg変数にいれている。
青い部分も、同じような感じだ。
この違い、実は、私はよくわかっていません。
実験で確かめて見た結果、同じ結果が出たぐらいしか、わかりません (--;;
ただ言えるのは、クエリーの中身を全て $arg変数に格納したいようだ。
|
$argの変数だが、このままではページ名だけの場合もあれば、
cmdもpluginなどの指定もあり、両方の場合が混ざってしまうため、
ページ名だけを抽出したとは言えない。
cmdもpluginなどの指定がある場合、ページ名は「page=XXXX」という形で
指定される。そこでページ名の抽出部分を見てみる。
cmdもpluginなどの指定がある場合、ページ名の抽出部分(1)
( lib/init.php ) |
/////////////////////////////////////////////////
// QUERY_STRINGを分解してコード変換し、$_GET に上書き
// URI を urlencode せずに入力した場合に対処する
$matches = array();
foreach (explode('&', $arg) as $key_and_value) {
if (preg_match('/^([^=]+)=(.+)/', $key_and_value, $matches) &&
mb_detect_encoding($matches[2]) != 'ASCII') {
$_GET[$matches[1]] = $matches[2];
}
}
unset($matches);
|
クエリーを「&」を区切りにして分解する処理だ。
編集画面のプラグインなどの場合、以下のURLになっている。
http://********/index.php?cmd=edit&page=FrontPage
上の例でいくと、赤い部分は中身が「cmd=edit」、「page=FrontPage」の
配列を作る事を意味する。
foreach文は配列に対しての繰り返しなので、分解してできた物を
順番に処理していくのだ。
青い部分だが、配列の中身を正規表現で抽出するのだ。
「=」の前の部分は、$matches[1]に格納され、「=」の後ろは$matches[2]に
格納されるのだ。
上の例の「page=FrontPage」の場合だと、$matches[1]に「page」が格納され
$matches[2]には「FrontPage」が格納される。
そしてピンクの部分は$_GET[]配列に書き込んでいるのだ。
キーやキーの中身に重複があったとしても上書きという形になる。
ページ名の部分は、とりあえず $_GET['page']=ページ名で保管される。
|
だが、まだこれで終わりではない。
ソースの続きを見てみる事にします。
cmdもpluginなどの指定がある場合、ページ名の抽出部分(2)
( lib/init.php ) |
/////////////////////////////////////////////////
// GET, POST, COOKIE
$get = & $_GET;
$post = & $_POST;
$cookie = & $_COOKIE;
// GET + POST = $vars
if (empty($_POST)) {
$vars = & $_GET; // Major pattern: Read-only access via GET
} else if (empty($_GET)) {
$vars = & $_POST; // Minor pattern: Write access via POST etc.
} else {
$vars = array_merge($_GET, $_POST); // Considered reliable than $_REQUEST
}
|
説明する必要もないと思いますが、POST型でデータが送られていない場合は
GET型で送られたデータの$get配列が、そのまま $var配列へコピーされる。
GET型でデータが送られていない場合は、POST型で送られた
データの$post配列が、そのまま $var配列へコピーされる。
POST型、GET型の両方のデータが存在する場合は、2つとも
$var配列へコピーされる。
つまり(2)で出てきた、$_GET['page']=ページ名 で上書きされた部分が、
$var['page']=ページ名 でコピーされている事を意味するのだ。
|
そして、最終的な加工を見てみる。
cmdもpluginなどの指定がある場合、ページ名の抽出部分(4)
( lib/init.php ) |
// 整形: page, strip_bracket()
if (isset($vars['page'])) {
$get['page'] = $post['page'] = $vars['page'] = strip_bracket($vars['page']);
} else {
$get['page'] = $post['page'] = $vars['page'] = '';
}
|
赤い部分だが、クエリに cmdやpluginが含まれる場合は TRUE になる。
青い部分はstrip_bracket()関数を使って、ページ名が格納された
$vars['page']の中にある「[」と「]」とを取り除く関数だ。
このstrip_bracket()関数は lib/func.phpで定義されている。
その返り値は、3つの変数 $get['page']、$post['page']、$vars['page']
に代入される。
反対に、クエリに cmdやpluginが含まれない場合は、ピンクの部分のように
$get['page']、$post['page']、$vars['page']の3つの変数は、
文字列の値を入れないようにしている。
|
ここまでで、クエリーの中に、cmdやpluginが含まれている場合の
ページ名の抽出を説明しました。
では、cmdもpluginも指定されていない場合のページ名を見てみる事にした。
cmdもpluginも指定されていない場合のページ名の変数
( lib/init.php ) |
// cmdもpluginも指定されていない場合は、QUERY_STRINGをページ名かInterWikiNameであるとみなす
if (! isset($vars['cmd']) && ! isset($vars['plugin'])) {
$get['cmd'] = $post['cmd'] = $vars['cmd'] = 'read';
if ($arg == '') $arg = $defaultpage;
$arg = rawurldecode($arg);
$arg = strip_bracket($arg);
$arg = input_filter($arg);
$get['page'] = $post['page'] = $vars['page'] = $arg;
}
|
赤い部分はクエリー内で、cmdもpluginも指定されていない場合 TRUEになる。
さて、クエリーの中がページ名だけの場合や、あと、私が先ほど行った
セキュリティー対策で、クエリー内のcmdもpluginの指定を
はたき落とした場合、この条件が満たされる。
青い部分は、cmdもpluginの指定を行う。ここでは「 read 」をいれる。
ページの表示の場合、readプラグインを動かすためなのだ。
緑の部分は、ページ名の指定がない場合、$arg変数に、
トップページのページ名が入った $defaultpage が代入される。
ピンクの部分は、ページ名の変数が入った $arg の値を
$get['page']、$post['page']、$vars['page']の3つの変数に代入する。
|
この時、初めて、cmdやpluginの指定がない場合は、
readプラグインが設定される事を知った!!
まさか普通のページを表示するのに、プラグインが働いているとは
想像もつかなかった。
さて、readプラグインが動く事がわかれば、プラグインのソースを見れば
話が見えてくる。そこで plugin/read.inc.php を見てみた。
readプラグインのソース
( plugin/read.inc.php ) |
function plugin_read_action()
{
global $vars, $_title_invalidwn, $_msg_invalidiwn;
$page = isset($vars['page']) ? $vars['page'] : '';
if (is_page($page)) {
// ページを表示
check_readable($page, true, true);
header_lastmod($page);
return array('msg'=>'', 'body'=>'');
} else if (! PKWK_SAFE_MODE && is_interwiki($page)) {
return do_plugin_action('interwiki'); // InterWikiNameを処理
} else if (is_pagename($page)) {
$vars['cmd'] = 'edit';
return do_plugin_action('edit'); // 存在しないので、編集フォームを表示
} else {
// 無効なページ名
return array(
'msg'=>$_title_invalidwn,
'body'=>str_replace('$1', htmlspecialchars($page),
str_replace('$2', 'WikiName', $_msg_invalidiwn))
);
}
}
|
赤い部分の is_page()関数だが、これはページ名に該当するファイルが
実際に存在するするかどうかのチェックする関数だ。
lib/func.php で定義されている関数だ。
青い部分に注目する。特にコメント文に反応した。
「存在しないので、編集フォームを表示」と書いている。
指定したページ名が存在しない場合、編集フォームを表示させるという意味だ。
|
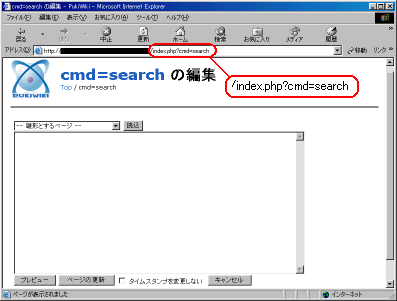
ここで謎が解けた!!
なぜ、編集画面が出てくる原因が!!
つまり次の通りだ。
|
編集画面が出てくる原因 |
|
上の図ではクエリーが「cmd=search」となっている。
何もソースを触っていないPukiwikiだと「cmd」の部分で、
プラグインの呼び出しと反応して、searchプラグインを表示させる。
だが、私がセキュリティー処理を行ったために、閲覧画面から
cmdを含むクエリーを送っても、cmdが叩き落とされる。
この時点で、クエリーの中に cmdやpluginを含まないという形になる。
しかし、ページ名の抽出で、クエリーの中に cmdやpluginを含まない部分の
処理が働くため、ページ名として「cmd=search」と認識される。
そして、readプラグインが動くようにセットされる。
さて、「cmd=search」というページ名で認識されるのだが、
「cmd=search」ページ名に該当するファイルは存在しないために
readプラグインが編集画面を出すという仕組みだ。
|
いやぁ、こんな仕掛けになっていたとは思ってもみなかった。
普通にページを開くにはプラグインを使わないといった思い込みは捨てて
ソースは読むべきだなぁと思った。
さて、この問題の解決法だが、いたって簡単だった。
lib/init.phpのソースに1行、追加するだけだった。
cmdもpluginも指定されていない場合のページ名の変数
( lib/init.php ) |
// cmdもpluginも指定されていない場合は、QUERY_STRINGをページ名かInterWikiNameであるとみなす
if (! isset($vars['cmd']) && ! isset($vars['plugin'])) {
$get['cmd'] = $post['cmd'] = $vars['cmd'] = 'read';
if ($arg == '') $arg = $defaultpage;
$arg = rawurldecode($arg);
$arg = strip_bracket($arg);
$arg = input_filter($arg);
if ( ! is_page($arg) && KANRI_GAMEN == 0 ) $arg = $defaultpage;
$get['page'] = $post['page'] = $vars['page'] = $arg;
}
|
赤い部分を追加した。
追加した部分とは、指定したページ名に該当するファイルがない場合で、
しかも閲覧画面の場合、ページ名を格納する変数に、トップページの値を
入れるようにする処理だ。
is_page()関数とは、lib/func.phpで定義された関数で、
ページ名に該当するファイルが存在するかどうかを確認する関数だ。
|
公開直前になって、解決できて良かったと思った (^^)V
さて、コンテンツの改竄を防ぐためのセキュリティーの話が出たので、
Pukiwikiのセキュリティー機能(?)について、3点挙げておきます。
まず1点目として、凍結機能だ。
不特定多数の人にコンテンツを改竄されないように、コンテンツに
プロテクトをかけておく必要がある。
Pukiwikiでは、プロテクトをかける機能を「凍結」と呼んでいる。
最初、「凍結」機能を見た時、どうやってプロテクトをかけているのかと
考えてみた。
PHPからsystem()関数を使って、外部コマンドを呼び出して
ファイルのパーミッションを変えているのだろうか、それとも何だろか。
調べてみると、コンテンツのファイルに「凍結」の目印をつけている事が
わかった。
さて、実際に凍結しているコンテンツファイルを見てみる。
凍結されたコンテンツファイルを見ると
( wikiディレクトリ ) |
[suga@server wiki]$ more 7465737470616765.txt
#freeze
** テストページだよ! [#xdc5ef01]
見栄えはどうかなぁ?
[suga@server wiki]$
|
赤い部分が凍結しているかどうかの目印だ。
|
Pukiwikiでは「#freeze」の目印がある場合、編集画面を呼び出さない
仕掛けになっている。
2点目は、全てのコンテンツを編集不可能、即ち、閲覧のみにする方法がある。
これは、次の部分を触れば良いのだ。
全てのコンテンツを編集できなくする方法
( pukiwiki.ini.php ) |
/////////////////////////////////////////////////
// Security settings
// PKWK_READONLY - Prohibits editing and maintain via WWW
// NOTE: Counter-related functions will work now (counter, attach count, etc)
if (! defined('PKWK_READONLY'))
define('PKWK_READONLY', 1); // 0 or 1
|
青い部分で、「1」としてしまえば、コンテンツは全て編集不可になる。
ただし、編集したい場合は、ここの部分を「0」にする必要があるので
手間かもしれない。
|
なぜ、編集できなくなるのか。
それは、編集のプラグインを呼び出す際に、チェック部分がある。
編集のプラグインでのチェック部分
( plugin/edit.inc.php ) |
function plugin_edit_action()
{
global $vars, $_title_edit, $load_template_func;
if (PKWK_READONLY) die_message('PKWK_READONLY prohibits editing');
(以下、省略)
}
|
赤い部分がチェックの部分です。編集不可にした場合、PKWK_READONLYの値は
「1」のため、この条件文では TRUE になる。
そのため、die_message()関数が働き、ここで処理がストップするわけだ。
ちなみに、die_message()関数は、lib/func.php で定義されている関数で、
メッセージを表示して、処理をストップさせる働きをする。
|
そして3点目として、同時に2人以上が編集作業を行った場合に起こる
コンテンツの整合性を検知機能だ。
Pukiwikiは、個人のメモ帳代わりだけでなく、イベント関連の書き込みなど
複数人が編集に関わる事を想定されている。
そのため以下の図のような事も十分に起こり得る話なのだ。
|
2人が同時刻に、同じコンテンツを編集を行う可能性がある |
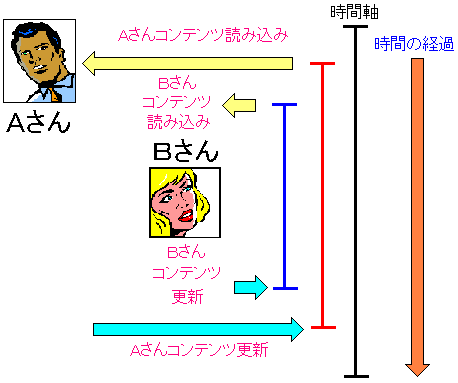 |
Aさんが編集のため、編集画面を呼び出す。
この時、コンテンツを読み込む形になる。
Bさんは、Aさんが編集している事を知らずに、同じコンテンツを編集するため
編集画面を呼び出す。この時も、コンテンツを読み込む形になる。
Bさんが先に編集し終わった場合、編集した内容を反映させるため、
コンテンツを更新させる。
その後、もし、Aさんが編集した内容を反映させる場合、
Bさんが更新した内容を上書きしてしまうため、
Bさんが編集した部分は無視され、Aさんが編集した物だけが
更新されてしまうという問題が出てくる。
|
上図のように、お互いが同じコンテンツを編集している事を知らずに、
更新作業を行うと、片方の人が編集した内容が反映されなくなる問題が出てくる。
この問題自体は解消できないが、上図の事が起こった場合、
Aさんが更新ボタンを押した場合、既にBさんが編集してしまっている事を
知らせる機能があれば、Bさんの編集した内容が勝手に消される心配はなくなる。
編集画面を出す直前のコンテンツと、更新直前のコンテンツの内容を比較して
違う場合、すなわち、編集中に誰から編集&更新してしまった場合を
知らせてくれる機能が Pukiwikiにはあります。
その鍵を握るのは、編集画面を呼び出した時のHTMLの中にあります。
|
編集画面のHTMLソース |
<div id="body">
<form action="http://pukiwiki.xxx.co.jp/index.php" method="post">
<div><input type="hidden" name="encode_hint" value="ぷ" /></div>
<div class="edit_form">
<select name="template_page">
<option value="">-- 雛形とするページ --</option>
<option value="BracketName">BracketName</option>
<option value="FrontPage">FrontPage</option>
(途中省略)
<option value="last">lasr</option>
</select>
<input type="submit" name="template" value="読込" accesskey="r" />
<br />
<input type="hidden" name="cmd" value="edit" />
<input type="hidden" name="page" value="FrontPage" />
<input type="hidden" name="digest" value="fb76413017bc84e930dc7e5d14f5db1e" />
<textarea name="msg" rows="20" cols="80">
</textarea>
<br />
<input type="submit" name="preview" value="プレビュー" accesskey="p" />
<input type="submit" name="write" value="ページの更新" accesskey="s" />
<input type="checkbox" name="notimestamp" id="_edit_form_notimestamp" value="true" />
<label for="_edit_form_notimestamp">
<span class="small">タイムスタンプを変更しない</span></label>
<input type="submit" name="cancel" value="キャンセル" accesskey="c" />
<textarea name="original" rows="1" cols="1" style="display:none">
</textarea>
</div>
</form>
|
赤い部分は digest変数の値として「fb76413017bc84e930dc7e5d14f5db1e」を
サーバーに送る仕掛けになっている。
この digest変数。最初、見た時は、何かのかわからなかったのだが、
何か意味があると思ったが、その時点では調べなかった。
だが、その後、Pukiwikiのソースを呼んでいたら、$digest変数を見つけた。
どんな値があるのか調べると、コンテンツの内容をMD5ハッシュ関数に入れた
結果の値だ。
つまり上の赤い部分の値は、コンテンツの編集前の内容を
MD5のハッシュ関数に入れた結果の値になる。
|
編集画面を呼び出す時、画面を呼び出す直前のコンテンツの内容を
取得しているというわけだ。
実際に、ソースを見てみる。
編集画面を呼び出す際に、編集直前のコンテンツを
MD5のハッシュ関数に入れて、$digestの値にする部分
( lib/html.php ) |
function edit_form($page, $postdata, $digest = FALSE, $b_template = TRUE)
{
global $script, $vars, $rows, $cols, $hr, $function_freeze;
global $_btn_addtop, $_btn_preview, $_btn_repreview, $_btn_update, $_btn_cancel,
$_msg_help, $_btn_notchangetimestamp;
global $whatsnew, $_btn_template, $_btn_load, $non_list, $load_template_func;
global $notimeupdate;
// Newly generate $digest or not
if ($digest === FALSE) $digest = md5(join('', get_source($page)));
(以下、省略)
|
赤い部分が $digestの値を作成する部分。
これが編集直前のコンテンツの内容を表す値になる。
|
わざわざ、編集直前のコンテンツのデータを取り込んで
MD5のハッシュ関数に入れて、$digestの変数の値にするのか。
それは、コンテンツの整合性の確認に使うためだ。
さて、言葉で書くとわかりずらいので、図にしてみた。
|
編集直前と、更新直前とのコンテンツの整合性の比較 |
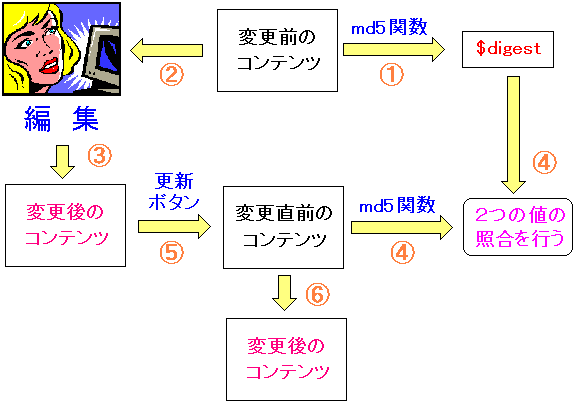 |
編集直前にコンテンツをMD5ハッシュ関数で加工した値を取得。
$digest変数に格納する。
そして、コンテンツの更新直前に、更新前のコンテンツを
MD5のハッシュ関数で加工し、それを $digestに格納した物とを比較する。
一致すれば、編集中に、コンテンツを触った人がいない事を意味するので
そのままコンテンツの内容は更新される。
|
もし、編集中に、誰からコンテンツを触って編集していた場合を考えてみる。
|
もし、編集中に誰かがコンテンツを更新していたら |
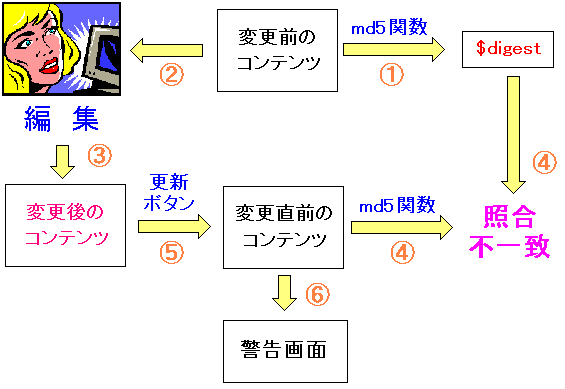 |
この場合、更新直前の、コンテンツの内容と、$digestの値が一致しない。
誰かが触っていた事になる。
|
さて、差異があった場合、ブラウザでは、どんな表示が出るのだろうか。
実際に、その様子を下図にしました。
|
もし、不一致になった場合のブラウザの画面 |
 |
不一致を知らせる画面が出てくる。
その上で、このまま更新して良いかをきいている。
|
さて、コンテンツの更新を行う際に、更新直前のデータの差異の
チェックのを行う部分のソースを見てみる。
コンテンツの差異のチェック部分
( plugin/edit.ini.php ) |
// Write, add, or insert new comment
function plugin_edit_write()
{
global $vars, $trackback;
(途中、省略)
$oldpagesrc = join('', get_source($page));
$oldpagemd5 = md5($oldpagesrc);
if (! isset($vars['digest']) || $vars['digest'] != $oldpagemd5) {
(以下、省略)
|
青い部分は、更新直前のコンテンツのデータを取り込んで、
MD5ハッシュ関数に入れる。その値を $oldpagemd5 に入れる。
赤い部分の $vars['digest'] だが、変数画面からクエリーで
送られた $digest 変数の値で、編集直前のコンテンツのデータを
MD5ハッシュ関数に入れて出てきた値だ。
赤い部分が、編集直前のコンテンツと、更新直前のコンテンツとの間で
データの中身に差異があるかどうかのチェックを行う部分だ。
|
複数人が同時にコンテンツの編集を行う可能性がある事まで考慮して
プログラムをしているのが、よくわかる。
さてさて、時間軸を元に戻して、手探りの状態でソースを見ながら
ホームページの作成を行う話を続けます。
さて、Pukiwikiでテーブル(表)を作るのに、2種類の独自タグがある。
|
テーブルに関する2種類の独自タグ |
| 「|」を使う方法 |
「,」を使う方法 |
|A|B|
|C|D| |
,A,B
,C,D |
この違いは何か。
ソースを詳しく読んでいないので、よくわからない
だった (^^;;
この時、マニュアルなどでは「|」を使う方法だと、
だが、両方とも表示が同じだ。
|
こんな記述をしてみた |
|りんご|みかん|
|100円|200円|
&br;
,ざるそば,300円
,きしめん,400円
|
|
表示結果 |
 |
両方とも背景の色がつくし、表示は真中揃えだ。
背景が透明で、表示が左寄せで、しかも表の囲いがないようにしたい。
背景が透明にするといっても、単に白にすれば良いので、背景を白にしたい。
そうすれば、会社の沿革などが綺麗に編集できる。
片方の方法に手を加えてみようと考えた。
この時点では「|」はコンテンツの中で、結構使っているので、
手を加えたくない。
そこで全く使っていない「,」の使う方法の部分に手を加えてみる事にした。
まずは、lib/convert_html.phpのソースを眺める。
|
lib/convert_html.php の「,」の処理に関する部分 |
// , title1 , title2 , title3
// , cell1 , cell2 , cell3
// , cell4 , cell5 , cell6
class YTable extends Element
{
var $col;
function YTable($_value)
{
parent::Element();
$align = $value = $matches = array();
foreach($_value as $val) {
if (preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches)) {
$align[] =($matches[1] != '') ?
((isset($matches[3]) && $matches[3] != '') ?
' style="text-align:center"' :
' style="text-align:right"'
) : '';
$value[] = $matches[2];
} else {
$align[] = '';
$value[] = $val;
}
}
$this->col = count($value);
$colspan = array();
foreach ($value as $val)
$colspan[] = ($val == '==') ? 0 : 1;
$str = '';
$count = count($value);
for ($i = 0; $i < $count; $i++) {
if ($colspan[$i]) {
while ($i + $colspan[$i] < $count && $value[$i + $colspan[$i]] == '==')
$colspan[$i]++;
$colspan[$i] = ($colspan[$i] > 1) ? ' colspan="' . $colspan[$i] . '"' : '';
$str .= '<td class="style_td"' . $align[$i] . $colspan[$i] . '>' . make_link($value[$i]) . '</td>';
}
}
$this->elements[] = $str;
}
function canContain(& $obj)
{
return is_a($obj, 'YTable') && ($obj->col == $this->col);
}
function & insert(& $obj)
{
$this->elements[] = $obj->elements[0];
return $this;
}
function toString()
{
$rows = '';
foreach ($this->elements as $str)
$rows .= "\n" . '<tr class="style_tr">' . $str . '</tr>' . "\n";
$rows = $this->wrap($rows, 'table', ' class="style_table" cellspacing="1" border="0"');
return $this->wrap($rows, 'div', ' class="ie5"');
}
}
|
上の青い部分に注目する。
これに該当するCSSのソースは、skin/pukiwiki.css.php になる。
このソースで「style_td」の記述を探す。
|
skin/pukiwiki.css.php の「style_td」の処理に関する部分 |
.style_td {
padding:5px;
margin:1px;
color:inherit;
background-color:#EEF5FF;
}
|
さて、背景の色を白にするが、これを書き換えると「|」で作る表まで
背景が白になる。
そこで、「,」で作る表だけ、背景を白にするため、以下のようにする。
skin/pukiwiki.css.php に「style_td2」を追加
独自の設定にしてしまう。 |
.style_td_kam {
padding:5px;
margin:1px;
color:inherit;
background-color:WHITE;
}
|
そして、lib/convert_html.php の「,」のテーブルの記述を
次のように書き換える。
|
書き換え前 |
$str .= '<td class="style_td"' . $align[$i] . $colspan[$i] . '>' . make_link($value[$i]) . '</td>';
|
|
書き換え後 |
$str .= '<td class="style_td_kam"' . $align[$i] . $colspan[$i] . '>' . make_link($value[$i]) . '</td>';
|
さて、これで実行してみると
|
実行結果 |
 |
テーブルの表のタグが背景が白になった。
だが、周囲の表の枠が残っている。
この段階では <TD>タグの部分の設定を行っただけで、
表の枠の設定には触れていないからだ。
次に注目したのは、<TABLE>タグの部分だった。
そこで、lib/convert_html.php のソースで「,」の部分を見てみる。
|
lib/convert_html.php の「,」の処理に関する部分 |
// , title1 , title2 , title3
// , cell1 , cell2 , cell3
// , cell4 , cell5 , cell6
class YTable extends Element
{
var $col;
(途中省略)
function toString()
{
$rows = '';
foreach ($this->elements as $str)
$rows .= "\n" . '<tr class="style_tr">' . $str . '</tr>' . "\n";
$rows = $this->wrap($rows, 'table', ' class="style_table" cellspacing="1" border="0"');
return $this->wrap($rows, 'div', ' class="ie5"');
}
}
|
上の青い部分に注目する。
これに該当するCSSのソースは、skin/pukiwiki.css.php になる。
このソースで「style_table」の記述を探す。
|
skin/pukiwiki.css.php の「style_table」の処理に関する部分 |
.style_table {
padding:0px;
border:0px;
margin:auto;
text-align:left;
color:inherit;
background-color:#ccd5dd;
}
|
ここを書き換えると「|」で作る表まで影響を受けてしまう。
そこで、独自の設定として、skin/pukiwiki.css.phpに追加する
|
skin/pukiwiki.css.php の「style_table_kam」を追加 |
.style_table_kam {
padding:0px;
border:0px;
margin:auto;
text-align:left;
color:BLACK;
background-color:WHITE;
}
|
上の赤い部分の設定で、背景の色を白にする事により囲いを消す。
そして、以下のように lib/convert_html.php のソースを書き換える。
|
lib/convert_html.php の書き換え |
// , title1 , title2 , title3
// , cell1 , cell2 , cell3
// , cell4 , cell5 , cell6
class YTable extends Element
{
var $col;
(途中省略)
function toString()
{
$rows = '';
foreach ($this->elements as $str)
$rows .= "\n" . '<tr class="style_tr">' . $str . '</tr>' . "\n";
$rows = $this->wrap($rows, 'table', ' class="style_table_kam" cellspacing="1" border="0"');
return $this->wrap($rows, 'div', ' class="ie5"');
}
}
|
これで囲いが消えた。
|
実行結果 |
 |
だが、もう1つ問題がある。
表の位置が中央のままなのだ!
そうなのです。「,」で作る表は左寄りにしたいのだ。
だが、どこを触れば良いのか見当がつかない。
そこで、表が表示するために吐き出されたHTMLソースを見る。
|
表の出力の際に吐き出されるHTMLソース |
<div class="ie5"><table class="style_table" cellspacing="1" border="0">
<tbody><tr><td class="style_td">a</td><td class="style_td">b</td></tr>
<tr><td class="style_td">g</td><td class="style_td">f</td></tr></tbody>
|
<div class="ie5">のタグある。
一体、これはどういう事を意味するのだろうか。
絵に表すと次のような感じになる。
|
こういう構図になっている |
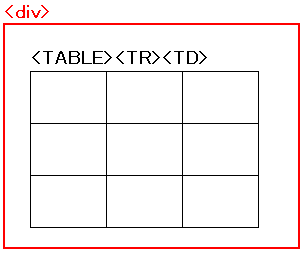 |
テーブルの外は<div>のタグで囲まれているため、
<div class="ie5">の設定を見てみる必要がある。
|
そこで「,」のテーブルに関するCSSの記述を見てみる。
|
skin/pukiwiki.css.php の「ie5」の設定 |
|
div.ie5 { text-align:center; }
|
真中にいくように設定されている。
そこで「,」のテーブル用に新たに記述を作る。
|
skin/pukiwiki.css.php の「ie5_kam」を追加 |
|
div.ie5_kam { text-align:left; }
|
そして、以下のように lib/convert_html.php のソースを書き換える。
|
lib/convert_html.php の書き換え |
// , title1 , title2 , title3
// , cell1 , cell2 , cell3
// , cell4 , cell5 , cell6
class YTable extends Element
{
var $col;
(途中省略)
function toString()
{
$rows = '';
foreach ($this->elements as $str)
$rows .= "\n" . '<tr class="style_tr">' . $str . '</tr>' . "\n";
$rows = $this->wrap($rows, 'table', ' class="style_table_kam" cellspacing="1" border="0"');
return $this->wrap($rows, 'div', 'class="ie5_kam"');
}
}
|
さて、実行してみる。
|
実行結果 |
 |
見事、成功! (^^)V
これで会社の沿革などが綺麗に表示できる。
さて「,」の方式で、手を加えた話を書きましたが、
もう1つテーブルの独自タグが欲しくなった。
なぜなら、以下のように左寄せで、枠のある表も欲しくなったからだ。
|
こんな表も作りたい |
 |
ふと思った。
ちょこっと、lib/convert_html.phpのソースを触ればええやん!
まずは、タグとして使っていない文字を探す。
そこで思いついたのが「_」の文字だ。アンダーバーだ。
後でわかった話で、他のタグとして実際には使われている文字だが、
使っても支障はない。
タグを処理するためのプログラムだが、「,」の処理の部分の関数やクラスを
少し触った関数やクラスを追加すれば良いと思った。
「,」に関する処理があるのは、lib/convert_html.phpのソースなので、
以下の関数などを付け加えた。
|
lib/convert_html.php への追加(1) |
// _ title1 _ title2 _ title3
// _ cell1 _ cell2 _ cell3
// _ cell4 _ cell5 _ cell6
class ZTable extends Element
{
var $col;
function ZTable($_value)
{
parent::Element();
$align = $value = $matches = array();
foreach($_value as $val) {
if (preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches)) {
$align[] =($matches[1] != '') ?
((isset($matches[3]) && $matches[3] != '') ?
' style="text-align:center"' :
' style="text-align:right"'
) : '';
$value[] = $matches[2];
} else {
$align[] = '';
$value[] = $val;
}
}
$this->col = count($value);
$colspan = array();
foreach ($value as $val)
$colspan[] = ($val == '==') ? 0 : 1;
$str = '';
$count = count($value);
for ($i = 0; $i < $count; $i++) {
if ($colspan[$i]) {
while ($i + $colspan[$i] < $count && $value[$i + $colspan[$i]] == '==')
$colspan[$i]++;
$colspan[$i] = ($colspan[$i] > 1) ? ' colspan="' . $colspan[$i] . '"' : '';
$str .= '<td class="style_td_kam2"' . $align[$i] . $colspan[$i] . '>' . make_link($value[$i]) . '</td>';
}
}
$this->elements[] = $str;
}
function canContain(& $obj)
{
return is_a($obj, 'ZTable') && ($obj->col == $this->col);
}
function & insert(& $obj)
{
$this->elements[] = $obj->elements[0];
return $this;
}
function toString()
{
$rows = '';
foreach ($this->elements as $str)
$rows .= "\n" . '<tr class="style_tr">' . $str . '</tr>' . "\n";
$rows = $this->wrap($rows, 'table', ' class="style_table_kam2" cellspacing="1" border="0"');
return $this->wrap($rows, 'div', ' class="ie5_kam2"');
}
}
|
|
lib/convert_html.php への追加(2) |
// "_" - separated table
function & Factory_ZTable(& $root, $text)
{
if ($text == '_') {
return Factory_Inline($text);
} else {
return new ZTable(csv_explode('_', substr($text, 1)));
}
}
|
そして、Bodyクラス内で一ヶ所、追加を行う。
わかりやすく追加の場所を赤文字にしました。
|
lib/convert_html.php の追加(3) |
var $factories = array(
':' => 'DList',
'|' => 'Table',
',' => 'YTable',
'_' => 'ZTable',
'#' => 'Div');
|
そして、新しいタグのデザイン(?)の部分のCSSを触るべく
skin/pukiwiki.css.php に以下のソースを追加する。
テーブルの枠を黒にするための設定を行う。
|
skin/pukiwiki.css.php への追加(1) |
.style_table_kam2 {
padding:0px;
border:0px;
margin:auto;
text-align:left;
color:BLACK;
background-color:BLACK;
}
|
背景を白にする処理を行う。
|
skin/pukiwiki.css.php への追加(2) |
.style_td_kam2 {
padding:5px;
margin:1px;
color:inherit;
background-color:WHITE;
font-size:70%;
}
|
テーブルが左寄せになる処理を行う。
|
skin/pukiwiki.css.php への追加(3) |
|
div.ie5_kam2 { text-align:LEFT; }
|
さて、そして、早速、動かしてみる。
| 実験結果 |
 |
見事、成功! (^^)V
適当にやったのだが、成功したのだ。
しばらく後で、このソースの追加の方法は、正しい事がわかった。
テーブル作成の方法で疑問に感じた事が発生した。
コンテンツを作成する場合、1行づつ処理していく事を説明しました。
コンテンルファイルは、独自タグが変換されないまま保管されている。
Pukiwiki側で、コンテンツファイルの中身のデータを読み込んで、
一度、行別に配列の中に落とし込む。
そして、配列から1行づつデータを取り出して処理するのだ。
だが、ここで大きな疑問が湧いてきた。
テーブルの作成の場合、コンテンツ側では何行かに渡って記述がある。
1行だけのテーブルを作成する場合もあるかもしれないが、
ほとんどの場合は、2行以上だ。
「,」テーブルを作成する場合、記述は2行以上になる
(Pukiwikiでの記述) |
,小野真弓,私のラブラブな人
,岡村孝子,大好きな歌手
,青木裕子,大好きなTBSの女子アナ
|
だが、convert_html.phpで定義されている、Bodyクラスで
コンテンツファイルのデータを、1行づつ読み込んで処理しているはず。
確か、Bodyクラスの $body->parse()関数に処理の内容がある。
Bodyクラスの$body->parse()関数の定義
(lib/convert_html.php) |
function parse(& $lines)
{
$this->last = & $this;
$matches = array();
while (! empty($lines)) {
$line = array_shift($lines);
(処理部分なのだが、省略)
}
}
|
青い部分でコンテンツのデータを1行づつ取り出して処理しているのがわかる。
なので、前後の行と独立して、1行づつ処理していくと考えた場合、
どうやって前後の行の内容と比較して、テーブルと認識できるのだろうか。
よく考えたら不思議だ!
この謎を調べるために、lib/convert_html.phpのソース内の
Bodyクラスを詳しく見る必要がある。
この時、ベートーベンの曲がBGMに流れたのような如く
ジャ
ジャ
ジャ
ジャーン
やはりソースを読む運命なのか (--;;
と思った。
ソースを読まねば中身が把握できないのだが、あまり手を出したくない心境だ。
パンドラの箱を開ける気分だ。だが、不安は的中したのだった。
ソース読みはパニックの連続だった。
Bodyクラスの中を解読していくには、オブジェクトが飛び交うソースを
読まねばならない。
PHPの勉強をした時、PHPのクラスの概念が理解できたと思ったが、
そんな事はなかったのが発覚した。
使えない知識のままだった (^^;;
知識として頭に入れても、実際に使えるのとでは全く違う。
知識としては覚えても、実際に使えないと意味がない。
そういえば、C言語でも同じような体験をしている。
C言語でポインタや構造体を理解したばかりの頃に、データ構造や
アルゴリズムの本を読んだ事がある。
例題のソースを読んだ時、ソース自体は短いのだが、読み慣れない
ポインタや構造体が飛び交うのソースなだけに、パニックに陥った事があった。
というわけで、Bodyクラスの部分と「,」のテーブルタグの部分の解読の話を
書いて行く事にしました。
Bodyクラスの部分と「,」のテーブルタグの部分。
最初から「,」のテーブルの処理部分を読めば、早く理解できるだろうと考え、
YTableのクラスの部分から読んでみる事にした。
「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
class YTable extends Element
{
var $col;
function YTable($_value)
{
parent::Element();
$align = $value = $matches = array();
foreach($_value as $val) {
if (preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches)) {
$align[] =($matches[1] != '') ?
((isset($matches[3]) && $matches[3] != '') ?
' style="text-align:center"' :
' style="text-align:right"'
) : '';
$value[] = $matches[2];
} else {
$align[] = '';
$value[] = $val;
}
}
|
上の青い部分に着目する。
Perl互換の正規表現だ。
正規表現を読み慣れていないので、なかなか処理の内容が見えない。
「,」タグでのテーブルの仕様と見比べる。
「, A,」のように「A」という文字の左に一文字の空白があると
「A」はテーブルの中では右寄せとなり、
「, B ,」のように、左右に余白があると、中央寄せという意味だ。
その事を踏まえて青い部分を見てみる。
preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches)
そして実験的にソースを作って「, A, B ,C,」という文字列は
どう処理されるのか見てみた。
|
実験のためのソース |
<HTML><HEAD><TITLE>test</TITLE></HEAD>
<BODY>
<?php
$matches = array();
$val = ", A, B ,C,";
preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches);
print_r($matches);
?>
</BODY></HTML>
|
そして、ブラウザでの出力結果を見てみるのだが・・・
|
出力結果 |
Array ( [0] => , A, B ,C, [1] => [2] => , A, B ,C, )
|
上手に分類されてへん
一体、どうやって左寄せや、中央寄せの分類の処理をしているのか
わからなくなってきた。
実際には、1行のデータそのものが、YTableのクラスに送られるわけでない。
しかし、この時は、1行のデータが処理される物ばかりと思い込んでいたため
上のような混乱を招いた。
この誤解が解ける話は後述しています。
行き詰まりを見せたので、別の部分に着手する。
まずは、1行づつコンテンツを取り出した部分の処理、
すなわち、Bodyクラスの定義部分を見てみる。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
var $factories = array(
':' => 'DList',
'|' => 'Table',
',' => 'YTable',
'#' => 'Div');
(コンテンツのデータを1行ごとの文字列にして取り出す)
while (! empty($lines)) {
$line = array_shift($lines);
(コンテンツの文字列の1文字目の文字を取り出す)
// The first character
$head = $line{0};
(1文字目が「,」の場合の処理)
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
1文字目が「,」だと、「,」テーブルの処理という場合分けが行われ、
$this->last = & $this->last->add($factoryname($this, $line)); に進む。
ここでの$factoryname($this, $line) は、Factory_YTable($this, $line) だ。
|
まずは、$this->last の変数に着目した。
Bodyクラスは、Elementクラスの子クラスになる。
Elementクラスの定義の一部分を抜粋
(lib/convert_html.php) |
// ブロック要素
class Element
{
var $parent; // 親要素
var $last; // 次に要素を挿入する先
var $elements; // 要素の配列
|
つまり Bodyクラスで見られた $this->last の変数は、
次の要素を挿入する先というわけだ。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
(1文字目が「,」の場合の処理)
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
さて、$this->lastに、& $this->last->add()の値が代入されるので
一体、どんな物なのかソースを追いかけてみた。
Elementクラスに定義されている、add()関数を見てみた。
Elementクラスの定義のadd()関数の定義部分を抜粋
(lib/convert_html.php) |
function & add(& $obj)
{
if ($this->canContain($obj)) {
return $this->insert($obj);
} else {
return $this->parent->add($obj);
}
}
|
どうやら各クラスのオブジェクトがあり、それが代入されているようだ。
そのため、この変数の意味は次のように考えた。
|
Bodyクラスの、$last変数の意味 |
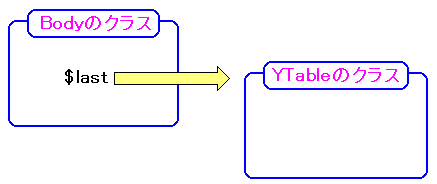 |
$lastには、現在、処理中のテーブルなどの処理するオブジェクトが
代入されている。
|
そして、$parentという変数名もある事から、数珠つなぎのように、
次のようなオブジェクトの数珠があると考えた。
|
オブジェクトの数珠つなぎ |
 |
最初のクラスはBodyだが、「,」テーブルや、「|」などが出てくる度に
各クラスの$parent と、$lastは、前後に処理するクラスと連結されると
考えた。
これはC言語で言うデータ構造の考え方を、そっくり当てはめた物だった。
|
だが、実際には数珠つなぎにはなっていない。
単にソースを詳しく読まなかったために、数珠つなぎと読み違えたのだ。
しばらく、数珠つなぎの発想で読んで行くと
全くソースの中身が理解できへん (TT)
だった。
ドツボにハマっていくのが自分でもわかる。
幸いな事に、復旧作業で時間に追われているわけではない。
なので、最初から出直す方が賢いと考えた。
そこで、頭を白紙する事にした。
そして、横着せずに、しっかりとソースを読み直す事にした。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
(1文字目が「,」の場合の処理)
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
青い部分を見る。
$this->last に代入する値が何かを、じっくりと追いかける事にした。
まずは、$factoryname($this, $line) を見てみる。
これは $factoryname自体が文字列変数なので、「,」のタグの処理の場合は
以下の関数を意味する。
Factory_YTable($this, $line) だ。
そこで、Factory_YTable($this, $line) 関数を追いかける。
ちなみに、この関数の引数は、呼び出した自分自身(オブジェクト)と
コンテンツのデータ(行)なのだ。
Factory_YTable($this, $line)の定義
(lib/convert_html.php) |
// Comma-separated table
function & Factory_YTable(& $root, $text)
{
if ($text == ',') {
return Factory_Inline($text);
} else {
return new YTable(csv_explode(',', substr($text, 1)));
}
}
|
この処理を見ると、コンテンツのデータので、1文字だけの行で
しかもその1文字が「,」の場合、テーブルではないという事で処理され、
残りのケースはテーブルとして処理される。
|
csv_explode(',', substr($text, 1))を見て行く。
まずは、substr($text, 1)の部分から。
これはコンテンツのデータで2文字目からのデータを取り出す意味だ。
引数では「1」となっている。これは先頭から1バイト目の文字からという意味だ。
なので、半角文字で考えると、引数が「1」の場合は、2文字目となる。
引数の指定は「先頭から何バイト目の文字」という意味なので、
何文字目という発想ではないので、慣れるまで、間違いやすいかも (^^;;
「,A,B,C」という文字列の場合、上の関数で処理すると「A,B,C」となる。
そして、csv_explode(',', substr($text, 1))を見る。
csv_explode()関数は、lib/func.phpで定義されている。
|
csv_explode()関数の定義 (lib/func.php) |
// Explode Comma-Separated Values to an array
function csv_explode($separator, $string)
{
$retval = $matches = array();
$_separator = preg_quote($separator, '/');
if (! preg_match_all('/("[^"]*(?:""[^"]*)*"|[^' . $_separator . ']*)' .
$_separator . '/', $string . $separator, $matches))
return array();
foreach ($matches[1] as $str) {
$len = strlen($str);
if ($len > 1 && $str{0} == '"' && $str{$len - 1} == '"')
$str = str_replace('""', '"', substr($str, 1, -1));
$retval[] = $str;
}
return $retval;
}
|
これを見た時、目が点になった。
一体、どういう関数やねん・・・
正規表現を解読する気が起こらないので、関数の動作から
どういう働きをするのか見てみる事にした。
返り値を格納する変数 $retval は配列のようだ。
そこで、以下の実験ソースを書いてみた。
|
実験のソース |
<HTML><HEAD><TITLE>test2</TITLE></HEAD>
<BODY>
<?php
// Explode Comma-Separated Values to an array
function csv_explode($separator, $string)
{
$retval = $matches = array();
$_separator = preg_quote($separator, '/');
if (! preg_match_all('/("[^"]*(?:""[^"]*)*"|[^' . $_separator . ']*)' .
$_separator . '/', $string . $separator, $matches))
return array();
foreach ($matches[1] as $str) {
$len = strlen($str);
if ($len > 1 && $str{0} == '"' && $str{$len - 1} == '"')
$str = str_replace('""', '"', substr($str, 1, -1));
$retval[] = $str;
}
return $retval;
}
$moji = "A,B,C" ;
$output = array();
$output = csv_explode(',',$moji);
print_r($output);
?>
</BODY></HTML>
|
早速、実験結果をブラウザで見てみる事にした。
|
実験結果 |
Array ( [0] => A [1] => B [2] => C )
|
「,」区切りだった文字列を、「,」の区切りの文字列に分解して
配列している事がわかる。
つまり図にすると次のような図式になる。
|
csv_explode()関数の図式として |
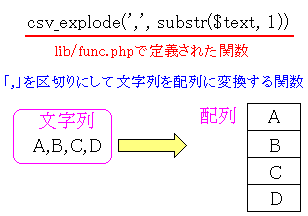 |
再び、Factory_YTable($this, $line) 関数を追いかける。
Factory_YTable($this, $line)の定義
(lib/convert_html.php) |
// Comma-separated table
function & Factory_YTable(& $root, $text)
{
if ($text == ',') {
return Factory_Inline($text);
} else {
return new YTable(csv_explode(',', substr($text, 1)));
}
}
|
青い部分は「,」で区切られた文字列を分解して、配列した物を引数に、
YTableのオブジェクトを作成している。
|
そこで、再び、YTableクラスの定義を眺めてみる事にした。
YTableのクラスの定義の部分を抜粋
(lib/convert_html.php) |
class YTable extends Element
{
var $col;
function YTable($_value)
{
parent::Element();
$align = $value = $matches = array();
foreach($_value as $val) {
if (preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches)) {
$align[] =($matches[1] != '') ?
((isset($matches[3]) && $matches[3] != '') ?
' style="text-align:center"' :
' style="text-align:right"'
) : '';
$value[] = $matches[2];
} else {
$align[] = '';
$value[] = $val;
}
}
(以下省略)
|
赤い部分は仮引数で、「,」区切りの文字列を分解して配列にした物だ。
青い部分は、送られてきた配列を、一つづつ取り出し処理するための部分。
ピンクの部分は、左寄せか、中央寄せか、右寄せかを判定させる正規表現。
|
上のような流れだとソースを見て、左寄せか中央寄せか右寄せかを
分類できるのが納得できる。
試しに実験を行ってみる。
|
実験のソース |
<HTML><HEAD><TITLE>test3</TITLE></HEAD>
<BODY>
<?php
$matches = array();
$valarr = array(' A',' B ','C');
foreach($valarr as $val) {
preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches);
print_r($matches);
print "<BR>\n" ;
}
?>
</BODY></HTML>
|
赤の「A」は右寄せのため、文字の左側に空白を入れた。
青の「B」は真中寄せのため、文字の両側の空白を入れた。
ピンクの「C」は左寄せなので、空白は入れていない。
matches[0]には正規表現の対象の文字列が入る。
なので、ここは全て表示される。
matche[1]は文字の左側に空白があった場合に空白文字が入る。
matche[2]は、左側、もしくは右側にある空白部分を排除した
文字列が入る。もちろん、両側に空白文字がない場合も、
この部分には文字列が入ってくる。
matche[3]は文字の右側に空白があった場合に空白文字が入る。
|
さて、実験結果をブラウザで見てみる。
|
実験結果 |
Array ( [0] => A [1] => [2] => A )
Array ( [0] => B [1] => [2] => B [3] => )
Array ( [0] => C [1] => [2] => C )
|
何せ、空白文字を表示させるため
結果の内容が、全く見えない・・・ (--;
そこで空白を見やすくしてみた。
|
実験のソース |
<HTML><HEAD><TITLE>test3</TITLE></HEAD>
<BODY>
<?php
$matches = array();
$valarr = array(' A',' B ','C');
foreach($valarr as $val) {
preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches);
// 右側に空白文字を入れた場合、matches[1] に 'BLANK' を代入
if ( $matches[1] != '' ) $matches[1] = 'BLANK' ;
print_r($matches);
print "<BR>\n" ;
}
?>
</BODY></HTML>
|
赤の「A」は右寄せのため、文字の左側に空白を入れた。
青の「B」は真中寄せのため、文字の両側の空白を入れた。
ピンクの「C」は左寄せなので、空白は入れていない。
茶色の部分は、右寄せ、及び、真中寄せをした時に
$matches[1]の空白文字を「BLANK」に変換する処理。
|
早速、ブラウザで実験結果を見てみる事にした。
|
実験結果 |
Array ( [0] => A [1] => BLANK [2] => A )
Array ( [0] => B [1] => BLANK [2] => B [3] => )
Array ( [0] => C [1] => [2] => C )
|
これだとわかりやすい (^^)V
これで右寄せ、真中寄せ、左寄せが分類できる。
そして、YTableクラスを追いかけてみる。
YTableのクラスの定義の部分を抜粋
(lib/convert_html.php) |
class YTable extends Element
{
var $col;
function YTable($_value)
{
parent::Element();
$align = $value = $matches = array();
foreach($_value as $val) {
if (preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches)) {
$align[] =($matches[1] != '') ?
((isset($matches[3]) && $matches[3] != '') ?
' style="text-align:center"' :
' style="text-align:right"'
) : '';
$value[] = $matches[2];
} else {
$align[] = '';
$value[] = $val;
}
}
(以下省略)
|
右寄せ、真中寄せ、左寄せの処理が見える。
赤い部分は右寄せ、もしくは、真中寄せの場合を意味する。
そして、青い部分は、真中寄せの場合を意味する。
場合分けした後、<TD>タグの中につける属性の指定を行う。
真中寄せなら「style="text-align:center"」で
右寄せなら「style="text-align:right"」だ。
|
さて、この後の処理を見ていく事にする。
YTableのクラスの定義の部分を抜粋
(lib/convert_html.php) |
class YTable extends Element
{
var $col;
function YTable($_value)
{
parent::Element();
$align = $value = $matches = array();
foreach($_value as $val) {
if (preg_match('/^(\s+)?(.+?)(\s+)?$/', $val, $matches)) {
$align[] =($matches[1] != '') ?
((isset($matches[3]) && $matches[3] != '') ?
' style="text-align:center"' :
' style="text-align:right"'
) : '';
$value[] = $matches[2];
} else {
$align[] = '';
$value[] = $val;
}
}
$this->col = count($value);
$colspan = array();
foreach ($value as $val)
$colspan[] = ($val == '==') ? 0 : 1;
$str = '';
$count = count($value);
for ($i = 0; $i < $count; $i++) {
if ($colspan[$i]) {
while ($i + $colspan[$i] < $count && $value[$i + $colspan[$i]] == '==')
$colspan[$i]++;
$colspan[$i] = ($colspan[$i] > 1) ? ' colspan="' . $colspan[$i] . '"' : '';
$str .= '<td class="style_td"' . $align[$i] . $colspan[$i] . '>' . make_link($value[$i]) . '</td>';
}
}
$this->elements[] = $str;
}
|
赤い部分は、このテーブルが何列かを記録する部分。
この時は気づかなかったが、後で、この記録がテーブルの表示において
重要な意味を持つ。
青い部分は、抜き出した文字列に<TD>タグをつけている部分。
タグの要素なども、ここでつけている。
「$str .= 追加部分」という記述なので、全て処理した文字列を
ダンゴのように連結させている。
いわば「<TD>A</TD> <TD>B</TD> <TD>C</TD>」のように。
ちなみに青い部分の中にある make_link()関数は、&color()などの
インライン型のプラグイン処理などに使われる関数です。
この部分を解読した時点では、make_link()関数までは解読していませんでし
ここで取り上げると話がややこしくなるので、後述しています。
ピンクの部分は、このオブジェクトに処理済みの文字列、すなわち、
<TD>タグ付きの文字列のタンゴを保管させている。
この部分は、$this->element[]と配列の形になっている。
文字列の保管なので、別に配列にする必要がなさそうに思えるのだが、
配列にしているのには理由があるからだ。
それは後述しています。
|
これで、YTableクラスでの一連の処理が見えた。
だが、これだけでは、1行づつコンテンツを処理する部分だけで
複数行にまたがるテーブルのコンテンツを認識させる部分までは
解読できていない。
ここまでYTableクラスの中身を見てきたが、処理の過程の中で
記録されている変数などは、YTableクラスのオブジェクトの中に入る。
このオブジェクトは、どこに保管されるのか。
というわけで、Bodyクラスのソースを見てみる。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
|
上のままだと見にくいので、ソースを以下のように読みかえてみる。
|
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add(データ処理済みの、YTableのオブジェクト);
continue;
}
}
|
ふと思った。
$this->last の変数とは一体、何やねん
この疑問が湧いてくる。
だが、いきなり $this->last 変数、すなわち、Bodyクラスで宣言された
オブジェクトの中にある $last 変数が何かを知る前に、その手前の部分から
調べて行く事にした。
すなわち、 $this->last に代入される値から、$this->last 変数が
何かを推測していく事にした。
まずは、$this->last 変数の初期値を見てみる。
Bodyクラスのオブジェクトを宣言して、値を代入した時、
すなわち、初期の $last の値は、Bodyクラスの定義を見たらわかる。
|
初期の $last の値(Bodyクラスの定義を見て) |
function parse(& $lines)
{
$this->last = & $this;
(以下、省略)
|
これを見て、
なんや、自分自身やん!!
と思った。
つまり、Bodyクラスの中で、コンテンツの処理を行う parse()関数が
稼働すると同時に、オブジェクト自身が、$lastに代入されるのだ。
図で表すと、以下のような事が行われている。
|
Bodyクラスのオブジェクトが初期化される時 |
 |
さて、話はわかりやすくするため、コンテンツの1行目から
「,」のタグのテーブルのデータという事で話を進めます。
$this->last->add()は、ここでは、Bodyクラスのadd()関数となる。
そこで、Bodyクラスのadd()関数を見てみる事にしたが、特にBodyクラスでは
add()関数は定義されていないので、親クラスのElementクラスのadd()関数を、
そのまま継承している事になる。
後で重要になってくる話だが、YTableクラスの場合も、
add()関数が定義されていないので、親クラスのElementクラスのadd()関数を
そのまま継承している事になる。
そこで、Elementクラスのadd()関数を見てみる事にした。
|
Elementクラスのadd()関数 |
function & add(& $obj)
{
if ($this->canContain($obj)) {
return $this->insert($obj);
} else {
return $this->parent->add($obj);
}
}
|
この関数の仮引数の「 $obj 」だが、ここでは「,」テーブルの処理なので
YTableクラスで定義され、コンテンツの1行分の処理を行ったデータが入った
オブジェクトの事だ。
もっと、わかりやすく書けば、現在、コンテンツの処理を行っている
オブジェクトだ。
|
これだけでは一体、何を行う関数なのか、よくわからない。
そこで、$this->canContain()関数を見てみる事にする。
この関数も、Bodyクラスには定義されていない事から、親クラスの
ElementクラスのcanContain()関数を、そのまま継承している事になる。
|
ElementクラスのcanContain()関数 |
function canContain($obj)
{
return TRUE;
}
|
これを見て
なんじゃ、こりゃ (・o・)
と思った。単に「TRUE」を返しているだけだ。
そして、もう一度、add();関数を見てみる。
|
Elementクラスのadd()関数 |
function & add(& $obj)
{
if ($this->canContain($obj)) {
return $this->insert($obj);
} else {
return $this->parent->add($obj);
}
}
|
$this->canContain($obj) での返り値が TRUEなので、
$this->insert()関数が動く事になる。
そこで、Bodyクラスで定義されている、insert()関数を見てみる。
|
Bodyクラスのinsert()関数 |
function & insert(& $obj)
{
if (is_a($obj, 'Inline')) $obj = & $obj->toPara();
return parent::insert($obj);
}
|
この話での $obj は、YTableクラスのオブジェクトになるため、
is_a($obj, 'Inline' の結果は、FALSE になる。
そして、return parent::insert($obj); が実行される。
|
parent::insert($obj); という命令がある。
これは、Bodyクラスで定義した insert() ではなく、Bodyクラスの親の
Elementクラスで定義した insert() を使うという意味だ。
そこで、Elementクラスで定義した insert() を見てみる。
|
Elementクラスのinsert()関数 |
function & insert(& $obj)
{
$obj->setParent($this);
$this->elements[] = & $obj;
return $this->last = & $obj->last;
}
|
赤い部分は、現在、処理中のオブジェクト(YTableクラス)の中の
setParent()関数に、自分自身のオブジェクト(Bodyクラス)を代入している。
その結果、処理中のオブジェクト(YTableクラス)の変数 $parent は
Bodyクラスのオブジェクトが入る。
青い部分は、Bodyクラスの $elements[]配列の中に、現在、処理中の
YTableのオブジェクトを代入する。
ピンクの部分は、Bodyクラスの $last変数に、YTableのオブジェクトを代入する。
|
上の説明だけだと、青い部分と、ピンクの部分がわかりずらいので、
図にしてみる事にした。
|
青い部分はこういう事 |
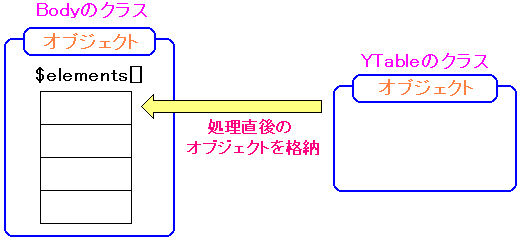 |
Bodyクラスの中の配列 $elements[] だが、処理したオブジェクトを
格納するためにある。
1行づつコンテンツデータが処理されるたびに、$elements[]配列の中に
個々のオブジェクトが格納される。
これは後で説明するが、ブラウザにコンテンツを表示させる際に、
個々に処理したオブジェクトに格納されているコンテンツデータを
出力させるため、配列にオブジェクトを保管させているのだ。
|
ピンクの部分の$this->last = & $obj->last;だが、
$obj 変数は、処理直後(ここではYTableクラス)のオブジェクトだ。
$obj->last 変数だが、処理直後のオブジェクトそのものだ。
YTableクラスのオブジェクトの初期化の際、Bodyクラスと同様に
以下の事が行われる。
|
YTableクラスのオブジェクトの初期化 |
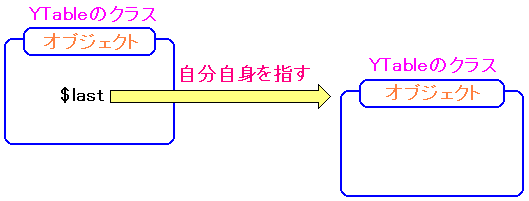 |
つまり自分自身を指しているわけだ。
なので、$this->last = & $obj->last;という意味は、
以下のような事になる。
|
ピンクの部分を図にすると |
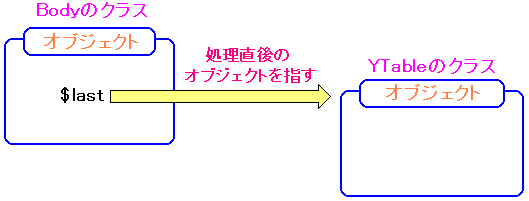 |
返り値も、処理直後のオブジェクトだ。
この返り値は、Bodyの定義の部分の以下の青い部分を指す。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
ここでわかった事!
$this->lastは、1つ前の処理したオブジェクトを指す。
これで1行目の「,」のテーブルの処理が終わる。
さて、2行目も「,」のテーブルが記述されている場合を考える。
実は、ここから個々に独立しているはずの行が、複数行にわたり
「,」のテーブルの記述を構成していて、かつ、前後の行が
同じテーブルの記述である事を認識できる事が解明できる。
2行目の「,」の記述の処理を行う。
1行目の処理と同様に、以下のソースに出会う。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
|
上のままだと見にくいので読みかえると |
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add(2行目のデータ処理のオブジェクト);
continue;
}
}
|
上の青い部分の追っかけを行う。
$this->last->add();を見る
2行目以降の処理の場合、$this->last は、1つ前の処理したオブジェクトを
指しているのだ。
1行目の処理の場合、$this->last は、Bodyクラスのオブジェクトを
指していたのに対して、2行目の場合は、1つ前に処理したオブジェクト、
すなわち、ここでは、YTableクラスのオブジェクトを指している。
なので、YTableクラスで定義されている add()関数を見る必要がある。
だが、YTableクラスでは、add()関数は定義されていないため、
親クラスのElementクラスで定義されたadd()関数が使われる。
|
Elementクラスのadd()関数 |
function & add(& $obj)
{
if ($this->canContain($obj)) {
return $this->insert($obj);
} else {
return $this->parent->add($obj);
}
}
|
さて、問題はcanContain()関数だ。
そこで、YTableクラスで定義されたcanContain()関を見てみる。
YTableクラスのcanContain()関数の定義
(lib/convert_html.php) |
function canContain(& $obj)
{
return is_a($obj, 'YTable') && ($obj->col == $this->col);
}
|
赤い部分と青い部分を同時に満たせば、TRUEを返し、それ以外だとFALSEを返す
まずは、赤い部分を見てみる。
ここでの $obj は処理直後のオブジェクトで、$this は一つ前の処理の
オブジェクトを指す。
処理直後のオブジェクトのクラス名と、1つ前に処理したオブジェクトの
クラス名が同じかどうかのチェックを行う。
この場合、2回連続、YTableクラスのオブジェクトの処理の話なので、
赤い部分の条件は満たされる。
青い部分を見てみる。
YTableクラス内の変数 $col は、何列のテーブルかを記録している変数だ。
なので、処理直後のオブジェクトに格納されているテーブルの列の数と
1つ前の処理されたオブジェクトに格納されているテーブルの列の数とを
比較している。もし、同じ数であれば、青い部分の条件は満たされる。
実は、ここに1つの処理と、処理直後のテーブルとが同じ物か
別物なのかの区別をしているのだ!
|
赤い部分と青い部分の両方を満たせば、返り値は TRUE になる。
そこで、add()関数の戻ってみる。
|
Elementクラスのadd()関数 |
function & add(& $obj)
{
if ($this->canContain($obj)) {
return $this->insert($obj);
} else {
return $this->parent->add($obj);
}
}
|
もし、$this->canContain($obj) がTRUEならば、
$this->insert($obj) の関数が動く。
この場合、YTableクラスで定義されたinsert()関数なので、
それを見てみる。
|
YTableクラスのinsert()関数 |
function & insert(& $obj)
{
$this->elements[] = $obj->elements[0];
return $this;
}
|
赤い部分は、1つ前に処理したオブジェクトの中に格納された
処理済みのコンテンツのデータが入った配列だ。
青い部分は、処理直後のオブジェクトに格納された
処理済みコンテンツのデータだ。
文字列なので配列の先頭に格納されているのでelement[0]となる。
なんとここで、1つ前に処理されたオブジェクトの中にある
処理済みコンテンツ用の配列の中に、追加という形で、
処理直後の処理済みコンテンツのデータが入れられる。
図にすると以下のようになる。
|
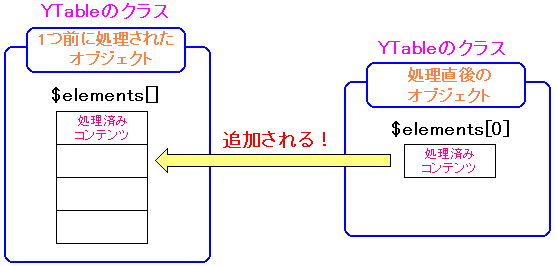 |
そして、最後のピンクの部分 return $this; だが、
1つ前に処理したオブジェクトを返り値にしている。
|
その結果、この部分を読みかえると以下のようになる。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
|
上のソースを読みかえると |
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & 1つ前に処理したオブジェクト
continue;
}
}
|
つまりYTableのクラスのオブジェクトの処理が連続して続き、
しかもテーブルの列が同じであれば、最初のYTableクラスのオブジェクトが
Bodyクラスのオブジェクトの $last 変数に格納されるわけだ。
まぁ、簡単に言ってみれば、$lastの値を、新しいオブジェクトに
変更していないというわけだ。
$this->last があるお陰で
処理直後のコンテンツと、1つ前に処理したコンテンツとの関連性を
チェックする事ができるのだ!
もし、1行目が「,」テーブルのタグが使われていて、
2行目はテーブルとは違う物や、もしくは、列の数が違う「,」タグの
テーブルだった場合なら、どうなるのか。
そこで、1行目が「,」タグのテーブルで、2行目が「*」の見出しの場合を
考えてみる。
後述していますが、「*」の見出しの処理は、Headingクラスの
オブジェクトで行われている。
1行目が「,」タグで、2行目が「*」見出しの場合の、
2行目からの処理の話をしたいと思います。
2行目の処理を開始する時、Bodyクラスでのオブジェクトの働きを見てみる。
Bodyクラスの「,」タグ処理の部分の抜粋
(lib/convert_html.php) |
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
}
|
|
上のままだと見にくいので、ソースを以下のように読みかえてみる。
|
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add(データ処理済みの、Headingのオブジェクト);
continue;
}
}
|
$this->last->add();を見る
$this->last は、1つ前の処理(1行目の処理)の YTableクラスのオブジェクトだ。
$this->last->add();は、この場合は、YTableクラスのadd()関数の事だ。
だが、YTableクラスでは、add()関数は定義されていないため、
親クラスのElementクラスで定義されたadd()関数が使われる。
|
Elementクラスのadd()関数 |
function & add(& $obj)
{
if ($this->canContain($obj)) {
return $this->insert($obj);
} else {
return $this->parent->add($obj);
}
}
|
さて、canContain()関数では、FALSEが返される。
なぜなら、TRUEの場合は、1つ前の処理と、処理されたばかりの物が
同じYTableクラスのオブジェクトで、しかも、同じ列のテーブルの場合だけだ。
というわけで、この場合は、$this->parent->add($obj);が処理される。
1つ前の処理のオブジェクト $this なのだが、この変数 $parent は、
$Bodyクラスのオブジェクト自身を指している。
なぜなら、1行目のYTableクラスのオブジェクトの処理の際に、
$parent 変数は、Bodyクラスのオブジェクトを指すように設定されているからだ。
となればFONT COLOR="BLUE">$this->parent->add($obj);、は
Bodyクラスで定義されたadd()関数というわけだ。
Bodyクラスのadd() は、Elementクラスのadd()関数を、そのまま
継承しているので、Elementクラスのadd()関数を見てみる。
|
Elementクラスのadd()関数 |
function & add(& $obj)
{
if ($this->canContain($obj)) {
return $this->insert($obj);
} else {
return $this->parent->add($obj);
}
}
|
Bodyクラスの、canContain()関数は、無条件に、TRUEを返す話をしました。
なので、ここでは、$this->insert($obj);が動きます。
そこで、Bodyクラスで定義されている、insert()関数を見てみる。
|
Bodyクラスのinsert()関数 |
function & insert(& $obj)
{
if (is_a($obj, 'Inline')) $obj = & $obj->toPara();
return parent::insert($obj);
}
|
この話での $obj は、Headingクラスのオブジェクトになるため、
is_a($obj, 'Inline' の結果は、FALSE になる。
そして、return parent::insert($obj); が実行される。
|
parent::insert($obj); という命令がある。
これは、Bodyクラスで定義した insert() ではなく、Bodyクラスの親の
Elementクラスで定義した insert() を使うという意味だ。
そこで、Elementクラスで定義した insert() を見てみる。
|
Elementクラスのinsert()関数 |
function & insert(& $obj)
{
$obj->setParent($this);
$this->elements[] = & $obj;
return $this->last = & $obj->last;
}
|
赤い部分は、現在、処理されたばかりのHeadingクラスのオブジェクトの中の
setParent()関数に、自分自身のオブジェクト(Bodyクラス)を代入している。
その結果、処理されたばかりのオブジェクトの変数 $parent は
Bodyクラスのオブジェクトが入る。
青い部分は、Bodyクラスの $elements[]配列の中に、現在、処理されたばかりの
Headingクラスのオブジェクトを代入する。
ピンクの部分は、Bodyクラスの $last変数に、処理されたばかりの
Headingクラスのオブジェクトを代入する。
|
つまり、1行目が「,」のテーブルで、2行目が「*」の見出しの処理の場合、
2行目は、1行目のオブジェクトの事を全く気にする事なく、
Bodyクラスのオブジェクトの中の $elements[] 配列に、2行目の処理の
オブジェクトを入れる事になる。
要するに、上手に $this-$gt;last を使って、1つ前の処理した
オブジェクトと比較して、場合分けして処理を行っているのだ。
ふぅ、なんとかして「,」タグのテーブルの解読ができた。
オブジェクトが飛び交うソースなんぞ、今まで読んだ事がないだけに
メチャクチャ労力がいる。
もう、ソースの解読するのは面倒だからやりたくないと思っていたら、
部長から「見出しの十字架、なんとかならんか」と言われた。
Pukiwikiで、見出しのを出力される時、以下の編集を行う。
|
見出しの作成(Pukiwikiでの編集では) |
** おしらせ
|
| 出力結果 |
 |
さて、十字架とは何か。次の図で示した物の事だ。
|
見出しの十字架 |
 |
この十字架が気になるというのだ。
その上、同じページで見出しが2つ以上あると、2つ目以降からは
見出しの右上に上向きの矢印「↑」が出てくる。
|
見出しの右上の矢印「↑」 |
 |
この矢印「↑」も消さないといけないのだ。
つまり・・・
ソースを読まねばならぬのらー!!
だった (--;;
まずは十字架を消す事から考える。
そこで、Pukiwikiで吐き出されたHTMLのソースを見てみる。
|
Pukiwikiで吐き出されたソース |
<h3 id="content_1_0">お知らせ <a class="anchor_super"
id="wbf317c3" href="http://***********/index.php?FrontPage#wbf317c3"
title="wbf317c3">†</a></h3>
|
(注意)
本当は1行で吐き出される部分なのですが、見やすいように意図的に
改行を入れました
|
見出しにリンクがくっついてきている。
しかも十字架ではなく「†」になっている。
「一体、これは何?」と思った。
そこで「dagger」を英和辞典で調べてみると「剣」という意味だった。
なんと十字架だと思っていたのは、実は、剣だった!!
しかし、どう見ても剣ではなく、十字架にしか見えない。
それはフォントの問題のようだ。そこで、MS P明朝体で、しかも、
文字の大きさを拡大させてみた。
|
「†」の正体 |
 |
|
ついでに読者の方が見ているフォントでは |
| † |
剣というよりも、飾り物にしか見えないのだが (^^;;
この話は、これぐらいにしまして、本題に戻ります。
さて、Bodyクラスの「*」見出し処理についてみてみる。
Bodyクラスの「*」見出し処理
(lib/convert_html.php) |
// Heading
if ($head == '*') {
$this->insert(new Heading($this, $line));
continue;
}
|
|
処理する行の先頭文字が「*」なら、見出し処理を行うという意味だ。
|
まずは、Headingクラスでの処理が行われるので、青い部分の処理を見て行く。
引数の $this はBodyクラスのオブジェクト、つまり自分自身。
$line は処理する見出しの行の事だ。
Headingクラスを抜粋
(lib/convert_html.php) |
// * Heading1
// ** Heading2
// *** Heading3
class Heading extends Element
{
var $level;
var $id;
var $msg_top;
function Heading(& $root, $text)
{
parent::Element();
$this->level = min(3, strspn($text, '*'));
list($text, $this->msg_top, $this->id) = $root->getAnchor($text, $this->level);
$this->insert(Factory_Inline($text));
$this->level++; // h2,h3,h4
}
function & insert(& $obj)
{
parent::insert($obj);
return $this->last = & $this;
}
function canContain(& $obj)
{
return FALSE;
}
function toString()
{
return $this->msg_top . $this->wrap(parent::toString(),
'h' . $this->level, ' id="' . $this->id . '"');
}
}
|
さて、まずはHeadingクラスの最初の処理を見て行く事にする。
Headingクラスを抜粋
(lib/convert_html.php) |
// * Heading1
// ** Heading2
// *** Heading3
class Heading extends Element
{
var $level;
var $id;
var $msg_top;
function Heading(& $root, $text)
{
parent::Element();
$this->level = min(3, strspn($text, '*'));
list($text, $this->msg_top, $this->id) = $root->getAnchor($text, $this->level);
$this->insert(Factory_Inline($text));
$this->level++; // h2,h3,h4
}
(以下、省略)
|
赤い部分は、先頭から何文字「*」が続いているのかチェックして、
その数を $level 変数に代入している。
「*」が4文字以上続く場合は、$level には「3」が代入される。
青い部分だが、getAnchor();関数の返り値は、3つの要素を持った配列だが、
配列に入った値を $text , $msg_top , $id の変数に振り分けている部分だ。
ピンクの部分だが、行の中に、インライン型のプラグインなどが
含まれている場合の処理が行われるのだが、この時点では
パンドラの箱を開ける気がなかったので、封印しようと思った。
しかし、あとで解読するハメになり、インライン型のプラグインの
処理などが記述されている事をする。詳しくは後述しています。
|
青い部分に着目する。
list($text, $this->msg_top, $this->id) = $root->getAnchor($text, $this->level);
$root は、Bodyクラスのオブジェクトの事を指す。
なので、$root->getAnchor()関数は、Bodyクラスで定義された関数になる。
getAnchor()関数の処理を見てみる事にする。
Bodyクラスの getAnchor()関数
(lib/convert_html.php) |
function getAnchor($text, $level)
{
global $top, $_symbol_anchor;
(以下省略)
|
上の赤い部分の $top 変数と、青い部分の $_symbol_ancho 変数は
ともにグローバル変数だ。
という事は、どっかで値が代入されているはず。
まずは $top 変数から。
default.ini.php のソースの中で、変数の値が代入されている。
|
default.ini.php のソースの中 |
|
$top = $_msg_content_back_to_top;
|
さて、$_msg_content_back_to_top 変数だが、これも、どこかの部分で
値が代入されているはず。調べてみると、ja.lng.php ソースの中にある。
|
ja.lng.php のソースの中 |
$_msg_content_back_to_top = '<div class="jumpmenu">
<a href="#navigator">↑</a></div>';
|
(注意)
実際には、1行で書かれているのですが、読みやすくするため
意図的に改行をいれました。
|
ちなみに↑は上向きの矢印で、実際に下に表示させてみた。
↑
この矢印は、2つ目以降の見出しの右上に出てくる物だ。
回りくどくなったが、$top 変数は以下の文字列の値が入るというわけだ。
|
$top の値の中身は |
'<div class="jumpmenu"><a href="#navigator">↑</a></div>';
|
えらい長い変数の値だが、これは何なのだろうか。
見出しの右上に「↑」を表示させるための物なのだ。
あとでわかった事だが、「↑」の表示をさせる方法を、HTML上での表現で、
以下の図にしてみた。
|
HTML上での表現では |
 |
さて、2つ目のグローバル変数の $_symbol_ancho 変数は
これもja.lng.php のソースの中にあった。
|
ja.lng.php のソースの中 |
|
$_symbol_anchor = '†';
|
変数 $_symbol_anchor だが、これは十字架ならぬ「剣」の文字が入る。
Bodyクラスの getAnchor()関数
(lib/convert_html.php) |
function getAnchor($text, $level)
{
global $top, $_symbol_anchor;
// Heading id (auto-generated)
$autoid = 'content_' . $this->id . '_' . $this->count;
$this->count++;
// Heading id (specified by users)
$id = make_heading($text, FALSE); // Cut fixed-anchor from $text
if ($id == '') {
// Not specified
$id = & $autoid;
$anchor = '';
} else {
$anchor = ' &aname(' . $id . ',super,full){' . $_symbol_anchor . '};';
}
$text = ' ' . $text;
// Add 'page contents' link to its heading
$this->contents_last = & $this->contents_last->add(new Contents_UList($text, $level, $id));
// Add heding
return array($text . $anchor, $this->count > 1 ? "\n" . $top : '', $autoid);
}
|
仮引数の $text は、処理する行のデータ。
$levelは行の先頭から「*」が何個あるのかの数字だ。
ただし、3つ以上「*」場合は、3の値になっている。
赤い部分は、先頭から「*」の個数の値に、1を足している。
つまり、この値は「2〜4」の間を指す。
あとでわかる話だが、「*」の個数に1を足した値を n とすると、
その見出しのタグは<Hn>にする設定になっている。
つまり、「*」なら<H2>タグ、「**」なら<H3>タグ、
「***」なら<H4>タグを使っている事になる。
|
さて、上の青い部分に着目する。
make_heading()関数だが、この処理の話をする前に、
見出しのデータの記述の話をします。
|
見出しの作成(Pukiwikiでの編集では) |
** おしらせ
|
だが、上の状態で保管した後で、もう一度、編集画面を呼び出すと
オマケがついてくる。
|
見出しのおまけ(赤い部分) |
** お知らせ [#wbf317c3]
|
赤い部分は、編集の際につけていない場合、データ保管時に
自動的に追加されるのだ。
もちろん、編集時に利用者が好きな名前をつける事も可能だ。
これは該当のページにリンクする際、そのページの先頭だけでなく、
見出しの部分へ飛ぶ事ができるようにするための処理なのだ。
つまり<A>タグで、nameの属性の指定するための処理というわけだ。
さて、make_heading()関数だが、この関数は、処理するテキストデータを
関数に入れると、返り値は、nameの属性の値になる。
上の例だと # と []のカッコを除いた 「 wbf317c3 」となる。
そして、この関数を動かす事で、送られた処理するデータは、
先頭の見出しのタグ「*」と、nameの属性を抜かれた物に変化している。
つまり表示したい部分だけ抽出された形になる。
実際に、make_heading()関数の中身を見てみる。
lib/html.phpのソースの中で定義された関数だ。
make_heading()関数
(lib/html.php) |
function make_heading(& $str, $strip = TRUE)
{
global $NotePattern;
// Cut fixed-heading anchors
$id = '';
$matches = array();
if (preg_match('/^(\*{0,3})(.*?)\[#([A-Za-z][\w-]+)\](.*?)$/m', $str, $matches)) {
$str = $matches[2] . $matches[4];
$id = & $matches[3];
} else {
$str = preg_replace('/^\*{0,3}/', '', $str);
}
// Cut footnotes and tags
if ($strip === TRUE)
$str = strip_htmltag(make_link(preg_replace($NotePattern, '', $str)));
return $id;
}
|
赤い部分だが、仮引数の部分に & が入っている。
これは、この関数内での変数 $str が処理された場合、その処理が
呼び出し元の変数にも受け継がれる事を意味する。
この変数 $str は処理したい行のデータなので、この関数で処理されたデータは
呼び出し元でも、処理された状態で使われる事になる。
青い部分だが、正規表現だ。
行の見出しのタグ「*」と、表示させたい部分と、nameの属性部分と、
その後ろの部分(表示させたい部分)を取り出す。
それぞれ matches[1],matches[2],matches[3],matches[4]に格納される。
ピンクの部分は、変数 $str の値を、表示させたい部分だけにする処理。
オレンジの部分は、$idの変数に、name属性の値を代入させる部分。
|
make_heading()関数で、返り値として、$id変数(nameの属性)と、
コンテンツデータから、表示させたいデータだけを抽出して
変数 $textに入れ直すのがわかった。
さて、make_heading()関数以降の処理をみていく事にする。
Bodyクラスの getAnchor()関数
(lib/convert_html.php) |
function getAnchor($text, $level)
{
global $top, $_symbol_anchor;
// Heading id (auto-generated)
$autoid = 'content_' . $this->id . '_' . $this->count;
$this->count++;
// Heading id (specified by users)
$id = make_heading($text, FALSE); // Cut fixed-anchor from $text
if ($id == '') {
// Not specified
$id = & $autoid;
$anchor = '';
} else {
$anchor = ' &aname(' . $id . ',super,full){' . $_symbol_anchor . '};';
}
$text = ' ' . $text;
// Add 'page contents' link to its heading
$this->contents_last = & $this->contents_last->add(new Contents_UList($text, $level, $id));
// Add heding
return array($text . $anchor, $this->count > 1 ? "\n" . $top : '', $autoid);
}
|
青い部分は、$anchorの変数に、&aname()のプラグインの記述を代入している。
&aname()のプラグインは、<A>タグの nameの属性を
ひっつけるためのものだ。
Pukiwikiには、見出しに<A>タグの nameの属性の印をつけて
他の場所から、その部分へ直接、飛べるような仕掛けがある。
その仕掛けを行う部分だ。
そして、この関数の呼び出し元へ渡す返り値を見てみる。
ピンクの部分だが、見出し上で、表示したい文字列と &aname() プラグインを
ひっつけた値を返している。
赤い部分だが、この $count は同じページ上で、何番目の見出しを表す。
この変数の値が「1」であれば、見出しの右上に「↑」を載せないため
ヌル文字を返し、2以上であれば、$top の変数を返す。
|
さて、getAnchor()関数の呼び出し元に戻る。
Headingクラスを抜粋
(lib/convert_html.php) |
// * Heading1
// ** Heading2
// *** Heading3
class Heading extends Element
{
var $level;
var $id;
var $msg_top;
function Heading(& $root, $text)
{
parent::Element();
$this->level = min(3, strspn($text, '*'));
list($text, $this->msg_top, $this->id) = $root->getAnchor($text, $this->level);
$this->insert(Factory_Inline($text));
$this->level++; // h2,h3,h4
}
(以下、省略)
|
ピンクの部分は、インライン型プラグインなどの処理が行われる。
$text は &aname() プラグインを含むので、ここでプラグインの処理が
行われるのだ。
|
ここまでソースを追っかけると、まずは矢印「↑」の消す方法がわかる。
Headingクラスで、処理したデータをHTMLの生成物として
吐き出す部分を見てみる。
Headingクラスを抜粋
(lib/convert_html.php) |
function toString()
{
return $this->msg_top . $this->wrap(parent::toString(),
'h' . $this->level, ' id="' . $this->id . '"');
}
|
$this->msg_topだが、これは矢印「↑」を表示させるための変数だ。
なので、$this->msg_top の部分を削除したら良い。
Headingクラスを抜粋 (変更後)
(lib/convert_html.php) |
function toString()
{
return $this->wrap(parent::toString(),
'h' . $this->level, ' id="' . $this->id . '"');
}
|
さて、ブラウザで確かめると
見事、消えた!!
だった (^^)V
次に十字架ならぬ「剣」(†)を消すのだが、プラグインの関数を見てみる。
&aname()プラグインの場合、 plugin/aname.inc.php のソースだ。
&aname()プラグインの処理の部分
(plugin/aname.inc.php) |
// &aname;
function plugin_aname_inline()
{
$convert = FALSE;
if (func_num_args() < 2)
return plugin_aname_usage($convert);
$args = func_get_args(); // ONE or more
$body = strip_htmltag(array_pop($args), FALSE); // Strip anchor tags only
array_push($args, $body);
return plugin_aname_tag($args, $convert);
}
|
どうやら赤い部分に何かありそうだ。
というわけで、てっとり早く見るため、plugin_aname_tag()関数の
返り値の部分を見てみる事にした。
plugin_aname_tag()関数の返り値の部分
(plugin/aname.inc.php) |
return '<a class="' . $class . '"' . $attr_id . $href . $title . '>' .
$body . '</a>';
|
さて、実際のHTMLソースを見てみる。
|
見出しの表示のための吐き出されるHTMLソース |
<h3 id="content_1_0">お知らせ <a class="anchor_super"
id="wbf317c3" href="http://***********/index.php?FrontPage#wbf317c3"
title="wbf317c3">†</a></h3>
|
(注意)
実際には、1行で書かれているのですが、読みやすくするため
意図的に改行をいれました。
|
特定のページへ飛ぶ機能を生かしたまま、剣だけは消したい。
そこで以下のように、plugin_aname_tag()関数の返り値の部分を
書き換えてみる。
plugin_aname_tag()関数の返り値の部分
(plugin/aname.inc.php) |
return '<a class="' . $class . '"' . $attr_id . $href . $title . '></a>';
|
<A>タグで、はさむ物を消したのだ。
これによって、剣は消えると考えた。
|
さて、ブラウザで確かめると
見事、消えた!!
だった (^^)V
これで無事、剣(†)と矢印「↑」が消えたのだった。
簡単そうに解説していますが、結構、読むのに時間がかかりました (^^;;
ソースを読むのは結構ハードだと思った。
まぁ、この辺でソース読みも終わろうかと思っていた。
事務員だから読めなくても良いのだ!!
という逃げ道だってあるのだ ← 私の特権 (^^)
だが、引続き、ソースを読まねばならない状態だった。
それは画像の表示に関しての謎解きがあったからだ。
まだ、Bodyクラスや Headingクラスの解読を行う前だった。
画像データを表示させるのには、ref()プラグインを使うのだが、
&ref()を使ったり、#ref()プラグインを使う場合もある。
ref()の頭についている物は何か。これはプラグインの型を表す。
Pukiwikiには2つの型のプラグインがある。
|
プラグインには、2つの型がある |
| #(プラグイン名) |
ブロック型プラグインという。行頭に使う。
行頭でこのプラグインを指定しないと、
プラグインとして認識してくれない。
|
| &(プラグイン名) |
インライン型プラグインという。
文章の中なら、どこでも指定できるので便利
|
さて、2つの型のプラグインがあるのを知っていたのだが、
実は・・・
違いなんて知らずに、
インライン型プラグインを使っていました (^^;;
2つ型のプラグインは、全く同じ使い方だと思い込んでいた。
そして、「#」よりも「&」の方がタグっぽいという理由だけで、
&プラグイン(インライン型)を使っていたのだった。
だが、この2つの違いを知る必要に迫られる。
それは画像の張り付けの時だった。
単に画像を張り付けて表示させる際は、&ref(ファイル名)で
指定していた。それで全く問題なかった。
しかし、以下のように画像の横に文字を表示させたくなった。
つまり画像の周囲に文字を回り込ませるという技だ。
|
画像の右横に文字を回り込ませたい |
 |
この時、ref()のパラメータに「around」を入れたら良い事を知ったので
いつもの如く、 &ref(ファイル名,around); とやってみたが・・・
| 編集の内容 |
&ref(picpic.gif,nolink,around);
画像の周囲に文字を表示 &br;
うまくいくかなぁ &br;
|
| 出力結果 |
 |
全然、うまくいかへん (TT)
なぜ、ダメなのかが見当すらつかない。
そこで、googleなどで調べていくと、画像を回り込ませるには
「&」のインライン型プラグインではなく、「#」のブロック型を
使わないといけない事が書いてあった。
そして、回り込ませる文章の後に、 #clear を入れる必要があるという。
早速、#ref(ファイル名,around); とやってみた。
| 編集の内容 |
#ref(picpic.gif,nolink,around);
画像の周囲に文字を表示 &br;
うまくいくかなぁ &br;
#clear
|
| 出力結果 |
 |
見事、成功!
さて、ブロック型プラグインで画像の表示をやっている間に、ある事に気づく。
ブロック型のプラグインは行頭で使わないと反応してくれない!
さて、画像を表示させるプラグイン。
ブロック型とインライン型の違いは何なのだろうか。
吐き出されるHTMLソースで比較してみた。
| ブロック型のref()プラグイン |
|
&ref(picpic.gif,nolink,around);
|
|
吐き出されるHTMLソース |
<div class="img_margin" style="text-align:left">
<img src="http://**********/kanri/index.php?plugin=ref&
page=FrontPage&src=pic.gif" alt="pic.gif" title="pic.gif"
width="144" height="110" /></div>
|
| インライン型のref()プラグイン |
|
#ref(picpic.gif,nolink,around);
|
|
吐き出されるHTMLソース |
<p><img src="http://**********/kanri/index.php?
plugin=ref&page=FrontPage&src=pic.gif" alt="pic.gif"
title="pic.gif" width="144" height="110" /> </p>
|
吐き出されたソース。ちょっと見にくいですが、どんな感じで
ホームページ上には画像が表示されるのか図にしてみた。
|
図にしてみると・・・ |
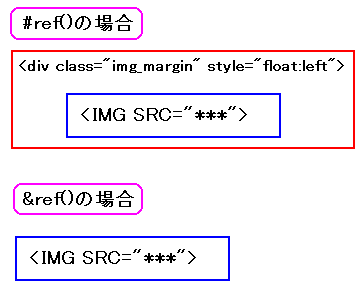 |
ブロック型プラグインの場合、画像の<img>タグ全体を
<div>タグで覆っている事がわかる。
だが、インライン型プラグインの場合は、特に何もない。
強いて書けば、<p>タグで囲んでいるだけだ。
なので、ブロック型の場合、<div>タグのお陰で文字や文章の
回り込みができるが、インライン型だと<img>タグの前後を
<p>タグで囲んでいるため、文字や文章が回り込む余地がないのだ。
あとは、初期設定では、ブロック型だと<div>タグの
指定場所が関係するため、インライン型とでは画像の置き場所が
微妙に違ってくる。
|
画像の置き場所が微妙にズレている |
 |
この2つの違い。
何が何でも調べておかねばと思った。
そこでソース読みをして解明していこうと考えた。
ブロック型のプラグインの処理だが、プログラムの解読は
そんなに難しくない。
Bodyクラスの解読を行っていた時に、以下の部分がある。
Bodyクラスのブロック型プラグインに処理部分
(lib/convert_html.php) |
// Body
class Body extends Element
{
var $id;
var $count = 0;
var $contents;
var $contents_last;
var $classes = array(
'-' => 'UList',
'+' => 'OList',
'>' => 'BQuote',
'<' => 'BQuote');
var $factories = array(
':' => 'DList',
'|' => 'Table',
',' => 'YTable',
'#' => 'Div');
(途中省略)
// Other Character
if (isset($this->factories[$head])) {
$factoryname = 'Factory_' . $this->factories[$head];
$this->last = & $this->last->add($factoryname($this, $line));
continue;
}
(途中省略)
|
上の処理は、コンテンツの行の先頭が「#」なら、ピンクの部分が動く。
ここでブロック型プラグインが行の先頭になければならない理由がわかった!
つまり、先頭に「#」があるかないかで、ブロック型プラグインかどうかを
判断させているためなのだ。
この時、上のピンクの部分は以下のように読みかえられる。
$this->last = & $this->last->add(Factory_Div($this, $line));
そこで、まずは、Factory_Div()関数を見てみる。
Factory_Div()関数
(lib/convert_html.php) |
function & Factory_Div(& $root, $text)
{
$matches = array();
// Seems block plugin?
if (PKWKEXP_DISABLE_MULTILINE_PLUGIN_HACK) {
// Usual code
if (preg_match('/^\#([^\(]+)(?:\((.*)\))?/', $text, $matches) &&
exist_plugin_convert($matches[1])) {
return new Div($matches);
}
} else {
// Hack code
if(preg_match('/^#([^\(\{]+)(?:\(([^\r]*)\))?(\{*)/', $text, $matches) &&
exist_plugin_convert($matches[1])) {
$len = strlen($matches[3]);
$body = array();
if ($len == 0) {
return new Div($matches); // Seems legacy block plugin
} else if (preg_match('/\{{' . $len . '}\s*\r(.*)\r\}{' . $len . '}/', $text, $body)) {
$matches[2] .= "\r" . $body[1] . "\r";
return new Div($matches); // Seems multiline-enabled block plugin
}
}
}
return new Paragraph($text);
}
|
赤い部分は初期設定では「1」の定数だ。
この定義は pukiwiki.ini.php のソースの中にある。
青い部分は正規表現で、プラグインの種類とパラメータを取り出す。
#ref(test.gif,nolink); なら「ref」の文字をmatche[1]に代入し、
matches[2]には「nolink」が代入されるように、matches[2]以降は
パラメーターの値が入る。
ピンクの部分は、その種類のプラグインが実際に存在するかどうかの確認だ。
青い部分の正規表現で抽出可能で、かつピンクの部分が満たされれば
オレンジの部分が働く。
オレンジの部分は Divクラスの初期化の際、青い部分の正規表現で
取得したプラグインの種類やパラメータが入ったmeches[]配列が送られる。
Divクラスでの初期化を行った時にできたオブジェクトが、
そのまま、この関数の返り値になる。
|
というわけで、Divクラスを見てみる事にした。
Divクラスの中
(lib/convert_html.php) |
// Block plugin: #something (started with '#')
class Div extends Element
{
var $name;
var $param;
function Div($out)
{
parent::Element();
list(, $this->name, $this->param) = array_pad($out, 3, '');
}
function canContain(& $obj)
{
return FALSE;
}
function toString()
{
// Call #plugin
return do_plugin_convert($this->name, $this->param);
}
}
|
この青い部分だが、配列の要素を3つにする仕掛けになっている。
まぁ、このクラスが受け取った $outの配列は、要素数が3つなので、
どうもこの部分は意味がわかりにくいが、まぁ、万が一、
配列の要素が4つや5つだったとしても、最終的な確認という意味で
3つにする部分という解釈なのかもしれない。
赤い部分だが、配列を個々の変数に割り振る部分だ。
配列 $out だが、$out[0]は、プラグイン全体なので、無視。
$out[1]はプラグイン名が入っている。この値を $name に代入。
$out[2]は、パラメーターが入っている。この値を $paramに代入。
|
さて、実際に画像を出力させる時だが、DivクラスのtoString()関数が動く。
Divクラスの中
(lib/convert_html.php) |
// Block plugin: #something (started with '#')
class Div extends Element
{
var $name;
var $param;
function Div($out)
{
parent::Element();
list(, $this->name, $this->param) = array_pad($out, 3, '');
}
function canContain(& $obj)
{
return FALSE;
}
function toString()
{
// Call #plugin
return do_plugin_convert($this->name, $this->param);
}
}
|
まさに青い部分だ。
$this->name と、$this->paramは Divクラスの初期化の際に
それぞれプラグイン名と、パラメータの値として保管されている。
そして、do_plugin_convert()関数を呼び出す。
|
ブロック型プラグインは比較的、解読しやすい。
さて、問題はインライン型のプラグインなのだ。
コンテンツの文中の中に紛れ込んでいるため、それをいかに抽出させるのか
その方法は、どうやって行っているのか見ていかねばならない。
Bodyクラスで、行単位に処理を行うためのparse()関数を見てみる。
何もプラグインや、見出しなど行頭に必要な仕掛けがない場合は、
以下のBodyクラスの部分で処理されている。
Bodyクラスの中の普通の行を処理する部分
(lib/convert_html.php) |
// Default
$this->last = & $this->last->add(Factory_Inline($line));
|
|
Factory_Inline()関数を呼び出している。
|
そこで、Factory_Inline()関数を見てみる。
Factory_Inline()関数
(lib/convert_html.php) |
function & Factory_Inline($text)
{
if (substr($text, 0, 1) == '~') {
// 行頭 '~' 。パラグラフ開始
return new Paragraph(' ' . substr($text, 1));
} else {
return new Inline($text);
}
}
|
青い部分は、処理する行の行頭が「~」かどうかを調べる。
もし、「~」の場合、プラグインなども処理されずに、
入力された通りの内容が表示される。
それ以外の場合は、ピンクの部分。Inlineクラスが初期化され、
そのオブジェクトを、この関数の返り値にしている。
|
それで、Inlineクラスの中身を見てみる。
Inlineクラスの中身 (初期化の部分)
(lib/convert_html.php) |
// インライン要素
class Inline extends Element
{
function Inline($text)
{
parent::Element();
$this->elements[] = trim((substr($text, 0, 1) == "\n") ?
$text : make_link($text));
}
|
処理する行の行頭が「\n」という改行文字なら、青い部分にありますように
そのままにしておき、その値を $this->elements[] の配列の中に入ります。
そうでない場合はピンクの部分の make_link()関数が動きます。
その返り値が $this->elements[] の配列の中に入ります。
|
この make_link()関数に秘密があります。
この関数を解読しようと思ったが、ドツボにハマりそうなので
パンドラの箱を開けるのか・・・ (--;;
とブルーな気分になった。
だが、ここで止めてしまえば元も子もないので、渋々、解読をする事にした。
make_link()関数は、lib/make_link.php のソース内で定義されている。
make_link()関数
(lib/make_link.php) |
function make_link($string, $page = '')
{
global $vars;
static $converter;
if (! isset($converter)) $converter = new InlineConverter();
$clone = $converter->get_clone($converter);
return $clone->convert($string, ($page != '') ? $page : $vars['page']);
}
|
赤い部分は $converter の中身がセットされているかどうかのチェックで
セットされていない場合は、青い部分が動く。
青い部分は、変数 $converterをInlineConverterクラスのオブジェクトにして
そのオブジェクトを初期化する。
|
さて、InlineConverterクラスの初期化を見てみる。
InlineConverterクラスの初期化部分
(lib/make_link.php) |
class InlineConverter
{
var $converters; // as array()
var $pattern;
var $pos;
var $result;
(途中、省略)
function InlineConverter($converters = NULL, $excludes = NULL)
{
if ($converters === NULL) {
$converters = array(
'plugin', // Inline plugins
'note', // Footnotes
'url', // URLs
'url_interwiki', // URLs (interwiki definition)
'mailto', // mailto: URL schemes
'interwikiname', // InterWikiNames
'autolink', // AutoLinks
'bracketname', // BracketNames
'wikiname', // WikiNames
'autolink_a', // AutoLinks(alphabet)
);
}
if ($excludes !== NULL)
$converters = array_diff($converters, $excludes);
$this->converters = $patterns = array();
$start = 1;
foreach ($converters as $name) {
$classname = 'Link_' . $name;
$converter = new $classname($start);
$pattern = $converter->get_pattern();
if ($pattern === FALSE) continue;
$patterns[] = '(' . "\n" . $pattern . "\n" . ')';
$this->converters[$start] = $converter;
$start += $converter->get_count();
++$start;
}
$this->pattern = join('|', $patterns);
}
|
このクラスの初期化で、赤い部分はプラグインやURLなどの抽出を行うための
パターンを作成するための準備だ。各パターン別に配列に入れる。
青い部分は、各抽出パターンごとに該当する正規表現を取り出し
配列 $patterns[] に、その正規表現を入れていく。
ピンクの部分は、各抽出パターンに正規表現を「|」で連結した文字列にして
それをInlineConverterクラスの中の $pattern 変数の値にする。
|
さて、上で「各抽出パターンの正規表現」と書きましたが、
一体、どういう事なのか。
もう少し、上の青い部分を詳しくみていきます。
InlineConverterクラスの初期化部分
(lib/make_link.php) |
foreach ($converters as $name) {
$classname = 'Link_' . $name;
$converter = new $classname($start);
$pattern = $converter->get_pattern();
if ($pattern === FALSE) continue;
$patterns[] = '(' . "\n" . $pattern . "\n" . ')';
$this->converters[$start] = $converter;
$start += $converter->get_count();
++$start;
}
|
赤い部分は、各抽出パターンに関する情報が入ったクラス名を作成。
青い部分は、各抽出パターンに関する情報が入ったオブジェクトを作る。
ピンクの部分は、各抽出パターンの正規表現を、変数 $patternの値にしている。
|
さて、青い部分がポイントだ。
もし、抽出パターンがプラグインの場合、青い部分は次のように
読みかえる事ができる。
$converter = new Link_plugin($start);
そして、プラグインの場合、ピンクの部分は Link_pluginクラス内部の
get_pattern()の関数を呼び出すのだ。
早速、Link_plugin()クラスのget_pattern()を見てみる事にした。
Link_plugin()クラスのget_pattern()関数
(lib/make_link.php) |
function get_pattern()
{
$this->pattern = <<<EOD
&
( # (1) plain
(\w+) # (2) plugin name
(?:
\(
((?:(?!\)[;{]).)*) # (3) parameter
\)
)?
)
EOD;
return <<<EOD
{$this->pattern}
(?:
\{
((?:(?R)|(?!};).)*) # (4) body
\}
)?
;
EOD;
}
|
上のソースを見ると、ヒアドキュメントで書かれている。
青い部分だが、ご丁寧に正規表現で取り出す項目が説明されている。
赤い部分は、表示させたいテキスト部分を抜き取る部分だ。
画像関係のプラグインの場合だと、 &ref(pic.gif,nolink); のように
テキスト部分は不要なため、赤い部分がある理由が見えてこないが、
&color(色){文章} のように、文字列に色をつけるプラグインや
&size(大きさ){文章}のように、文字の大きさを変更する
プラグインの場合だと、body、即ち、文章の部分が必要になる。
その文章を抜き取る部分を意味するのだ。
|
個々の抽出パターンに該当する正規表現の部分を取り出したあと、
以下の処理が行われる。
InlineConverterクラスの初期化部分
(lib/make_link.php) |
foreach ($converters as $name) {
$classname = 'Link_' . $name;
$converter = new $classname($start);
$pattern = $converter->get_pattern();
if ($pattern === FALSE) continue;
$patterns[] = '(' . "\n" . $pattern . "\n" . ')';
$this->converters[$start] = $converter;
$start += $converter->get_count();
++$start;
}
|
赤い部分は、個々の抽出パターンに該当する正規表現を
配列 $patterns[] の中にいれて行く。
青い部分だが、配列 $converters[] に、各抽出パターンのデータが入った
オブジェクトを入れていくのだ。
|
上の青い部分で、配列 $converters[] のキーは数字なのだが、
1から順番に並んでいるわけではないのだ。
ピンクの部分を注目していただいたら、わかりますように、
$converter->get_count();の数字分、間隔が空いているのだ。
図にすると、こんな感じになる。
|
図にすると、配列 $converters[]はこうなる |
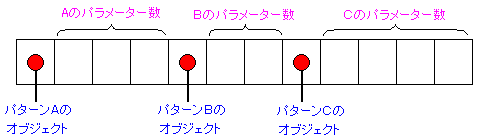 |
なぜ、こんな間隔を空けるのは、もう少し後で説明します。
そして最後にInlineConverterクラスの初期化で
以下の事が行われる。
InlineConverterクラスの初期化部分
(lib/make_link.php) |
class InlineConverter
{
var $converters; // as array()
var $pattern;
var $pos;
var $result;
(途中、省略)
function InlineConverter($converters = NULL, $excludes = NULL)
{
(途中、省略)
$this->pattern = join('|', $patterns);
}
|
ピンクの部分は、各抽出パターンに正規表現を「|」で連結した文字列にして
それをInlineConverterクラスの中の $pattern 変数の値にする。
「|」は、いくつかの正規表現のパターンのうち、いずれかが
マッチするための物だ。条件文に出てくる「or」に近い。
|
これでInlineConverterクラスの初期化の話が終わりです。
さて、make_link()関数の話に戻します。
make_link()関数
(lib/make_link.php) |
function make_link($string, $page = '')
{
global $vars;
static $converter;
if (! isset($converter)) $converter = new InlineConverter();
$clone = $converter->get_clone($converter);
return $clone->convert($string, ($page != '') ? $page : $vars['page']);
}
|
この赤い部分だが、変数 $clone に、自分自身のオブジェクト($converter)を
指すための部分だ。
青い部分は、いよいよクライマックスの、プラグイン等を抽出して
変換を行う部分だ。
|
さて、上の青い部分を見ていく事にした。
InlineConverterクラスのconvert()関数
(lib/make_link.php) |
function convert($string, $page)
{
$this->page = $page;
$this->result = array();
$string = preg_replace_callback('/' . $this->pattern . '/x',
array(& $this, 'replace'), $string);
$arr = explode("\x08", make_line_rules(htmlspecialchars($string)));
$retval = '';
while (! empty($arr)) {
$retval .= array_shift($arr) . array_shift($this->result);
}
return $retval;
}
|
この赤い部分だが、$string の変数に入った文字列、つまり処理する行の中から
プラグインなどのパターンを抽出して変換を行う部分なのだ。
さて、preg_replace_callback()関数なのだが、使い方は
preg_replace_callback(正規表現, コールバック関数, 文字列)となる。
コールバック関数は、ユーザーが定義した関数という意味だ。
ただし、なぜユーザー定義関数と言わずに、コールバック関数と呼ぶのかは
調べてみましたが、わかりませんでした。
preg_replace_callback()関数だが、処理前の文字列(ここでは $string)を
正規表現でパターンを抽出して、抽出した物を、コールバック関数へ送り、
その返り値を preg_replace_callback() の返り値にしている。
さて、コールバック関数の部分だが、 array(& $this, 'replace')と
配列変数の記述をしている。配列と関連がありそうなのだが、
実は、同じクラス内で定義した関数を呼び出すためのテクニックにすぎない。
これに何か意味があるのだろうかと、色々、調べたのだが、
結局、調べた時間(1時間くらい)が無駄になってしまった (--;;
|
上の赤い部分を見ていくため、InlineConverterクラスのreplace()関数を
見てみる事にした。
InlineConverterクラスのreplace()関数
(lib/make_link.php) |
function replace($arr)
{
$obj = $this->get_converter($arr);
$this->result[] = ($obj !== NULL && $obj->set($arr, $this->page) !== FALSE) ?
$obj->toString() : make_line_rules(htmlspecialchars($arr[0]));
return "\x08"; // Add a mark into latest processed part
}
|
赤い部分は get_converter()を呼び出しています。
この関数は、
|
get_converter()を見てみる。うーん、関数が飛びまくるなぁ・・・。
InlineConverterクラスのget_converter()関数
(lib/make_link.php) |
function & get_converter(& $arr)
{
foreach (array_keys($this->converters) as $start) {
if ($arr[$start] == $arr[0])
return $this->converters[$start];
}
return NULL;
}
|
赤い部分を見てみる。
配列 $converters[] はプラグインやURLなどの抽出パターンが入った
オブジェクトを指すための配列だ。
さきほど、説明した通り、キーの数字は、パラメーター数分の間隔を空けている。
そして、値の入った配列のキーの値だけを取り出し、繰り返し処理を行う。
$startはキーの値が入る。
青い部分だが、arr[0]とarr[$start]の一致だが、これはピンクの部分にある
プラグインやURLのうち、該当する処理を行うオブジェクトを取り出すための
条件式になるのだが、どうも理解できない。
|
青い部分が、いまいち理解できないので、次の実験を行う。
ソースの部分を一部書き換えるのだ!
InlineConverterクラスのget_converter()関数を書き換え
(lib/make_link.php) |
function & get_converter(& $arr)
{
foreach (array_keys($this->converters) as $start) {
if ($arr[$start] == $arr[0])
{
print_r($arr);
return $this->converters[$start];
}
}
return NULL;
}
|
$arr配列は、処理する行の中から、プラグインやURLなどの正規表現の処理で
取り出された部分が入っている。
赤い部分は、その配列の中身を見てみる部分だ。
|
さて、ブラウザを見てみると次の結果が出た。
|
動作結果 |
|
[[URL]]のリンク処理の場合 |
Array ( [0] => [[あああ>http://www.kek.jp]] [1] => [2] => [3] =>
[4] => [5] => [6] => [7] => [8] => [[あああ>http://www.kek.jp]]
[9] => [[あああ> [10] => あああ [11] => http://www.kek.jp )
|
|
プラグインの場合( ref プラグインを使った) |
Array ( [0] => &ref(picpic.gif,nolink); [1] => &ref(picpic.gif,nolink);
[2] => ref(picpic.gif,nolink) [3] => ref [4] => picpic.gif,nolink )
|
[[ URL ]] の場合は、0番目と8番目の中身が一致する。
プラグインの場合は、0番目と1番目の中身が一致する。
実は、この0番目以外の、もう一つの同じ部分に秘密がある
これは、さきほど説明しましたプラグインやURLなどの処理方法が入った
オブジェクトを指す配列 $converters だが、このキーの部分と
上の $arrの0番目のキーの中身と一致するキーの番号は同じ数字なのだ。
図にすると以下のようになる。
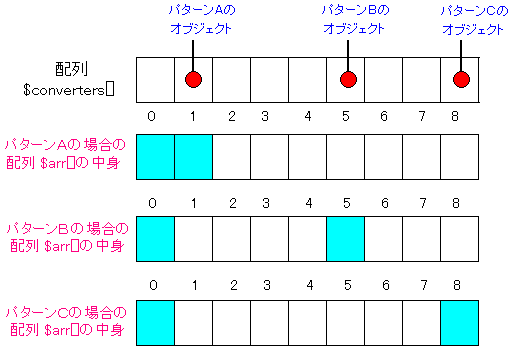
という事で、 $arr[0] と一致するキーを探すのは重要な上、
$arr配列を生成する時の正規表現には、そういう秘密があったのだ。
|
うーん、正規表現の中身が理解できなくなっても、実験結果で
何をやろうとしているのかが、だいたいわかるので、助かる。
さて、該当のオブジェクトがわかった所で、そのオブジェクトを返り値として
受け取る元の部分を見てみる。
InlineConverterクラスのreplace()関数
(lib/make_link.php) |
function replace($arr)
{
$obj = $this->get_converter($arr);
$this->result[] = ($obj !== NULL && $obj->set($arr, $this->page) !== FALSE) ?
$obj->toString() : make_line_rules(htmlspecialchars($arr[0]));
return "\x08"; // Add a mark into latest processed part
}
|
赤い部分は、該当のオブジェクトの取得を意味する。
そして、青い部分を見てみる。
これは各パターンごとに処理したデータの入ったオブジェクト、
すなわち、赤い部分で取得したオブジェクトのtoString() 関数を指す。
これはデータの出力時に使われる。
しかも、プラグインの場合のtoString()関数には、2重プラグインの
対応もできるようにしている。
例えば、 &color(red){ &size(24){ テストだよ! }; }; の場合だ。
「テストだよ!」の大きさを24にして、その後、文字を赤くする。
これは一番外側のプラグインを処理する時、中のプラグインは
まだ処理されていない。 toString()関数の中では、一つ中にある
プラグインを抽出して処理するため、もう一度、make_link()関数を
呼び出しているのだ! 再帰関数のような感じだ。
図にすると次のようになる。
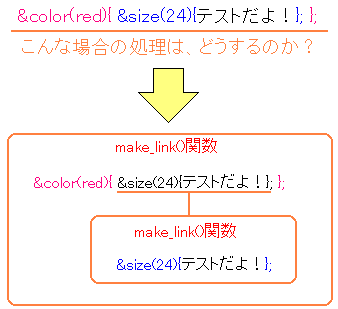
それ以外の場合は、make_line_rules()関数を使って、
文字列の処理を行う。一体、この関数は何なのか。
この時点では調べませんでした。というよりも、頭の中が混乱していて
とても追っかける気が起こりませんでした。
先に種明かしをしますと、これはユーザー定義ルールを拾い出し
それを処理する関数なのだ。
Pukiwikiでのデフォルト設定としての、ユーザー定義ルールがある。
それは COLOR(red){赤いぜ!} のように、プラグインとは違った使い方でも、
同じような働きをするルールだ。
この、make_line_rules()関数について詳しくは後述しています。
|
そして、replace()関数を呼び出した InlineConverterクラスの
convert()関数を見てみる。
InlineConverterクラスのconvert()関数
(lib/make_link.php) |
function convert($string, $page)
{
$this->page = $page;
$this->result = array();
$string = preg_replace_callback('/' . $this->pattern . '/x',
array(& $this, 'replace'), $string);
$arr = explode("\x08", make_line_rules(htmlspecialchars($string)));
$retval = '';
while (! empty($arr)) {
$retval .= array_shift($arr) . array_shift($this->result);
}
return $retval;
}
|
赤い部分で、いくつかの正規表現にマッチさせた物をreplace関数に送る。
その結果が「 \x08 」という物がreplace関数から返され、
正規表現で一致した部分は「 \x08 」に置き換わる。
「 \x08 」は単に目印のために使っているだけで、特に、この文字には
意味はない。
青い部分は、まずは $string 変数をhtmlspecialchars()関数で処理する。
ちなみに、htmlspecialchars()関数は、「 > 」や「 " 」などを
「 > 」や「 " 」に変換する関数だ。
タグなどを構成する文字に間違えられそうな物を
ブラウザで問題なく表示できるような文字に変換するための関数だ。
掲示板などで入力された文字列で、HTMLのタグが含まれている場合に
タグの無効化に使われる定番の関数だ。
さて、make_line_rules()関数は、さきほども紹介しました関数で
ユーザー定義ルールを処理する関数だ。詳しくは後述しています。
そして、さきほど赤い部分で、パターンにマッチした正規表現を抜き取り
「 \x08 」の文字を入れたが、この文字を区切りとして、
$stringの文字列は、配列 $arr[] に格納されていく。
|
言葉だけだとイメージしにくいので、上の事を図にまとめてみると
次の通りになる。
InlineConverterクラスのconvert()関数
(lib/make_link.php) |
function convert($string, $page)
{
$this->page = $page;
$this->result = array();
$string = preg_replace_callback('/' . $this->pattern . '/x',
array(& $this, 'replace'), $string);
$arr = explode("\x08", make_line_rules(htmlspecialchars($string)));
$retval = '';
while (! empty($arr)) {
$retval .= array_shift($arr) . array_shift($this->result);
}
return $retval;
}
|
赤いソースの部分の役目を図にしてみる。
「 画像は &ref(pic.gif);でリンクは[[ここ>http://example.com]]だよ 」
の文章を例にして、処理の内容を見ていく。
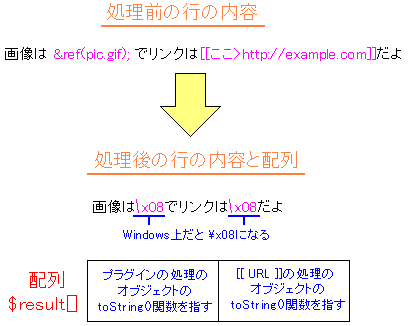
赤いソースの部分で、プラグインなどに関する部分とを分離して
文章の部分に、プラグインがあった場所に目印を付けて $string に返す。
そして、抽出されたプラグインやリンクなどは、個々の処理に該当する
オブジェクトに代入さて、そのオブジェクトを指す部分を保管するのに
$result[]配列が使われる。
青いソースの部分は、加工した文章を配列にする部分だ。
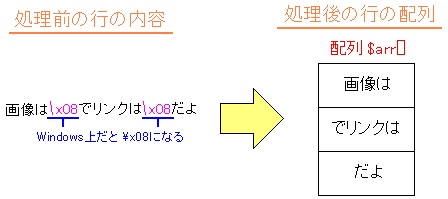
|
さて、分離された後、どうなるのか。
プラグインなどの部分が処理されて、HTML言語の文字列として戻されます。
その部分の処理は以下の部分です。
InlineConverterクラスのconvert()関数
(lib/make_link.php) |
function convert($string, $page)
{
$this->page = $page;
$this->result = array();
$string = preg_replace_callback('/' . $this->pattern . '/x',
array(& $this, 'replace'), $string);
$arr = explode("\x08", make_line_rules(htmlspecialchars($string)));
$retval = '';
while (! empty($arr)) {
$retval .= array_shift($arr) . array_shift($this->result);
}
return $retval;
}
|
ピンクのソースの部分が、一度、切り離したプラグインやリンクの部分を
HTMLのソースに加工して元に戻す部分だ。
図にすると以下のようになる。
|
このテクニックを解読できた瞬間
Pukiwikiは奥が深い!!
と思った。
Pukiwikiを一般ユーザーとして使う分なら、Pukiwiki独自のタグを
ある程度覚えれば良いのだが、このプログラムを読むとなれば大変だ。
ましてや、Pukiwikiを作った人に対しては
凄いの一言に尽きる!
まぁ、私がPHPを使い慣れていないので、大袈裟な表現になるのは
否定できないが、ただ、作った人には敬意を払うのは当然だ。
ところで、ここでも make_line_rules()関数が出てきた。
ユーザー定義ルールを処理する関数と説明してきましたが、
これは一体何なのか。中身を見てみる事にした。
make_line_rules()関数
(lib/html.php) |
// User-defined rules (convert without replacing source)
function make_line_rules($str)
{
global $line_rules;
static $pattern, $replace;
if (! isset($pattern)) {
$pattern = array_map(create_function('$a',
'return \'/\' . $a . \'/\';'), array_keys($line_rules));
$replace = array_values($line_rules);
unset($line_rules);
}
return preg_replace($pattern, $replace, $str);
}
|
ここでグローバル変数の $line_rules配列が何なのか気になった。
このグローバル変数がポイントになる。
|
さて、グローバル変数 $line_rules配列は、どんな値が入っているのか、
Pukiwikiのソースを探したら、default.ini.php の中にあった。
グローバル変数 $line_rules配列について
(default.ini.php) |
/////////////////////////////////////////////////
// ユーザ定義ルール
//
// 正規表現で記述してください。?(){}-*./+\$^|など
// は \? のようにクォートしてください。
// 前後に必ず / を含めてください。行頭指定は ^ を頭に。
// 行末指定は $ を後ろに。
//
/////////////////////////////////////////////////
// ユーザ定義ルール(コンバート時に置換)
$line_rules = array(
'COLOR\(([^\(\)]*)\){([^}]*)}' => '<span style="color:$1">$2</span>',
'SIZE\(([^\(\)]*)\){([^}]*)}' => '<span style="font-size:$1px">$2</span>',
'COLOR\(([^\(\)]*)\):((?:(?!COLOR\([^\)]+\)\:).)*)' => '<span style="color:$1">$2</span>',
'SIZE\(([^\(\)]*)\):((?:(?!SIZE\([^\)]+\)\:).)*)' => '<span class="size$1">$2</span>',
'%%%(?!%)((?:(?!%%%).)*)%%%' => '<ins>$1</ins>',
'%%(?!%)((?:(?!%%).)*)%%' => '<del>$1</del>',
"'''(?!')((?:(?!''').)*)'''" => '<em>$1</em>',
"''(?!')((?:(?!'').)*)''" => '<strong>$1</strong>',
);
|
これを見て、なるほどと思った。
ここの部分で、ユーザーが独自に簡単な正規表現のルールを作って
独自の関数っぽいものを作る事ができる。
まぁ、これは正規表現を使った置き換えなので、関数とは言えないので
「関数っぽい物」という表現にしましたが。
文字の強調で、強調した文字列を「''」で囲んで '' 強調!! ''とするのだが、
この時、初めて、ユーザー定義ルールだったのを知った。
|
グローバル変数 $line_rules配列の中身がわかった所で、
make_line_rules()関数の中身をみていく。
make_line_rules()関数
(lib/html.php) |
// User-defined rules (convert without replacing source)
function make_line_rules($str)
{
global $line_rules;
static $pattern, $replace;
if (! isset($pattern)) {
$pattern = array_map(create_function('$a',
'return \'/\' . $a . \'/\';'), array_keys($line_rules));
$replace = array_values($line_rules);
unset($line_rules);
}
return preg_replace($pattern, $replace, $str);
}
|
赤い部分と青い部分を見てみるのだが、その前に、array_map()関数の
意味がわからないと、この部分がわからなくなる。
arrary_map()関数とは、2つ以上の引数を持つ関数なのだが、
ここでは2つとしておく。
この関数は、 arrary_map(コールバック関数,配列) という形で使う。
この関数は、引数の配列の中身を1つづつ、コールバック関数に送って処理し、
処理した生成物を、別の配列に1つづつ入れていくのだ。
青い部分だが、$line_rules 配列のキーを取り出し、コールバック関数に送る。
赤い部分のコールバック関数だが、送られてきた物を、ここでは
$a という変数に格納し、'/.$a./'
という感じで
両端を「 '」と「/」で囲む処理を行う。
その結果を $pattern の配列に送り込むのだ。
すなわち、正規表現のパターンとして使える形に加工する部分だ。
そして、茶色の部分だが、これは$line_rules 配列を、array_values()関数で
キーを「0」、「1」、「2」に置き換える役目を果たす。
これで変換するための準備は完了だ。
あとは return 部分で、正規表現でパターンを抽出して、置き換え作業を行い
置き換えた物を返り値にしているのだ。
|
Pukiwikiで、行の先頭が「#」のプラグインや、見出しの等の処理よりも、
文字列の中からプラグインやリンクなどを抽出して処理する方が
巧妙な手法を使っている事がわかった。
だが、Pukiwikiで、まだ疑問が残る部分がある。
コンテンツデータを読み込んで表示させる部分は説明しましたが、
編集画面を呼び出す場合は、どうなるのだろうか。
その部分の仕掛けがどうなっているのかは、まだ見ていない。なので
ソースを見てみんと、アカンやろ
と思った。
そこでソースを眺める事にした。
lib/pukiwiki.phpの中に仕掛けがある事がわかった。
ソースを見る前に、編集画面を呼び出すには、クエリーの中に
「 cmd=edit&apm;page=ページ名 」が含まれる。
この事を頭に入れた上で、ソースを見ていく事にします。
編集画面などを呼び出す仕掛け
(lib/pukiwiki.php) |
/////////////////////////////////////////////////
// Main
$retvars = array();
$is_cmd = FALSE;
if (isset($vars['cmd'])) {
$is_cmd = TRUE;
$plugin = & $vars['cmd'];
} else if (isset($vars['plugin'])) {
$plugin = & $vars['plugin'];
} else {
$plugin = '';
}
if ($plugin != '') {
if (exist_plugin_action($plugin)) {
// Found and exec
$retvars = do_plugin_action($plugin);
if ($retvars === FALSE) exit; // Done
if ($is_cmd) {
$base = isset($vars['page']) ? $vars['page'] : '';
} else {
$base = isset($vars['refer']) ? $vars['refer'] : '';
}
} else {
// Not found
$msg = 'plugin=' . htmlspecialchars($plugin) .
' is not implemented.';
$retvars = array('msg'=>$msg,'body'=>$msg);
$base = & $defaultpage;
}
}
|
赤い部分は、$var['cmd']の値があるかどうかのチェックだ。
編集画面を呼び出す時、クエリーでcmdの値を送っているので、
この部分は必然的に TRUE になり、条件式が満たされる。
青い部分は $plugin 変数に、cmdの値を代入している。
編集画面の場合、cmd値は「edit」 なのだ。
ピンクの部分だが、 $pluginの値は空ではないので、TRUE になり
条件式を満たす。
|
さて、編集画面を呼び出す場合、ピンクの部分で TRUEを満たすので
TRUEの場合の処理を見ていく事にします。
編集画面などを呼び出す仕掛け (一部省略)
(lib/pukiwiki.php) |
/////////////////////////////////////////////////
// Main()
$retvars = array();
(途中省略)
if ($plugin != '') {
if (exist_plugin_action($plugin)) {
// Found and exec
$retvars = do_plugin_action($plugin);
if ($retvars === FALSE) exit; // Done
if ($is_cmd) {
$base = isset($vars['page']) ? $vars['page'] : '';
} else {
$base = isset($vars['refer']) ? $vars['refer'] : '';
}
} else {
// Not found
$msg = 'plugin=' . htmlspecialchars($plugin) .
' is not implemented.';
$retvars = array('msg'=>$msg,'body'=>$msg);
$base = & $defaultpage;
}
}
|
ピンクの条件式を満たすのは説明しました。
青い部分ですが、編集のためのプラグインが存在するかどうか確認し
該当のプラグインが存在すれば、TRUEの値を返す部分。
赤い部分は、該当のプラグインを動かす部分。
この do_plugin_action($plugin) 関数の返り値は配列だ。
返り値を格納する $retvals 変数が配列だからだ。
この $retvals 配列は2つのキーを持つ。
1つは「 msg 」というキーで、もう1つは「 body 」というキーだ。
|
さて、編集のプラグインを呼び出し、動かした場合の
do_plugin_action()関数の返り値が、どんな値になるのか見てみる事にした。
まずは do_plugin_action()関数を見てみる。
do_plugin_action()関数
(lib/plugin.php) |
// Call API 'action' of the plugin
function do_plugin_action($name)
{
if (! exist_plugin_action($name)) return array();
if(do_plugin_init($name) === FALSE)
die_message('Plugin init failed: ' . $name);
$retvar = call_user_func('plugin_' . $name . '_action');
// Insert a hidden field, supports idenrtifying text enconding
if (PKWK_ENCODING_HINT != '')
$retvar = preg_replace('/(<form[^>]*>)/', '$1' . "\n" .
'<div><input type="hidden" name="encode_hint" value="' .
PKWK_ENCODING_HINT . '" /></div>', $retvar);
return $retvar;
}
|
赤い部分が該当のプラグインを呼び出す所だ。
青い部分は、赤い部分で得た返り値を、そのままオウム返しのように
do_plugin_action()関数の返り値としているのだ。
|
編集画面の場合、上の赤い部分は、plugin_edit_action()関数になる。
その関数は、 plugin/edit.inc.php にある。
do_plugin_action()関数
(plugin/edit.inc.php) |
function plugin_edit_action()
{
global $vars, $_title_edit, $load_template_func;
if (PKWK_READONLY) die_message('PKWK_READONLY prohibits editing');
$page = isset($vars['page']) ? $vars['page'] : '';
check_editable($page, true, true);
if (isset($vars['preview']) || ($load_template_func amp;amp; isset($vars['template']))) {
return plugin_edit_preview();
} else if (isset($vars['write'])) {
return plugin_edit_write();
} else if (isset($vars['cancel'])) {
return plugin_edit_cancel();
}
$postdata = @join('', get_source($page));
if ($postdata == '') $postdata = auto_template($page);
return array('msg'=>$_title_edit, 'body'=>edit_form($page, $postdata));
}
|
赤い部分を見てみる。
返り値の配列でキーがmsgの部分には、変数 $_title_edit の値が入る。
変数 $_title_edit はグロバール変数だ。
ja.lng.phpのソースの中で代入されている。
$_title_edit = '$1 の編集';
$1の部分は、lib/pukiwiki.phpの中で加工処理のために「$1」にしている。
青い部分は、配列のキーが body の場合の値だ。
edit_form($page, $postdata) の値が入る。
edit_form()関数は lib/html.phpで定義されている関数で、
編集したいページのコンテンツを呼び出し、編集画面の中で表示させるための
HTMLソースを吐き出させる関数だ。
つまり、配列のキーが body の場合、編集画面のHTMLのソースが
格納されるというわけだ。
|
さて、上の事からlib/pukiwiki.phpを見て次の事が言える。
編集画面などを呼び出す仕掛け (一部省略)
(lib/pukiwiki.php) |
/////////////////////////////////////////////////
// Main()
$retvars = array();
(途中省略)
if ($plugin != '') {
if (exist_plugin_action($plugin)) {
// Found and exec
$retvars = do_plugin_action($plugin);
if ($retvars === FALSE) exit; // Done
if ($is_cmd) {
$base = isset($vars['page']) ? $vars['page'] : '';
} else {
$base = isset($vars['refer']) ? $vars['refer'] : '';
}
} else {
// Not found
$msg = 'plugin=' . htmlspecialchars($plugin) .
' is not implemented.';
$retvars = array('msg'=>$msg,'body'=>$msg);
$base = & $defaultpage;
}
}
$title = htmlspecialchars(strip_bracket($base));
$page = make_search($base);
if (isset($retvars['msg']) && $retvars['msg'] != '') {
$title = str_replace('$1', $title, $retvars['msg']);
$page = str_replace('$1', $page, $retvars['msg']);
}
|
赤い部分の do_plugin_action()の返り値は、配列 $retvarsに格納される。
編集画面の呼び出しの場合、キーがmsgの部分には「$1 の編集」の文字列が入り
キーがbodyの部分には、編集画面のHTMLソースが入る
さて、配列 $retvarsのキーがmsgの部分に格納されている文字列は
「$1 の編集」になっている。(編集画面を呼び出す時のみだが)
$1にしている理由だが、答えは青い部分とピンクの部分にある。
それぞれ $1 を置き換えているのだ。つまり置き換える場所の目印だったのだ。
なので、編集画面の場合、<TITLE>のタグの中には「(ページ名)の編集」と
いう文字列が入り、それが表示される仕組みになっている。
|
さて、ブラウザに出力されるコンテンツは、配列 $retvarsの
msg キーの中に格納されているが、それを、どのように処理していくのか
見ていく事にします。
編集画面などを呼び出す仕掛け (一部省略)
(lib/pukiwiki.php) |
/////////////////////////////////////////////////
// Main()
$retvars = array();
(途中省略)
$title = htmlspecialchars(strip_bracket($base));
$page = make_search($base);
if (isset($retvars['msg']) && $retvars['msg'] != '') {
$title = str_replace('$1', $title, $retvars['msg']);
$page = str_replace('$1', $page, $retvars['msg']);
}
if (isset($retvars['body']) && $retvars['body'] != '') {
$body = & $retvars['body'];
} else {
if ($base == '' || ! is_page($base)) {
$base = & $defaultpage;
$title = htmlspecialchars(strip_bracket($base));
$page = make_search($base);
}
$vars['cmd'] = 'read';
$vars['page'] = & $base;
$body = convert_html(get_source($base));
if ($trackback) $body .= tb_get_rdf($base); // Add TrackBack-Ping URI
if ($referer) ref_save($base);
}
// Output
catbody($title, $page, $body);
exit;
|
そして赤い部分の条件文で、条件を満たすため、青い部分に移る。
青い部分は、プラグイン処理などで生成したHTMLソースを格納している
$retvars['body'] を、$body 変数に代入している。
$body変数とは、skin/pukiwiki.skin.php のソース内で、
ブラウザに出力する際に使う変数だ。
そしてピンクは出力のための関数だ。
|
うーん、こんな仕組みだったとは。
Pukiwikiのソースを読みはじめた頃、頭の中が整理されず混乱しながら
解読していたため、lib/pukiwiki.php のソースを何度も目にしているが
こんな仕掛けになっているのには気づかなかった。
ソース読みは難しいなぁと思った。
さて、もう1つの疑問。
出力画面でメニュー部分がある。
|
ブラウザに表示される画面 |
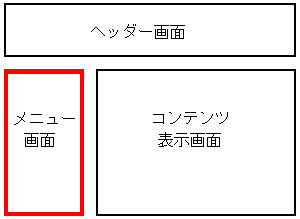 |
メニュー画面だが、編集する場合は、コンテンツ表示画面と同様に、
編集画面を呼び出せば良いのだ。
|
メニュー画面は編集できる |
 |
この事を考えれば、メニューも、ページ画面と同様に
データを取り込んでブラウザに表示させているように思えるのだが、
どうも lib/pukiwiki.php で処理したりする形跡がない。
よく考えれば不思議だ!
と思った。
そこで、skin/pukiwiki.skin.phpのソースを眺めてみる事にした。
すると答えは、そこにあったのだ。
メニュー画面を出力させる場所
(skin/pukiwiki.skin.php) |
<?php if (arg_check('read') && exist_plugin_convert('menu')) { ?>
<table border="0" style="width:100%">
<tr>
<td class="menubar">
<div id="menubar"><?php echo do_plugin_convert('menu') ?></div>
</td>
<td valign="top">
<div id="body"><?php echo $body ?></div>
</td>
</tr>
</table>
<?php } else { ?>
<div id="body"><?php echo $body ?></div>
<?php } ?>
|
赤い部分は、メニュー画面の出力のプラグインの有無を調べている部分。
青い部分は、メニュー画面の HTMLソースを吐き出す部分。
|
上のソースを見て
メニュー画面を出力させるのにプラグインを使っていたのだ!!
まさかメニュー画面を出力させるのに、プラグインを使っているとは
全く想像もつかなかった。
さて、メニュー画面を開くプラグインを見てみる。
最後の返り値の部分に注目する。
メニュー画面を開くプラグイン
(plugin/menu.inc.php) |
|
return preg_replace('/<ul[^>]*>/', '<ul>', convert_html($menutext));
|
赤い部分だが、読み込んだメニューのコンテンツデータの$menutextを
convert_html()関数で加工している。
convert_html()関数とは、既に説明しましたが、コンテンツの中の
プラグインやユーザー定義ルールなどをHTMLに変換する関数だ。
これを見れば、コンテンツ表示画面と何ら変わらない事がわかる。
|
メニュー画面も、コンテンツ画面も、ほとんど同じ方法で
出力しているという事がわかった。
メニュー画面だと、上のソースにあるように、<ul>タグで
CSSが省かれるため、表示の仕方が多少違う事と、見出し部分で、
剣の部分(†)が表示されないといった違いはあるものの、
他の部分は、変わらない。
ソースを読めば、謎が解ける。オープンソースの良さを感じる (^^)V
最後にオマケ
Pukiwikiに関する事を調べる際、googleがあまり役に立たない。
なぜなら、「Pukiwiki」というキーワードをいれて検索すると、
「Pukiwikiで構築したサイト」が出てくるからだ。
その理由は非常に簡単だ。
<TITLE>タグを見れば、Pukiwikiという文字がある。
実際に、Pukiwikiのデフォルト状態でのタイトルバーを見てみる。
|
タイトルバーを見てみる |
 |
Pukiwikiで構築したメモ帳的なサイトの場合、この部分を変更しないで
掲載している方が多いため、googleで「Pukiwiki」というキーワードで
検索しても、肝心の情報のサイトではなく、Puikiwikiで構築したサイトが
出てしまうというわけだ。
そのため、googleがあまり役に立たなかった (^^;;
まとめ
最初は、簡単にまとめて、軽く独自タグの話で終わろうと思いましたが、
どんどん内容が脹れあがってしまいました (^^;;
Pukiwikiはデータベースを使わないため、カスタマイズしない限りは
手軽に導入できるCMSツールと言っても過言ではありません。
しかし、ソースの解読は、決して簡単ではありません。
PHPのプログラムを読み慣れた方だと、簡単と思われるかもしれませんが、
そうでないと、オブジェクトが飛び交うソースを読むのは大変です。
実際、私自身「凄い骨がある」と思いました。
しかし、PHPのソースを解読する練習には、凄く良い教材ではないかと
思ったりします。
Pukiwikiは、ホームページに使うのに良いソフトだと思いました。
多少のPukiwikiの独自タグさえ覚えれば、デザインの自由度が低いため
決まった形に落ち着き、デザインセンスがなくても、
それなりにホームページが作れる利点があります。
ホームページビルダーの場合、デザインの自由度が高い上、
複雑にHTMLのタグを吐き出すため、複数人で使うのには向いていない上
この奮闘記みたいに、タグ打ちの場合は、HTMLのソースの中身が
把握できるメリットがありますが、デザインの自由度は大きいため、
デザインに関しては、プロに任せないと見栄えは綺麗とは言えません。
あとは、PukiwikiをはじめとしたCMSツールの場合、ftpなどを使って
編集したファイルを、アップロードする手間がなくなる良さがあります。
なので、Pukiwikiは便利だと感じました。
次章:「ライブラリの役目と利点」を読む
前章:「iSeriesAccessを活用したODBC経由のAS400(iSeries,i5)とLinuxの連動に挑戦」を読む
システム奮闘記に戻る