システム奮闘記:その14
はじめに 日本語でメール。 普段、何気なく日本語でメールを書いているだけに、深く考えることがなかった。 しかし、ある日、日本語とメールについて考えさせられる事件が起こった!! それは、2001年12月21日、このシステム奮闘記を公開した時だった。 私は、宣伝のため、BLUEのMLに公開のアナウンスを流した。 レベルの高い(高すぎる!)人が多くいるProjectBLUE。 下手なことを書くと、間違いなく突っ込みが来て ブルーになる ← オヤジギャグ (^^;; 今回は、その時、私が誤解していた内容や、ご指摘を頂いた方への返答(?)などを まとめることにしました。 私の誤解していた事、無知だった事を、一挙大公開!! はじまり、はじまり (^^) ← うーん、恥さらしになれてしまった私メールと日本語文字コード
さて、問題になった内容は、システム奮闘記のある記述だった。 まず、姉崎さんからご指摘を受けた。
| 問題の記述 |
|---|
|
メールを送るためには、日本語の文字コードを統一しないといけない。 問題は、お客さんはWindowsでメールを読むため、 EUCコードを使うと文字化けする。 メーラーの文字コードを変更しなくても良いように、 SJISにする必要があった。 |
| 姉崎さんからのご指摘 |
|
Windowsで読もうがLinuxで読もうが、送り主は、 JIS(SJISじゃなく、iso-2022-jp)で送らないといけない、 というのは、死語?>識者殿 |
しかし、この時、私は・・・ JISって何やねん? だった (^^;; この時、日本語コードにJISコードがあることを知らなかった。 私は、UNIX(Linux)はEUCで、WindowsはSJISだけ知っていた。 以前からftp で、WindowsからLinuxへ日本語を含むファイルを転送した時、 文字化けを起こしファイルが読めないため、文字コードをEUCにするため、 nkfコマンドを使って文字コードの変換処理していた。 しかし、JISコードがある事は全く知らなかった!! 続けて、SAMBAの太田さんから、次のようなご指摘を受けた。
| 太田さんのご指摘 |
|---|
|
MUA←→MUA間でシフト化符号表現(だっけ、JISの言い方は)を使う事は、 両者がOKすれば可能でしょう。内部同士の通信に内部コードを使う、 ということですから。 が、internetに向けてそんなことしたら袋叩きですかね。 規約ではないけれど、デファクトスタンダード、でしょうか。 |
私は・・・ MUAって何? だった。己れの無知の度合いが露呈されてしまった (^^;; その後、色々な方からの突っ込みの嵐になってしまった。 もちろん、議論できるほどの知識や技術力は持っていない。 その上、知らない用語が飛び交って、話にすら割り込めず、 MLに流れるメールを読んでは・・・ おいらにゃ、わからへん (--;; という感じで呆然となった。 最後には、投稿者同士で日本語コードを巡って議論になってしまった。 さて、話を戻して、姉崎さんから、ご指摘を受けたので、 私は次のように返答した。
| 私の返答内容 |
|---|
|
開発していた時、Linuxからメールを送りますと、 EUCコードなので、 OutlookExpressで読もうとしますと、 文字化けしてしまいました。 エンコードをやれば問題ないのですが、 エンコードを知らないお客さんが多いのではと思い、 「それだったらSJISで統一しよう」と思いました。 |
なぜ、当時、私がJISでなく、SJISでメールを送ったら良いと思っていたのか。 その理由は・・・ JISコードの存在を知らなかった!! なのだ。 そして、もちろん・・・ メールはJISで送るのが規則である事も知らない!! のだ。 SJISで送ったら良いと思った理由は、WindowsはSJISを使っているためと 以前から、LinuxからWindowsへメールを送っている時 いつもmailコマンドを使う。 mail suga@kaisha.co.jp < file この場合、ファイルの文字コードをEUCで送って、OutlookExpressでメールを読むと、 文字化けが起こって、内容が読めない。 下図のように、OutlookExpressでは、エンコードで文字コードをEUC指定すれば、 EUCで送ったメールでも読めるが、それだと、エンコードを知らない人の場合、 文字化けのままメールが読めない事になる。
| OutlookExpressでエンコードする様子 |
|---|
|
一般の人に、日本語文字コードの違いのわかる人は、ほとんどいない事を考えると ファイルをSJISにして送った方が読めると判断したからだった。 うちのお客さんで、UNIXやLinuxでメールを読む人は、まずいないだろうし (^^;; mail suga@kaisha.co.jp < file 社内に向けて、上の方法でSJISのファイルをメールを送っても内容は エンコード作業をすることなく読めたため、私は、メールをSJISで送ることにしていた。 ただし、Subjectの部分の日本語だけが文字化けを起こしていた。 そのため、姉崎さんへの返答も、そのように書いた。 しかし、即座に後藤さんから、ご指摘を受けた。
| 後藤さんからのご指摘 |
|---|
太田さんが書かれているように、エンドツーエンドの通信でお互いの 合意が取れているのであれば、SJIS でも EUC でも UNICODE や他の ものを使ってもいいでしょう。 ただ、そちらのシステムでどのようなヘッダを付けているのかわかりま せんが、私が菅さんの「お客様」に含まれていた場合にはおそらくは 「そんなもの送ってもらっても読めないよ」となるでしょう。 やはりヘッダに Content-Type: Text/Plain; charset=iso-2022-jp Content-Transfer-Encoding: 7bit として、本文テキストは JIS にしてもらわないと私の場合は困ります。 |
後藤さん以外からも以下のご私的をいただいた。
| (ポ)さんからのご指摘 |
|---|
Mime-Version: 1.0 のへッダーも必要 |
(ポ)さんのご指摘の理由は後述しています。 わかっていない私が下手な事(?)を書くため、ご指摘を受ける。 つまり、泥沼にハマる・・・。 「UNICODE」を見て、日本語文字コードが、他にもある事を知って驚く (@o@) 文章を読むと「どのようなへッダーを付けている」と書かれている。 これを読んで「へッダーって・・・」と目が点になった。 実は、C言語でプログラムを作成しているが、メール送信部分は 東大の渡辺さんの許可を頂いて、丸写しさせてもらった物。 今までへッダーなんて考えた事すらなかった。 もちろん、どこにへッダーをつけて良いのか、わからない。 そこで、どういう風にすれば、へッダーをつけることができるか、 私が組んだプログラムを書いて、後藤さんに返答した。
| 私の返事 |
|---|
実は、ヘッダーはつけていません。 というよりも、どこにヘッダーをつけて良いのは、わからないからです。 メール配信の仕組みですが、プログラムの中で #define SUBJECT "Test Mail" #define ADDRESS "me@mydomain" char command[256]; snprintf( command, sizeof(command), "/usr/bin/mail -s '%s' %s", SUBJECT,ADDRESS ); FILE *pipe = popen( command, "w" ); のプログラムを稼動させて動かしています。 開発した当時(今もですが・・・)、sendmail.defの設定は マニュアルを読めばできますが、詳しい配信方法やシステムまでは 不勉強のため、わからないです。 |
| 後藤さんからのお返事 |
この方法(mail コマンドを使う)だとヘッダをつけるのは難しいかも。 私であれば、C で書く場合はメイルサーバと SMTP で喋るプログラムを 作るんじゃないかなぁ。 または、日本語化した MH など、コマンドラインから使える適当な プログラムを使うとか。 まぁ、perl や ruby でメイル用パッケージを使ったスクリプトを作成し、 それを C のプログラムから呼び出すほうが簡単な気はしますけど。 私は perl や ruby をこのような用途に使ったことはありませんが、 ちゃんとしたヘッが付くようなメイル送信スクリプトを書くことは できるはずです。 |
さてさて、ご指摘を受けた以上は、改善する必要はあるし、 そのためには勉強していく必要がある。 何もしなければ、折角、ご指摘して頂いた方に申し訳がないし、 改善することによって、奮闘記のネタにもなる! さて、集中砲火(?)を受けたぐらいでは、めげない私なのだ。MUAとは何か?
まず、私の始めたのは、太田さんからご指摘を受けた内容の理解からだった。 「MUAって何?」だったので、Linuxの入門書を見てみることにした。 入門書には「ユーザーはメールを読み書きに使うOutlookやEudoraのような プログラムはMUAと呼ばれ、自分が使用可能なSMTPサーバーまでの 配送を担当します」と書かれている。 なるほど、私の場合、OutlookExpressというMUAを使って メールサーバーにメールを渡して、あとは、SMTPが目的先のメールサーバーまで メールを配達してくれる。 MUAという言葉の意味がわかったので、太田さんのご指摘にあった 「MUA←→MUA間でシフト化符号表現(だっけ、JISの言い方は)を使う事は、 両者がOKすれば可能でしょう。内部同士の通信に内部コードを使う、ということですから。 が、internetに向けてそんなことしたら袋叩きですかね。」の意味がわかった!! お互いのメールを読むソフトの間で、読む文字コードを決めてしまえば、 SJISで送っても問題はないが、公のインターネット上で、JISコード以外の 文字コードで送ると、ルール違反という事で、問題が起こるという事だ。
| お互いの合意があれば、JISコード以外でも文字コードは使っても良い |
|---|
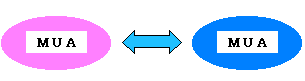 |
閉じたネットワーク内でお互いのMUAで
メールの文字コードがSJISという合意がある場合は
SJISでメールを送っても問題はない
(具体例)i-mode同士のメールのやりとり
絵文字はSJISのため、SJISの文字コードで通信を行なっている
|
しかし、閉じていない公のインターネット上をSJISの文字コードを メールで流すのは規則違反のため、問題が生じる。
| インターネット上でメールをやりとりする場合 SJISで送るのは規則違反のため使えない |
|---|
 |
さて、後藤さんからご指摘のあったメールのへッダー。
そういえば、Linux上から mail -f sugaとやると
私に来たメールの一覧が出てくる。そして該当の番号を選ぶと
メールの内容の前に色々な呪文が出ている。
| メールのへッダー |
|---|
From XXXXXXXXX@jp-k.ne.jp Fri Dec 13 23:05:33 2002
Status: R
>From bin Fri Dec 13 23:05:33 2002
Received: from mgskn06.jp-k.ne.jp (mgskn06.jp-k.ne.jp [210.175.123.28])
by kaisha.co.jp (8.9.X/X.XW) with ESMTP id XAA10517
for <suga@kaisha.co.jp>; Fri, 13 Dec 2002 23:05:33 -0500
From: XXXXXXXXX@jp-k.ne.jp
Received: (from root@localhost)
by mgskn06.jp-k.ne.jp (8.9.2+3.1W/3.7W) id WAA16972
for <suga@kaisha.co.jp>; Fri, 13 Dec 2002 22:11:57 +0900 (JST)
Message-Id: <200212131311.WAA16972@jp-k.ne.jp>
To: suga@kaisha.co.jp
Subject: Message from SkyMail
Date: Fri, 13 Dec 2002 22:11:57 +0900
X-Priority: 3
Reply-To: XXXXXXXXX@jp-k.ne.jp
Errors-To: XXXXXXXXX@jp-k.ne.jp
MIME-Version: 1.0
Content-Type: text/plain; charset="iso-2022-jp"
Content-Transfer-Encoding: 7bit
|
今まで、メールのへッダーを注意深く見たことがなかったけど 後藤さんのご指摘の通り、メールのへッダーには、 文字コードと7ビットで送る呪文が書かれている。 しかし、問題になったシステムのメールは、へッダーはついていない。 後藤さんのような技術を持っておられる方なら、SMTPに喋らせるという技ができる。 しかし、私は、そんな技術を持っていない。 さぁ、どうするということで、プログラムソースをJISに変換して、 それをコンパイルをかけたら良いだろうと、単純に考えた。 実は、SJISで送っていた際も、へッダーで操作などはしていない。 単に、ソースをSJISに変換した後、コンパイルをかけたのだった。 さて、コンパイルをかけると エラーが出た (TT) エラー内容:program.c:490: unterminated character constant エラーが出てコンパイル不可能となれば、手も足も出ない。座礁してしまった。 そして、時間だけが過ぎていった。 そして、ある程度の月日が経ち、日本語文字コードの問題の事など忘れて、 PostgreSQL + PHP のシステム構築に奔走していた。 ある日、関数を調べるため、マンモス本を見ていると mail 関数を発見した。 ふと「これで日本語文字コードを解決できるのでは」と思い出した。 善は急げで、早速、単純なプログラムで実験した。 mail("suga@kaisha.co.jp","テスト","文字コード"); さて、これで送られたメールのへッダーを見てみると
| メールのへッダー |
|---|
From XXXX Sun Aug 11 18:35:22 2002 Date: Sun, 11 Aug 2002 18:35:22 -0400 From: XXXX To: suga@kaisha.co.jp Mime-Version: 1.0 Subject: =?ISO-2022-JP?B?GyRCJCpMZCQkOWckbyQ7GyhC?= Content-Type: text/plain; charset=iso-2022-jp Content-Transfer-Encoding: 7bit |
見事、へッダーがついていた!!
万歳 V(^^)V
だった。
| ちょっと追加 |
|---|
この記事を編集する際、へッダーの中身を外部のマシンから、
うちの会社の私のアドレスに送ってみたら、
Content-Transfer-Encoding: 7bitのへッダーがなかった。
Hotmailから送った場合だった。これでは参考事例にならないと思い、
他の例を探している途中、実は、このへッダーは省略しても良いことを知った。
|
そして、ちょっと追加の上に少し追加しておきます。 親亀の上に子亀。子亀の上に孫亀なのだ。 この上に書いてあることは、正しいのだが、(ポ)さんから、以下のご指摘を受けた。
| (ポ)さんのご指摘 (2003年1月14日追加) |
|---|
これをつけないと文字化けするMUAがあったと思います(何だったか 忘れてしまったのですが、Mac版Outlookか何かだったような気が)。 やはり、つけることをお勧めします。 |
うーん、MUAの関係で、省略はまずいみたい (^^;; hotmailから送った場合、読めないメーラーがあるのは問題かも。 閑話休題。しかし、へッダーの問題は、これで解決ではなかった!! 問題のプログラムはC言語で書かれている。しかし、実験で使ったのはPHP言語。 この場合だと、プログラムをC言語から、PHPへ移植する必要がある。 移植となれば、膨大な時間が必要になる。だが、移植している時間の余裕がない・・・。 後藤さん以外に、なかまさんからも、次のアドバイスを受けていた。
| なかまさんのアドバイス |
|---|
なかまです。 > char command[256]; > snprintf( command, sizeof(command), "/usr/bin/mail -s '%s' %s", SUBJECT, > ADDRESS ); > FILE *pipe = popen( command, "w" ); パイプで呼び出すなら、mailでは無く、sendmail -t に対して # sendmailが面倒ならpostfixでも良いですし、どちらでも動きます。 ----------- ヘッダいろいろ 区切りは改行 ボディいろいろ ----------- # sendmail -t なら、変更点は少ないでしょうし。 で送れば、好きなヘッダーがかけると思いますが。 むかーしのCGIでは良くそうしてました。 # 今は、何使っても、smtp喋るものを使う事が多いかな。 |
しかし、後藤さんのアドバイス(smtpを喋らせる方法)も、 なかまさんのアドバイスの方法も、この奮闘記を編集している時点では、 そこまで知識や技術を知らないため、解決できない状態にいます。 勉強すれば良いのだが、残念ながら、今の私の能力では手に負えないため、 お二人のアドバイスを理解して、生かせるまでには、まだ時間がかかります (--;; 現在の所、問題が起こっていないのが幸いです (--;; とりあえずは、日本語の文字コードの問題の解決の糸口が見えた上、 知らなかった事が出てきて勉強になったと思い、賢くなったと喜んだ (^^) しかし、ここで疑問が残った。
| 私の疑問 | |
|---|---|
| (1) |
複数の日本語文字コードがあるにもかかわらず なぜ、メールをネットで配信する際、JISコードに限定されるのか? |
| (2) |
メールがインターネット上を流れる際、JISコードだから、 JISコードに統一すれば良いのに、SJISやEUCが生き残っているのか |
この2つの疑問を解決しないと、本当の意味で、文字コードの話を理解したとは言えない。 一歩、踏み込まないと、うわべだけの知識になる! というわけで、文字コードに関する本などで調べてみた。 私が思っていたような単純な話ではなかった!! 文字コードの歴史を紐解く必要があった。 コンピューターは、アメリカが発祥の地。アメリカといえば英語! 英語で文章を書くには、アルファベッドと記号だけで事足りる。 1960年代、アメリカでコンピューターの共通の文字コードができた。 それをASCIIコードという。ASCIIが文字コードの基本型になった。 さて、このASCIIコードは7ビットで表現されている。 英語は、128文字あれば表現は十分なので、7ビットで表現することになった。
| 7ビット表現の文字(ASCIIコード) |
|---|
 |
|
(注意!) 上位ビットは「0」だぞ。無視したり、他の目的が入ることはないぞ! という突っ込みが来そうなので、ちょっとコメント。 無視したり、他の目的に利用というのは次の本に書かれていた。 「図解でわかる・文字コードのすべて」(清水 哲郎:日本実業出版者)の P17にある記述だった。 現在は、ASCIIでも最上位ビットは「0」だけど、当時は、他目的だったり 無視したりしていたのかもしれない。詳しいことは不明 (^^;;; |
困ったのは、他の国の言語を使う人達。 日本語の場合、ひらがな、カタカナだけでも、100を越える。 漢字を入れると、5〜6万文字になる。とても7ビットでは表現できない。 そこで、2バイトで文字を表現することになった。 それが、JISコードだった。JISにも、いくつか種類があるが、ここでは省略 (^^;; もちろん、14ビットなので、5〜6万の文字は収録できないが、 日常使う漢字を考えると、十分表現できる範囲だった。 足らない分は、第2水準漢字など、色々な技が考え出されたみたい。 このJISコードが現在でも健在の理由は、メール配信の際に使う文字コードが JISコードというルールがある。 では、なぜ、JISコードなのか。本を読んでいくと、こんなことが書かれていた。 文字はASCIIコードの7ビットを基本にしている。 これを前提に、メール配信のSMTPは、文字を7ビットとして認識して メールを配信するシステムになっている。 そのため、8ビットの文字(EUC、SJISなど)で、メールを送信すると、 後ろの1ビットが切られたりするため、文字化けが起こる。 7ビット配信には、SMTPが英語国民が開発したため、 7ビット配信でも問題がない上、(注意)転送効率を考えると、7ビットの方が良いはず。 そのため、メール配信の際、文字は7ビット表現となった! これが、メールはJISコードで送るルールの根拠になる。 ピピー!! レッドカード! おっと、ホイッスルが鳴った。しかも、レッドカード。 ホイッスルを鳴らしたのは、(ポ)さんだった。
| (ポ)さんのご指摘 |
|---|
|
転送効率というより、過去との整合性です。 TCP/IPの前、UUCPでメール交換されていた時代には、7bitしか通らない モデムとか、結構使われていました。その時代の名残です。 |
実は、姉崎さんからも、イエローカードを頂いていた。
| 私の記述(既に修正済み) |
|---|
|
そこで、2バイトで文字を表現することになった。 (ここでは1バイト=7ビット) |
| 姉崎さんのご指摘 |
|
「ここでは1バイト=7ビット」→ 「1バイト(1オクテット=8ビット)中、下位7ビットだけ使用する」 |
なぜ、私がこんなことを書いたのか。 実は、以下のような誤解をしていたからだった。
| 私の誤解していた内容 |
|---|
 |
というわけで、データは7ビットで送信されるものと思い込んでいました (^^;; さて、そう思い込んでいた原因を書かねば、なぜ、そんな誤解をするのか わからないままになっては、良くないので、原因を書くことにします。 実は、「最新TCP/IPハンドブック」(若林 宏:秀和システム)のP82に 書かれている補足文にあった。
| 本の補足文 |
|---|
|
1バイトの英語のアルファベッドなどは、7ビットですべての 文字を表現できるため、通信効率を挙げるために 通信回線上は1バイトを、7ビットとして送受信する。 一般に、1バイトは8ビットとなるが アルファベッドのみで通信する場合、通信の世界では、 1バイトを7ビットとして考えることがある。 |
この文章を読んで、私は、JISは7ビットで送っているとばかり思い込んでいた。 でも、よく読むと、アルファベッドだけの通信と書いてある (^^;; もっと、文章をよく読まねば・・・。
| ここで、とんでもない誤解を暴露! |
|---|
 |
実は、私はビットの並びは最上位ビットが尻尾に来ると思い込んでいた。 理由は、ビッグエンディアンと、リトルエンディアンの存在だった。 2バイト数字、4バイト数字の時、メモリーに格納される際、 バイトの並びが尻尾から先頭になるにつれ小さくなる並びがリトルエンディアンと呼ばれる。 私は、ビットの並びも尻尾が最上位になるとばかり思い込んでいた!! なぜ、そんな思い込みをしていたのか。なぜ、2つのエンディアンを知っていたのか。 学生時代、一応、宇宙線研究室にいて、観測データ─の解析を行なった。 データの観測はパソコンで採取し、解析はUNIX。データはバイナリーのため、 リトルエンディアンからビッグエンディアンに変換する必要があった。 院生の先輩から、変換には、これを使ったら良いという事で、以下のコードをもらった。 short swap2(short dd){ return(((dd & 0xff00)>>8)|((dd & 0x00ff)<<8)); } unsigned short uns_swap2(unsigned short dd){ return(((dd & 0xff00)>>8)|((dd & 0x00ff)<<8)); } unsigned int swap4(unsigned int dd){ return( ((dd & 0xff000000)>>24) | ((dd & 0x00ff0000)>>8) | ((dd & 0x0000ff00)<<8) | ((dd & 0x000000ff)<<24) ); } 当時、全然、わかっていない私が、これを見て、ビット演算子「>>」を見て、 ビットを移動させて、ビットを逆転していると思い込んだ。 |
さて、私がお客さん向けに送っているメールは、SJISで送っているため、 明らかにルール違反になる。でも、トラブルが起こっていない。その理由は、 現在では、8ビット文字に対応しているSMTP拡張版のESMTPが世に出て、 8ビット文字でメールを送っても、文字化けすることがなくなったためである。 しかし、今も旧・SMTPのサーバーが残っているため、JISコードで送るのが無難になっている。 ピピー!! イエローカード! また、ホイッスルが鳴った。 ホイッスルを鳴らしたのは、(ポ)さんだった。
| (ポ)さんのご指摘 |
|---|
結論から先に言うと、不特定なMTA/MUAとの送受信で8bitを使うのは、 やっぱりお勧めできません。 ESMTPの8bitMIME (RFC1652) は、実は、単純に8bitを通すだけでは ありません。話はずっと複雑です。世の中にいい加減な実装が多いので 「たまたま」通ってしまうことが多いのですが、通らなかったり誤動作 したりする可能性がないとは言えませんし、それでトラブルが出た場合の 対応は、かなーり大変です。 |
うーん、(ポ)さん曰く、いい加減な実装をしているMTAが多いため、
たまたま8ビットのSJISのメールが送れたからと言って
安心とは言えないようだ。この世界は難しい・・・ (^^;;
なにはともあれ、一つ目の疑問が解けた V(^^)V
2つ目の疑問。なぜ、複数の文字コードが存在するのか。
JISに統一すれば便利なのにと思う。
しかし、本を読んでいくと、素人が考えるほど、簡単な問題ではなかった。
本を読む前は、MSがUNIXに対抗して勝手に作った文字コードという認識があった。
しかし、それも間違いだということが、わかった。
SJISができた背景。本を読んでいくと、こんなことがわかった。
JISコードで、1バイト文字と2バイト文字との区別をする際、
エスケープ・シーケンス文字という3バイトで構成された目印を入れる。
これにより、次の文字が1バイト文字(半角のアルファベットなど)や
2バイト文字(平仮名、漢字など)とを区別する。
| JISコードの場合、1バイト文字と2バイト文字の区別の方法 エスケープ・シーケンスの利用例 |
|---|
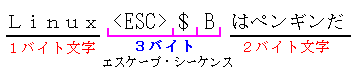 |
|
エスケープ・シーケンスは上の1種類だけでなく 次の文字がASCIIか半角カナなどの、いくつかの種類の目印がある |
単に文字を表示する際や、伝送する場合は、順番ずつなので、JISコードでも 問題は起こらない。 しかし、OSの内部で文字を処理する際、検索、削除などを行なうことがある。 JISの場合だと、処理する文字が、1バイト文字か、2バイト文字か判別する度に、 エスケープ・シーケンス文字の存在の確認をしないといけなくなる。 これは、文字の処理を面倒な物にしてしまう。 そこで、MS、アスキー、三菱電機、日本IBMが協力して、文字コードを開発。 1バイト文字と2バイト文字を簡単に見分けがつくように開発された 8ビット表現の文字コードを、SJISとつけられた。
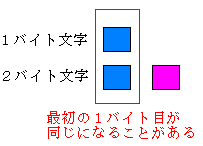
| ビット数以外のJISとSJISとの違い! | |
|---|---|
| JISの場合 | SJISの場合 |
 |
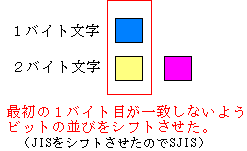 |
| 1バイト目が同じケースがあるため、 区別するのに、エスケープ・シーケンスという 目印が必要になってくる。 |
1バイト目が同じになることがないので、 エスケープ・シーケンスを使う必要がなくなる。 そのため、文字の扱いが楽になる。 |
SJISは「シフトJIS」という意味。 上手に、JISコードの文字の並びやビットの並びを「シフト」させている。 どう巧妙なのか図で表す 姉崎さんから「どうシフトさせているから1バイト文字と一致しないかの説明が あるといいかもしれない。」というアドバイスを頂いたので、 その巧妙ぶりを図で表すことにするが、その前に、少し説明をせねば。
| JIS C 6220のビットと文字との対応関係 |
|---|
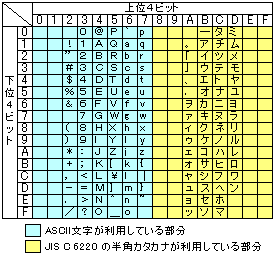 |
JIS C 6220とは、7ビットのASCII文字で、残り1ビットを使って 半角カナを使えるようにした文字コードの一種。 この表を頭に入れて頂いて、SJISの表を出すと
| ASCIIコードとSJISの1バイト目の表 |
|---|
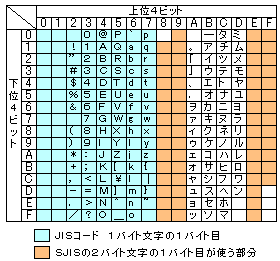 |
SJISの1バイト目は、ASCIIで使われる部分と、JIS C 6220の半角カナの部分の 隙間を上手に活用している。 そのため、1バイト目を見た時に、1バイト文字か、2バイト文字かの区別ができる。 メチャクチャうまい方法だなぁと感心してしまう。 1バイト文字と、2バイト文字の1バイト目が区別できると書いたが、 上の表を見ると、場合わけを考えてしまうが、実は単純だったのに気が付く。 1バイト文字の1バイト目の最上位ビットは「0」になるが、 SJISの1バイト目(2バイト目も)の最上位ビットは「1」になる。 最上位ビットさえ見れば、区別は簡単になる! EUCは、UNIX(Linux)のOS内部処理で使われる文字コード。 JISコードを使わないのは、SJISができたのと同じ理由で、 1バイト文字と2バイト文字の認識が簡単にできるように開発された。 ちなみに、この奮闘記は emacs で編集されているため、EUCコード。 これで、2つ目の疑問が解けた V(^^)V 本を読むまで知らなかった事があった。システム外字だった。 社内文書などでも結構、使う。
| システム外字の例 |
|---|
 |
以前、知人に「(株)」の外字を使ってメールを送ったら、
うちのシステムだと読めないという返事をもらった。
なぜだろうかと思ったが、気にせずに過ごしていた。
しかし、本を読んで、Windows環境でしか使えない文字だというのがわかり、
相手がMacを使っている場合や、UNIXでメールを読んでいる場合は、
文字化けを起してしまう。
ついつい使ってしまいそうだが、注意せねばと思った (^^;;
しかし、本の内容を疑ってみた!
本の著者には失礼(?)だが、本当に、Windows以外では読めないかというと
そうでない場合もある。
携帯のメールだった。少なくとも、私の使っているJフォンと、
私の親が使っているドコモでは、上のシステム外字はキチンと表示された。
なぜ? しかし、深く追求するほどの知識がないので断念・・・。
システム外字を送ってはいけないのなら、難しい漢字を送った場合は
どうなるのだろうかと考えてみた。
そこで、かつての中国の最高実力者で、中国の改革開放の陣頭指揮をとった人物の
名前をメールで送れるかどうかやってみた。
Jフォンでは、文字化けするどころか、文字が消えていた。
後ろの「小平」だけが表示されていた。
| こんな有名人の漢字がメールで送れない!! |
|---|
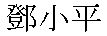 |
後で、この文字を調べてみると、IBM拡張文字と呼ばれる漢字で、
Windows上でしか読めないことがわかった。
なぜ、この漢字が思いついたか。
半年以上前、某所で中国ネタのホームページを編集していた時だった。
いつもなら emacsで編集し、cannaで漢字変換しているが、さすがに、この字は
漢字変換できないと思い、WindowsにあるIMEの手書き検索機能で漢字を拾った。
そして、テキストファイルをLinuxへ持っていき、EUCコードに変換した所、
肝心の漢字が文字化けしていた事がある。
そこで、SJISでしか表せない漢字だと、多分、文字化けするという直感が働き、
実験したら、やはり文字化けを起こした。
調べると、IBM拡張文字と呼ばれる特殊な漢字だったので、納得した。
さてさて、JISコード。本を読むと、色々、種類がある。
半角カナが追加した「JIS C 6220」もあれば、「JIS X 0208-1983」もある。
JISが進化していったため、進化の過程でできた物だ。
メールのへッダーを見ているとISO-2022-JPと書かれている。
これもJISコードの種類の一つだと思ったので、本をじっくり読むと、
次のようなことが書かれていた。
ISO-2022-JPで規定されているエスケープ・シーケンスの表だった。
ということは、規定されているだけの種類の文字が使えることになる
| ISO-2022-JPで使える文字の種類< | |
|---|---|
| 文字の種類 | どういう種類の文字か |
| ASCII | ASCIIコード |
| JISローマ字 | JISで決められたローマ字。ASCIIと違って「\」が「¥」だったりする。 日本の事情に合わせたローマ字という感じ |
| JIS C 6226-1978 | 最初のJIS漢字規格 |
| JIS X 0208-1983 | 1983年に改正や追加されたJIS漢字 |
JISといっても、色々、あるのだなぁと思った。
メールの場合は、3種類のJISと、ASCIIコードの合計4種類の文字が使える。
単に、JISコードと言っても、一言では表せない奥の深さを感じるかなぁ〜。
この辺で終わりかなぁという感じだが、(ポ)さんから次の要請が来ていた。
| (ポ)さんからの要請 |
|---|
|
> やはりヘッダに > Content-Type: Text/Plain; charset=iso-2022-jp > Content-Transfer-Encoding: 7bit > として、本文テキストは JIS にしてもらわないと私の場合は困ります。 Mime-Version: 1.0 もつけて下さい。お願いします。 |
Mime-Version: 1.0って、何だろう?
気になる。気になる。どーしても気になるのらー!!
しかし、本には詳しく載っていなかったので、ネットを探しまくった。
| ネットに載っていた内容の要約 |
|---|
|
メールは7ビットのASCIIコードで送るのを前提していている。 日本語で送る場合、仕組みの拡張としてMIME方式があり 日本語の場合、MIME名iso-2022-jp(JIS)と呼ばれる |
「Mime-Version: 1.0」は、日本語をメールで送る際の呪文なのではと思った。
他のサイトなども見ると、メールはASCIIで送るのが前提のため、
日本語で送る際は、MIMEという呪文を唱える必要がるようだ。
(後でわかった話。日本語に限らずASCII以外で送る時に必要な呪文だった)
さてさて、へッダーと説明文を照らし合わせてみると
へッダーの解説が載っていた。
| メールのへッダーを良く見ると |
|---|
|
Mime-Version: 1.0 Subject: =?ISO-2022-JP?B?GyRCJCpMZCQkOWckbyQ7GyhC?= Content-Type: text/plain; ← データのタイプ。ここではテキストファイル charset=iso-2022-jp ← 文字コード。ここではISO-2022-JPを使っている Content-Transfer-Encoding: 7bit ←エンコードの種類。ここでは7ビットのJISなので、何もしていない。 |
普通にテキスト文で送った場合は、上のようなへッダーになる事がわかった。 後藤さんにへッダーを入れないとダメと、ご指摘を受けた時は、 へッダーの意味は知らなかった。 ここで、ようやく「なるほどなぁ」と納得ができた。 テキスト以外にも、よく添付ファイルをつけてメールを送ることがある。 この場合は、どうなるのか興味深々なので、へッダーを見ることにした。
| 添付ファイル付きメールのへッダー |
|---|
MIME-Version: 1.0 Content-Type: multipart/mixed; ← データのタイプ。ここでは複数の種類があるという意味 boundary="----=_NextPart_000_0007_01C2BBB9.0FE7F980" ← 境界文字列。 X-Priority: 3 X-MSMail-Priority: Normal X-Mailer: Microsoft Outlook Express 5.50.4807.1700 X-MimeOLE: Produced By Microsoft MimeOLE V5.50.4807.1700 This is a multi-part message in MIME format. X-MimeOLE: Produced By Microsoft MimeOLE V5.50.4807.1700 This is a multi-part message in MIME format. ------=_NextPart_000_0007_01C2BBB9.0FE7F980 ← へッダーとの境界線 Content-Type: text/plain; ← データのタイプ。ここではテキストファイル charset=iso-2022-jp ← 文字コード。ここではISO-2022-JPを使っている Content-Transfer-Encoding: 7bit ←エンコードの種類。 ここでは7ビットのJISなので、何もしていない。 テストで送る ------=_NextPart_000_0007_01C2BBB9.0FE7F980 ← テキストとの境界線 Content-Type: application/vnd.ms-excel; ← データのタイプ。ここではMS-Excel name="testcase.xls" Content-Transfer-Encoding: base64←エンコードの種類。 ここではBASE64という方式でデータを符合化している。 Content-Disposition: attachment; filename="testcase.xls" 0M8R4KGxGuEAAAAAAAAAAAAAAAAAAAAAPgADAP7/CQAGAAAAAAAAAAAAAAABAAAAGQAAAAAAAAAA EAAA/v///wAAAAD+////AAAAABgAAAD///////////////////////////////////////////// (このまま続く) |
わかったように「BASE64という方式で符合化」と書いているが、 実は「BASE64って何?」だった。 さて、本を読んでみると、テキスト化する方法のことのようだった。 バイナリーのままでは、メールが送れないため、アルファベット記号の64文字で 表現する形に変換して送るという技を使っている。 ここまで辿り着くのに・・・ 1年かかってしまった!!! しかし、カタツムリでも、前進すれば、それだけでも進歩 (^^) 2001年12月21日のメールのやりとりで、私は内容が理解できず呆然としたが、 今、振り返って読みなおすと「なるほどなぁ」と思うようになった。 あとは、後藤さん、なかまさんの助言を理解して、使いこなせるように 勉強しないとと思う今日この頃です。
まとめ まず、メールには3つのへッダーを必ずつけること Mime-Version: 1.0 Content-Type: text/plain; charset=iso-2022-jp Content-Transfer-Encoding: 7bit 第2に、文字コードは、JISコードで送ること! 最後に、外字やマニアックなくらい難しい漢字は、JISコードにない場合があるので、 使わないのが無難! 意外と簡単にまとまった。大事な点は3つなのに、ここに辿り着くのに ホントに長かった (^^;; 2001年12月21日、色々、ご指摘してくださった方に感謝致します m(--)m そして、2003年1月4日に、この奮闘記を公開した時、 ご指摘してくださった方にも、感謝致します m(--)m
最後に、ちょっと蛇足 21世紀半ば、地球人類は統一文字コードの開発に成功。 複数の文字コードの存在に悩むことなく、平和にシステム開発が進んだ。 しかし、西暦2200年、外的要因から文字コードの危機が起こった。 それは、地球征服を企む、デスラー総統率いるガミラスの存在だった。
| ヤマトとデスラーとのやりとり | |
|---|---|
| 名前 | 台詞 |
| デスラー | フフフ、ヤマトの諸君 我々が送った電子書簡を見たかね? |
| 古代 | そんな物、届いていない。どういう事だ、デスラー! |
| 真田 | 待て、古代。デスラーよ。 お前が送った電子書簡は届いている。 しかし、文字コードの違いから文字化けを起こし 内容は読めなかった。 |
| デスラー | フフフ、我がデスラーコードの変換すらできない 地球人類どもめ。 この大ガミラスに勝てるとでも思っているのか。 地球が我が大ガミラスの支配下になった時は デスラーコードを使うことだな! |
しかし、デスラーの思惑とは裏腹に、ヤマトに破れることになる。 そして、地球は、デスラーコードの支配から免れることになった。 というところで、おしまい、おしまい (^^)